 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating a Paracosm for Training-Free Zero-Shot Composed Image Retrieval
Feb 03, 2026Composed Image Retrieval (CIR) is the task of retrieving a target image from a database using a multimodal query, which consists of a reference image and a modification text. The text specifies how to alter the reference image to form a ``mental image'', based on which CIR should find the target image in the database. The fundamental challenge of CIR is that this ``mental image'' is not physically available and is only implicitly defined by the query. The contemporary literature pursues zero-shot methods and uses a Large Multimodal Model (LMM) to generate a textual description for a given multimodal query, and then employs a Vision-Language Model (VLM) for textual-visual matching to search the target image. In contrast, we address CIR from first principles by directly generating the ``mental image'' for more accurate matching. Particularly, we prompt an LMM to generate a ``mental image'' for a given multimodal query and propose to use this ``mental image'' to search for the target image. As the ``mental image'' has a synthetic-to-real domain gap with real images, we also generate a synthetic counterpart for each real image in the database to facilitate matching. In this sense, our method uses LMM to construct a ``paracosm'', where it matches the multimodal query and database images. Hence, we call this method Paracosm. Notably, Paracosm is a training-free zero-shot CIR method. It significantly outperforms existing zero-shot methods on four challenging benchmarks, achieving state-of-the-art performance for zero-shot CIR.
Solving Semi-Supervised Few-Shot Learning from an Auto-Annotation Perspective
Dec 11, 2025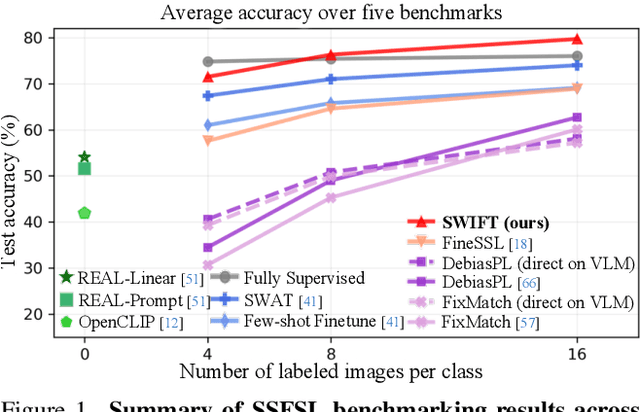
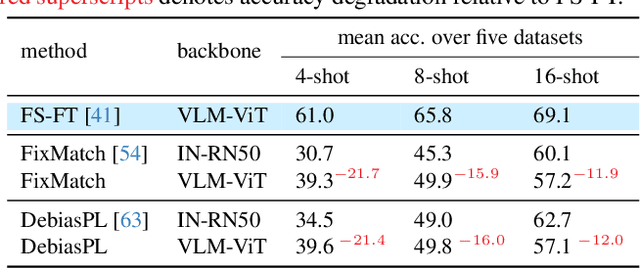
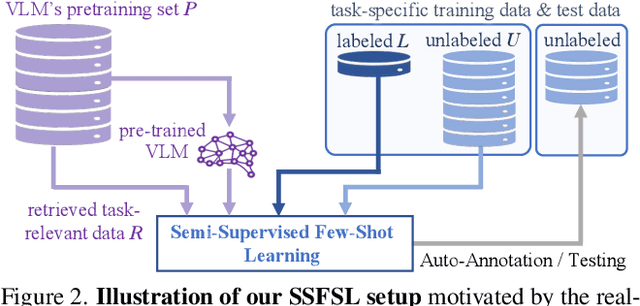
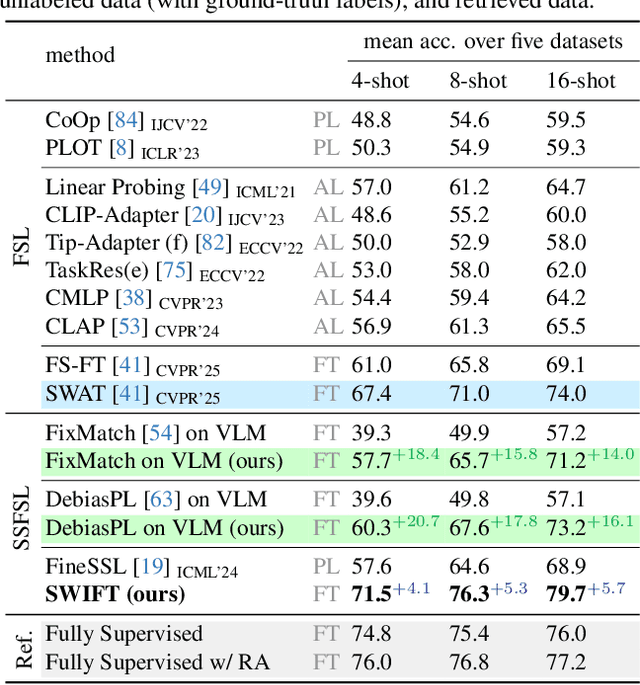
Semi-supervised few-shot learning (SSFSL) formulates real-world applications like ''auto-annotation'', as it aims to learn a model over a few labeled and abundant unlabeled examples to annotate the unlabeled ones. Despite the availability of powerful open-source Vision-Language Models (VLMs) and their pretraining data, the SSFSL literature largely neglects these open-source resources. In contrast, the related area few-shot learning (FSL) has already exploited them to boost performance. Arguably, to achieve auto-annotation in the real world, SSFSL should leverage such open-source resources. To this end, we start by applying established SSL methods to finetune a VLM. Counterintuitively, they significantly underperform FSL baselines. Our in-depth analysis reveals the root cause: VLMs produce rather ''flat'' distributions of softmax probabilities. This results in zero utilization of unlabeled data and weak supervision signals. We address this issue with embarrassingly simple techniques: classifier initialization and temperature tuning. They jointly increase the confidence scores of pseudo-labels, improving the utilization rate of unlabeled data, and strengthening supervision signals. Building on this, we propose: Stage-Wise Finetuning with Temperature Tuning (SWIFT), which enables existing SSL methods to effectively finetune a VLM on limited labeled data, abundant unlabeled data, and task-relevant but noisy data retrieved from the VLM's pretraining set. Extensive experiments on five SSFSL benchmarks show that SWIFT outperforms recent FSL and SSL methods by $\sim$5 accuracy points. SWIFT even rivals supervised learning, which finetunes VLMs with the unlabeled data being labeled with ground truth!
