 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum Reinforcement Learning from Easy to Hard Tasks Improves LLM Reasoning
Jun 07, 2025We aim to improve the reasoning capabilities of language models via reinforcement learning (RL). Recent RL post-trained models like DeepSeek-R1 have demonstrated reasoning abilities on mathematical and coding tasks. However, prior studies suggest that using RL alone to improve reasoning on inherently difficult tasks is less effective. Here, we draw inspiration from curriculum learning and propose to schedule tasks from easy to hard (E2H), allowing LLMs to build reasoning skills gradually. Our method is termed E2H Reasoner. Empirically, we observe that, although easy tasks are important initially, fading them out through appropriate scheduling is essential in preventing overfitting. Theoretically, we establish convergence guarantees for E2H Reasoner within an approximate policy iteration framework. We derive finite-sample complexity bounds and show that when tasks are appropriately decomposed and conditioned, learning through curriculum stages requires fewer total samples than direct learning. Experiments across multiple domains show that E2H Reasoner significantly improves the reasoning ability of small LLMs (1.5B to 3B), which otherwise struggle when trained with vanilla RL alone, highlighting the effectiveness of our method.
Complex LLM Planning via Automated Heuristics Discovery
Feb 26, 2025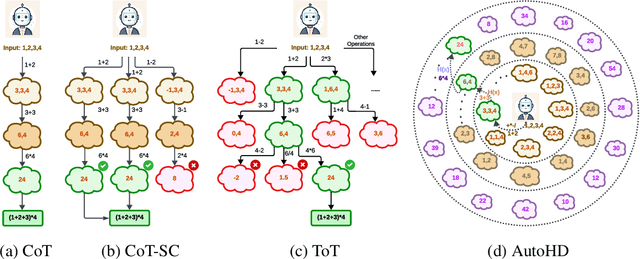



We consider enhancing large language models (LLMs) for complex planning tasks. While existing methods allow LLMs to explore intermediate steps to make plans, they either depend on unreliable self-verification or external verifiers to evaluate these steps, which demand significant data and computations. Here, we propose automated heuristics discovery (AutoHD), a novel approach that enables LLMs to explicitly generate heuristic functions to guide inference-time search, allowing accurate evaluation of intermediate states. These heuristic functions are further refined through a heuristic evolution process, improving their robustness and effectiveness. Our proposed method requires no additional model training or fine-tuning, and the explicit definition of heuristic functions generated by the LLMs provides interpretability and insights into the reasoning process. Extensive experiments across diverse benchmarks demonstrate significant gains over multiple baselines, including nearly twice the accuracy on some datasets, establishing our approach as a reliable and interpretable solution for complex planning tasks.
Inference-Time Computations for LLM Reasoning and Planning: A Benchmark and Insights
Feb 18, 2025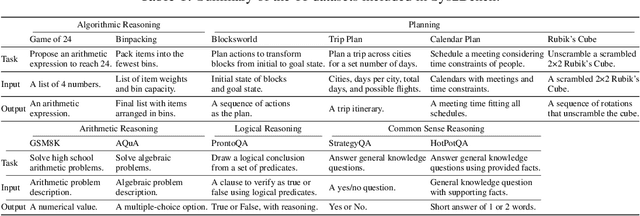

