 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Voice Behind the Words: Quantifying Intersectional Bias in SpeechLLMs
Mar 15, 2026Speech Large Language Models (SpeechLLMs) process spoken input directly, retaining cues such as accent and perceived gender that were previously removed in cascaded pipelines. This introduces speaker identity dependent variation in responses. We present a large-scale intersectional evaluation of accent and gender bias in three SpeechLLMs using 2,880 controlled interactions across six English accents and two gender presentations, keeping linguistic content constant through voice cloning. Using pointwise LLM-judge ratings, pairwise comparisons, and Best-Worst Scaling with human validation, we detect consistent disparities. Eastern European-accented speech receives lower helpfulness scores, particularly for female-presenting voices. The bias is implicit: responses remain polite but differ in helpfulness. While LLM judges capture the directional trend of these biases, human evaluators exhibit significantly higher sensitivity, uncovering sharper intersectional disparities.
PromptHelper: A Prompt Recommender System for Encouraging Creativity in AI Chatbot Interactions
Jan 22, 2026Prompting is central to interaction with AI systems, yet many users struggle to explore alternative directions, articulate creative intent, or understand how variations in prompts shape model outputs. We introduce prompt recommender systems (PRS) as an interaction approach that supports exploration, suggesting contextually relevant follow-up prompts. We present PromptHelper, a PRS prototype integrated into an AI chatbot that surfaces semantically diverse prompt suggestions while users work on real writing tasks. We evaluate PromptHelper in a 2x2 fully within-subjects study (N=32) across creative and academic writing tasks. Results show that PromptHelper significantly increases users' perceived exploration and expressiveness without increasing cognitive workload. Qualitative findings illustrate how prompt recommendations help users branch into new directions, overcome uncertainty about what to ask next, and better articulate their intent. We discuss implications for designing AI interfaces that scaffold exploratory interaction while preserving user agency, and release open-source resources to support research on prompt recommendation.
DisastQA: A Comprehensive Benchmark for Evaluating Question Answering in Disaster Management
