 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Recognition via Stage-Wise Augmented Finetuning
Paper and Code


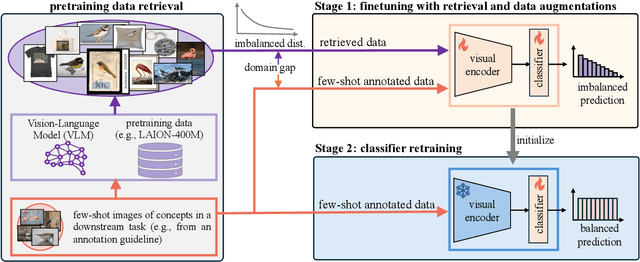
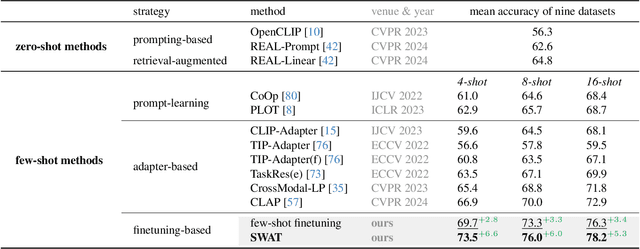
Few-shot recognition aims to train a classification model with only a few labeled examples of pre-defined concepts, where annotation can be costly in a downstream task. In another related research area, zero-shot recognition, which assumes no access to any downstream-task data, has been greatly advanced by using pretrained Vision-Language Models (VLMs). In this area, retrieval-augmented learning (RAL) effectively boosts zero-shot accuracy by retrieving and learning from external data relevant to downstream concepts. Motivated by these advancements, our work explores RAL for few-shot recognition. While seemingly straightforward despite being under-explored in the literature (till now!), we present novel challenges and opportunities for applying RAL for few-shot recognition. First, perhaps surprisingly, simply finetuning the VLM on a large amount of retrieved data barely surpasses state-of-the-art zero-shot methods due to the imbalanced distribution of retrieved data and its domain gaps compared to few-shot annotated data. Second, finetuning a VLM on few-shot examples alone significantly outperforms prior methods, and finetuning on the mix of retrieved and few-shot data yields even better results. Third, to mitigate the imbalanced distribution and domain gap issue, we propose Stage-Wise Augmented fineTuning (SWAT) method, which involves end-to-end finetuning on mixed data for the first stage and retraining the classifier solely on the few-shot data in the second stage. Extensive experiments show that SWAT achieves the best performance on standard benchmark datasets, resoundingly outperforming prior works by ~10% in accuracy. Code is available at https://github.com/tian1327/SWAT.