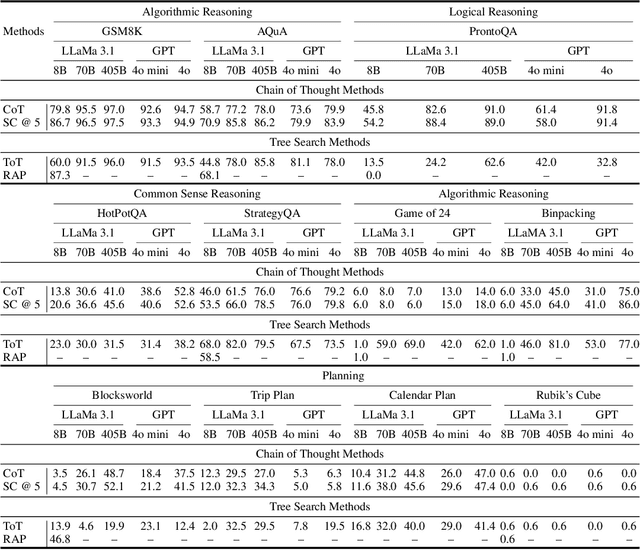

We examine the reasoning and planning capabilities of large language models (LLMs) in solving complex tasks. Recent advances in inference-time techniques demonstrate the potential to enhance LLM reasoning without additional training by exploring intermediate steps during inference. Notably, OpenAI's o1 model shows promising performance through its novel use of multi-step reasoning and verification. Here, we explore how scaling inference-time techniques can improve reasoning and planning, focusing on understanding the tradeoff between computational cost and performance. To this end, we construct a comprehensive benchmark, known as Sys2Bench, and perform extensive experiments evaluating existing inference-time techniques on eleven diverse tasks across five categories, including arithmetic reasoning, logical reasoning, common sense reasoning, algorithmic reasoning, and planning. Our findings indicate that simply scaling inference-time computation has limitations, as no single inference-time technique consistently performs well across all reasoning and planning tasks.
Few-Shot Recognition via Stage-Wise Augmented Finetuning
Jun 17, 2024

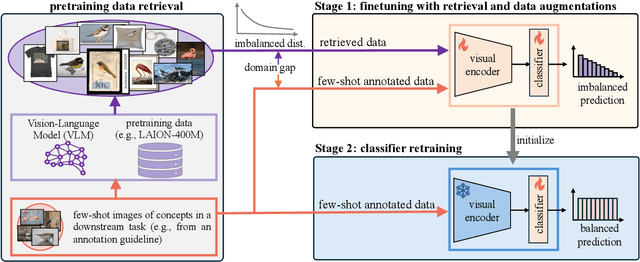
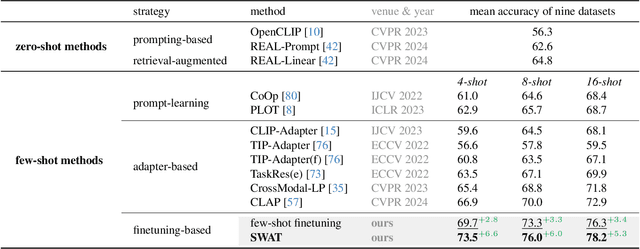
Few-shot recognition aims to train a classification model with only a few labeled examples of pre-defined concepts, where annotation can be costly in a downstream task. In another related research area, zero-shot recognition, which assumes no access to any downstream-task data, has been greatly advanced by using pretrained Vision-Language Models (VLMs). In this area, retrieval-augmented learning (RAL) effectively boosts zero-shot accuracy by retrieving and learning from external data relevant to downstream concepts. Motivated by these advancements, our work explores RAL for few-shot recognition. While seemingly straightforward despite being under-explored in the literature (till now!), we present novel challenges and opportunities for applying RAL for few-shot recognition. First, perhaps surprisingly, simply finetuning the VLM on a large amount of retrieved data barely surpasses state-of-the-art zero-shot methods due to the imbalanced distribution of retrieved data and its domain gaps compared to few-shot annotated data. Second, finetuning a VLM on few-shot examples alone significantly outperforms prior methods, and finetuning on the mix of retrieved and few-shot data yields even better results. Third, to mitigate the imbalanced distribution and domain gap issue, we propose Stage-Wise Augmented fineTuning (SWAT) method, which involves end-to-end finetuning on mixed data for the first stage and retraining the classifier solely on the few-shot data in the second stage. Extensive experiments show that SWAT achieves the best performance on standard benchmark datasets, resoundingly outperforming prior works by ~10% in accuracy. Code is available at https://github.com/tian1327/SWAT.
The Neglected Tails of Vision-Language Models
Feb 02, 2024
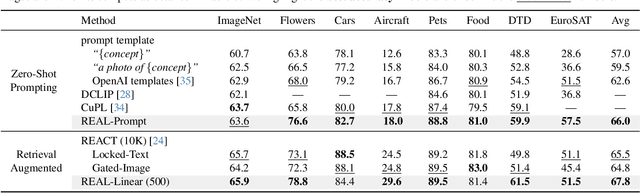