Jan 07, 2026Accurate question answering (QA) in disaster management requires reasoning over uncertain and conflicting information, a setting poorly captured by existing benchmarks built on clean evidence. We introduce DisastQA, a large-scale benchmark of 3,000 rigorously verified questions (2,000 multiple-choice and 1,000 open-ended) spanning eight disaster types. The benchmark is constructed via a human-LLM collaboration pipeline with stratified sampling to ensure balanced coverage. Models are evaluated under varying evidence conditions, from closed-book to noisy evidence integration, enabling separation of internal knowledge from reasoning under imperfect information. For open-ended QA, we propose a human-verified keypoint-based evaluation protocol emphasizing factual completeness over verbosity. Experiments with 20 models reveal substantial divergences from general-purpose leaderboards such as MMLU-Pro. While recent open-weight models approach proprietary systems in clean settings, performance degrades sharply under realistic noise, exposing critical reliability gaps for disaster response. All code, data, and evaluation resources are available at https://github.com/TamuChen18/DisastQA_open.
Solving Semi-Supervised Few-Shot Learning from an Auto-Annotation Perspective
Dec 11, 2025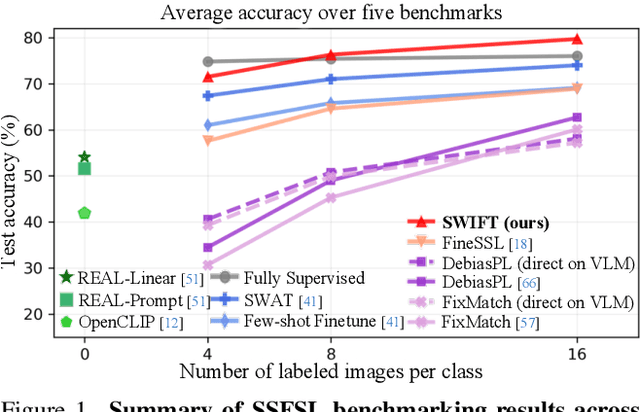
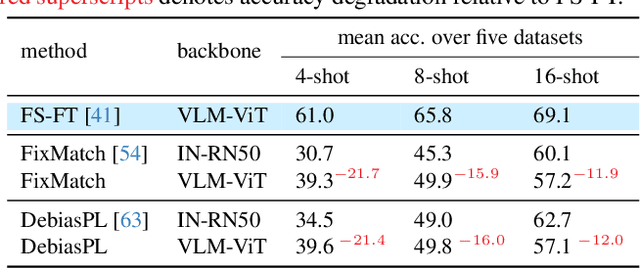
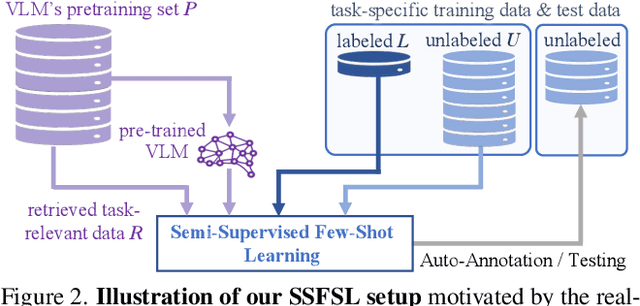
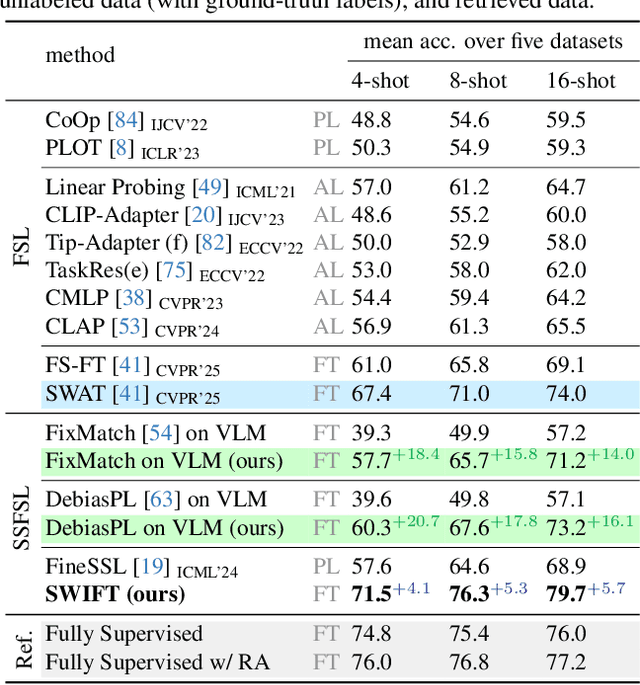
Semi-supervised few-shot learning (SSFSL) formulates real-world applications like ''auto-annotation'', as it aims to learn a model over a few labeled and abundant unlabeled examples to annotate the unlabeled ones. Despite the availability of powerful open-source Vision-Language Models (VLMs) and their pretraining data, the SSFSL literature largely neglects these open-source resources. In contrast, the related area few-shot learning (FSL) has already exploited them to boost performance. Arguably, to achieve auto-annotation in the real world, SSFSL should leverage such open-source resources. To this end, we start by applying established SSL methods to finetune a VLM. Counterintuitively, they significantly underperform FSL baselines. Our in-depth analysis reveals the root cause: VLMs produce rather ''flat'' distributions of softmax probabilities. This results in zero utilization of unlabeled data and weak supervision signals. We address this issue with embarrassingly simple techniques: classifier initialization and temperature tuning. They jointly increase the confidence scores of pseudo-labels, improving the utilization rate of unlabeled data, and strengthening supervision signals. Building on this, we propose: Stage-Wise Finetuning with Temperature Tuning (SWIFT), which enables existing SSL methods to effectively finetune a VLM on limited labeled data, abundant unlabeled data, and task-relevant but noisy data retrieved from the VLM's pretraining set. Extensive experiments on five SSFSL benchmarks show that SWIFT outperforms recent FSL and SSL methods by $\sim$5 accuracy points. SWIFT even rivals supervised learning, which finetunes VLMs with the unlabeled data being labeled with ground truth!
Surely Large Multimodal Models (Don't) Excel in Visual Species Recognition?
Dec 10, 2025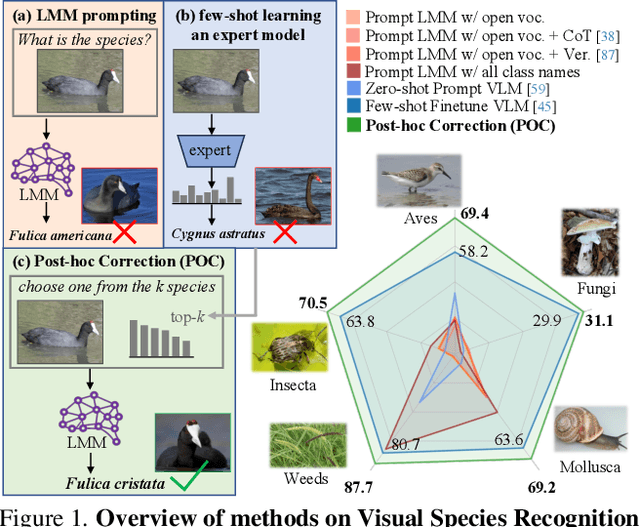
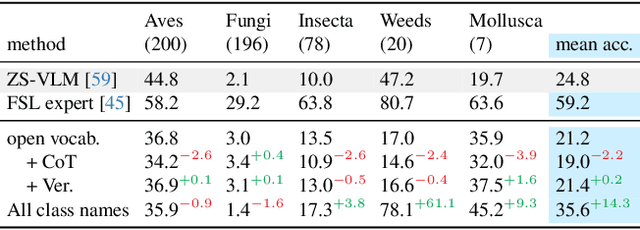

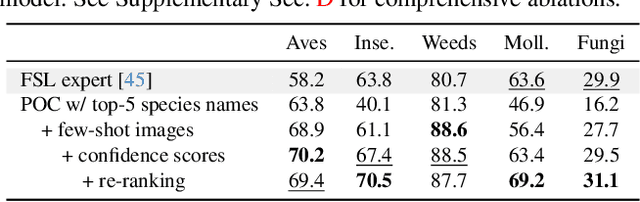
Visual Species Recognition (VSR) is pivotal to biodiversity assessment and conservation, evolution research, and ecology and ecosystem management. Training a machine-learned model for VSR typically requires vast amounts of annotated images. Yet, species-level annotation demands domain expertise, making it realistic for domain experts to annotate only a few examples. These limited labeled data motivate training an ''expert'' model via few-shot learning (FSL). Meanwhile, advanced Large Multimodal Models (LMMs) have demonstrated prominent performance on general recognition tasks. It is straightforward to ask whether LMMs excel in the highly specialized VSR task and whether they outshine FSL expert models. Somewhat surprisingly, we find that LMMs struggle in this task, despite using various established prompting techniques. LMMs even significantly underperform FSL expert models, which are as simple as finetuning a pretrained visual encoder on the few-shot images. However, our in-depth analysis reveals that LMMs can effectively post-hoc correct the expert models' incorrect predictions. Briefly, given a test image, when prompted with the top predictions from an FSL expert model, LMMs can recover the ground-truth label. Building on this insight, we derive a simple method called Post-hoc Correction (POC), which prompts an LMM to re-rank the expert model's top predictions using enriched prompts that include softmax confidence scores and few-shot visual examples. Across five challenging VSR benchmarks, POC outperforms prior art of FSL by +6.4% in accuracy without extra training, validation, or manual intervention. Importantly, POC generalizes to different pretrained backbones and LMMs, serving as a plug-and-play module to significantly enhance existing FSL methods.
BI-DCGAN: A Theoretically Grounded Bayesian Framework for Efficient and Diverse GANs
Oct 30, 2025Generative Adversarial Networks (GANs) are proficient at generating synthetic data but continue to suffer from mode collapse, where the generator produces a narrow range of outputs that fool the discriminator but fail to capture the full data distribution. This limitation is particularly problematic, as generative models are increasingly deployed in real-world applications that demand both diversity and uncertainty awareness. In response, we introduce BI-DCGAN, a Bayesian extension of DCGAN that incorporates model uncertainty into the generative process while maintaining computational efficiency. BI-DCGAN integrates Bayes by Backprop to learn a distribution over network weights and employs mean-field variational inference to efficiently approximate the posterior distribution during GAN training. We establishes the first theoretical proof, based on covariance matrix analysis, that Bayesian modeling enhances sample diversity in GANs. We validate this theoretical result through extensive experiments on standard generative benchmarks, demonstrating that BI-DCGAN produces more diverse and robust outputs than conventional DCGANs, while maintaining training efficiency. These findings position BI-DCGAN as a scalable and timely solution for applications where both diversity and uncertainty are critical, and where modern alternatives like diffusion models remain too resource-intensive.
CHOIR: Collaborative Harmonization fOr Inference Robustness
Oct 26, 2025

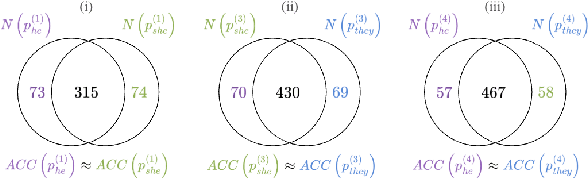

Persona-assigned Large Language Models (LLMs) can adopt diverse roles, enabling personalized and context-aware reasoning. However, even minor demographic perturbations in personas, such as simple pronoun changes, can alter reasoning trajectories, leading to divergent sets of correct answers. Instead of treating these variations as biases to be mitigated, we explore their potential as a constructive resource to improve reasoning robustness. We propose CHOIR (Collaborative Harmonization fOr Inference Robustness), a test-time framework that harmonizes multiple persona-conditioned reasoning signals into a unified prediction. CHOIR orchestrates a collaborative decoding process among counterfactual personas, dynamically balancing agreement and divergence in their reasoning paths. Experiments on various reasoning benchmarks demonstrate that CHOIR consistently enhances performance across demographics, model architectures, scales, and tasks - without additional training. Improvements reach up to 26.4% for individual demographic groups and 19.2% on average across five demographics. It remains effective even when base personas are suboptimal. By reframing persona variation as a constructive signal, CHOIR provides a scalable and generalizable approach to more reliable LLM reasoning.