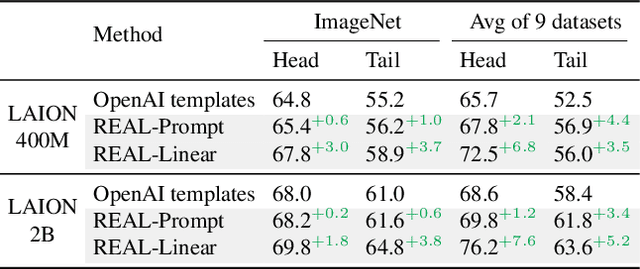
Vision-language models (VLMs) excel in zero-shot recognition but their performance varies greatly across different visual concepts. For example, although CLIP achieves impressive accuracy on ImageNet (60-80%), its performance drops below 10% for more than ten concepts like night snake, presumably due to their limited presence in the pretraining data. However, measuring the frequency of concepts in VLMs' large-scale datasets is challenging. We address this by using large language models (LLMs) to count the number of pretraining texts that contain synonyms of these concepts. Our analysis confirms that popular datasets, such as LAION, exhibit a long-tailed concept distribution, yielding biased performance in VLMs. We also find that downstream applications of VLMs, including visual chatbots (e.g., GPT-4V) and text-to-image models (e.g., Stable Diffusion), often fail to recognize or generate images of rare concepts identified by our method. To mitigate the imbalanced performance of zero-shot VLMs, we propose REtrieval-Augmented Learning (REAL). First, instead of prompting VLMs using the original class names, REAL uses their most frequent synonyms found in pretraining texts. This simple change already outperforms costly human-engineered and LLM-enriched prompts over nine benchmark datasets. Second, REAL trains a linear classifier on a small yet balanced set of pretraining data retrieved using concept synonyms. REAL surpasses the previous zero-shot SOTA, using 400x less storage and 10,000x less training time!
Prompting Scientific Names for Zero-Shot Species Recognition
Oct 15, 2023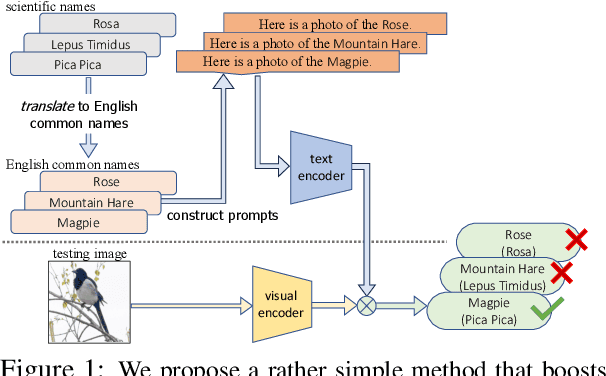
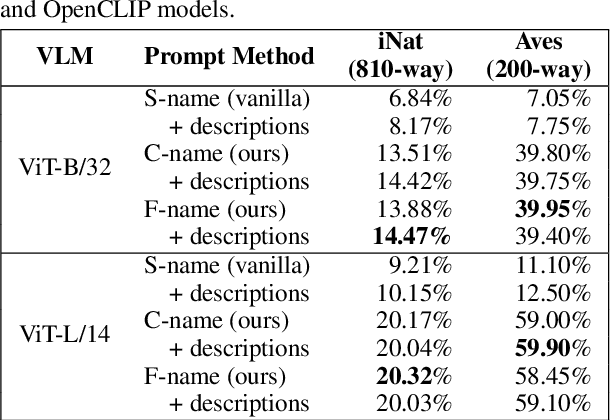

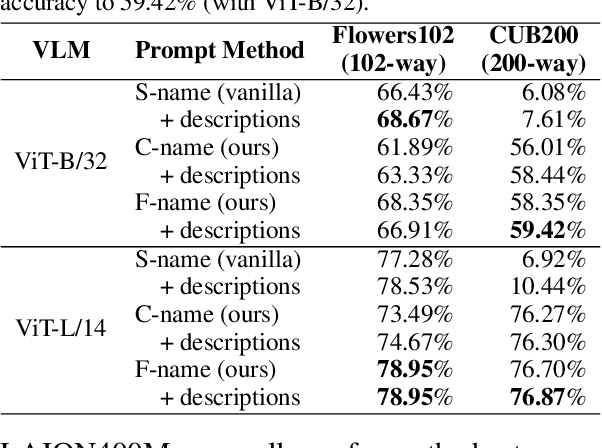
Trained on web-scale image-text pairs, Vision-Language Models (VLMs) such as CLIP can recognize images of common objects in a zero-shot fashion. However, it is underexplored how to use CLIP for zero-shot recognition of highly specialized concepts, e.g., species of birds, plants, and animals, for which their scientific names are written in Latin or Greek. Indeed, CLIP performs poorly for zero-shot species recognition with prompts that use scientific names, e.g., "a photo of Lepus Timidus" (which is a scientific name in Latin). Because these names are usually not included in CLIP's training set. To improve performance, prior works propose to use large-language models (LLMs) to generate descriptions (e.g., of species color and shape) and additionally use them in prompts. We find that they bring only marginal gains. Differently, we are motivated to translate scientific names (e.g., Lepus Timidus) to common English names (e.g., mountain hare) and use such in the prompts. We find that common names are more likely to be included in CLIP's training set, and prompting them achieves 2$\sim$5 times higher accuracy on benchmarking datasets of fine-grained species recognition.