Curriculum Reinforcement Learning from Easy to Hard Tasks Improves LLM Reasoning
Jun 07, 2025We aim to improve the reasoning capabilities of language models via reinforcement learning (RL). Recent RL post-trained models like DeepSeek-R1 have demonstrated reasoning abilities on mathematical and coding tasks. However, prior studies suggest that using RL alone to improve reasoning on inherently difficult tasks is less effective. Here, we draw inspiration from curriculum learning and propose to schedule tasks from easy to hard (E2H), allowing LLMs to build reasoning skills gradually. Our method is termed E2H Reasoner. Empirically, we observe that, although easy tasks are important initially, fading them out through appropriate scheduling is essential in preventing overfitting. Theoretically, we establish convergence guarantees for E2H Reasoner within an approximate policy iteration framework. We derive finite-sample complexity bounds and show that when tasks are appropriately decomposed and conditioned, learning through curriculum stages requires fewer total samples than direct learning. Experiments across multiple domains show that E2H Reasoner significantly improves the reasoning ability of small LLMs (1.5B to 3B), which otherwise struggle when trained with vanilla RL alone, highlighting the effectiveness of our method.
DisastIR: A Comprehensive Information Retrieval Benchmark for Disaster Management
May 20, 2025
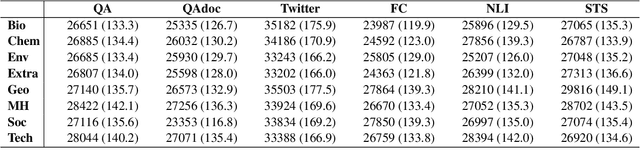


Effective disaster management requires timely access to accurate and contextually relevant information. Existing Information Retrieval (IR) benchmarks, however, focus primarily on general or specialized domains, such as medicine or finance, neglecting the unique linguistic complexity and diverse information needs encountered in disaster management scenarios. To bridge this gap, we introduce DisastIR, the first comprehensive IR evaluation benchmark specifically tailored for disaster management. DisastIR comprises 9,600 diverse user queries and more than 1.3 million labeled query-passage pairs, covering 48 distinct retrieval tasks derived from six search intents and eight general disaster categories that include 301 specific event types. Our evaluations of 30 state-of-the-art retrieval models demonstrate significant performance variances across tasks, with no single model excelling universally. Furthermore, comparative analyses reveal significant performance gaps between general-domain and disaster management-specific tasks, highlighting the necessity of disaster management-specific benchmarks for guiding IR model selection to support effective decision-making in disaster management scenarios. All source codes and DisastIR are available at https://github.com/KaiYin97/Disaster_IR.
Masculine Defaults via Gendered Discourse in Podcasts and Large Language Models
Apr 15, 2025Masculine defaults are widely recognized as a significant type of gender bias, but they are often unseen as they are under-researched. Masculine defaults involve three key parts: (i) the cultural context, (ii) the masculine characteristics or behaviors, and (iii) the reward for, or simply acceptance of, those masculine characteristics or behaviors. In this work, we study discourse-based masculine defaults, and propose a twofold framework for (i) the large-scale discovery and analysis of gendered discourse words in spoken content via our Gendered Discourse Correlation Framework (GDCF); and (ii) the measurement of the gender bias associated with these gendered discourse words in LLMs via our Discourse Word-Embedding Association Test (D-WEAT). We focus our study on podcasts, a popular and growing form of social media, analyzing 15,117 podcast episodes. We analyze correlations between gender and discourse words -- discovered via LDA and BERTopic -- to automatically form gendered discourse word lists. We then study the prevalence of these gendered discourse words in domain-specific contexts, and find that gendered discourse-based masculine defaults exist in the domains of business, technology/politics, and video games. Next, we study the representation of these gendered discourse words from a state-of-the-art LLM embedding model from OpenAI, and find that the masculine discourse words have a more stable and robust representation than the feminine discourse words, which may result in better system performance on downstream tasks for men. Hence, men are rewarded for their discourse patterns with better system performance by one of the state-of-the-art language models -- and this embedding disparity is a representational harm and a masculine default.