Surely Large Multimodal Models (Don't) Excel in Visual Species Recognition?
Dec 10, 2025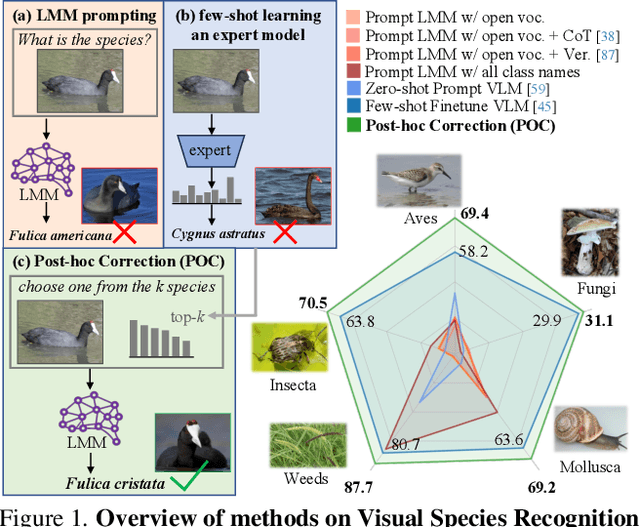
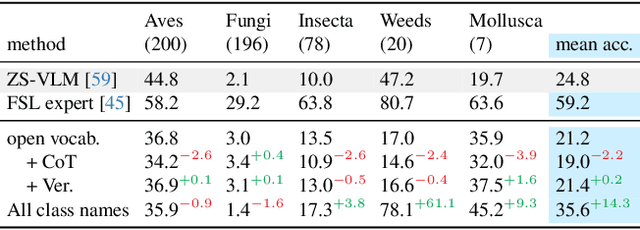

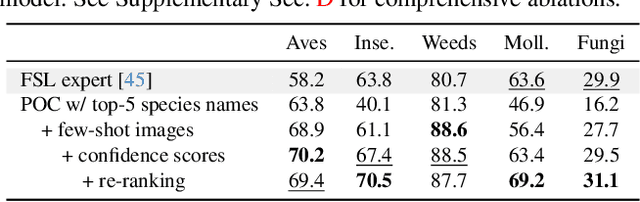
Visual Species Recognition (VSR) is pivotal to biodiversity assessment and conservation, evolution research, and ecology and ecosystem management. Training a machine-learned model for VSR typically requires vast amounts of annotated images. Yet, species-level annotation demands domain expertise, making it realistic for domain experts to annotate only a few examples. These limited labeled data motivate training an ''expert'' model via few-shot learning (FSL). Meanwhile, advanced Large Multimodal Models (LMMs) have demonstrated prominent performance on general recognition tasks. It is straightforward to ask whether LMMs excel in the highly specialized VSR task and whether they outshine FSL expert models. Somewhat surprisingly, we find that LMMs struggle in this task, despite using various established prompting techniques. LMMs even significantly underperform FSL expert models, which are as simple as finetuning a pretrained visual encoder on the few-shot images. However, our in-depth analysis reveals that LMMs can effectively post-hoc correct the expert models' incorrect predictions. Briefly, given a test image, when prompted with the top predictions from an FSL expert model, LMMs can recover the ground-truth label. Building on this insight, we derive a simple method called Post-hoc Correction (POC), which prompts an LMM to re-rank the expert model's top predictions using enriched prompts that include softmax confidence scores and few-shot visual examples. Across five challenging VSR benchmarks, POC outperforms prior art of FSL by +6.4% in accuracy without extra training, validation, or manual intervention. Importantly, POC generalizes to different pretrained backbones and LMMs, serving as a plug-and-play module to significantly enhance existing FSL methods.
Super LiDAR Reflectance for Robotic Perception
Aug 14, 2025Conventionally, human intuition often defines vision as a modality of passive optical sensing, while active optical sensing is typically regarded as measuring rather than the default modality of vision. However, the situation now changes: sensor technologies and data-driven paradigms empower active optical sensing to redefine the boundaries of vision, ushering in a new era of active vision. Light Detection and Ranging (LiDAR) sensors capture reflectance from object surfaces, which remains invariant under varying illumination conditions, showcasing significant potential in robotic perception tasks such as detection, recognition, segmentation, and Simultaneous Localization and Mapping (SLAM). These applications often rely on dense sensing capabilities, typically achieved by high-resolution, expensive LiDAR sensors. A key challenge with low-cost LiDARs lies in the sparsity of scan data, which limits their broader application. To address this limitation, this work introduces an innovative framework for generating dense LiDAR reflectance images from sparse data, leveraging the unique attributes of non-repeating scanning LiDAR (NRS-LiDAR). We tackle critical challenges, including reflectance calibration and the transition from static to dynamic scene domains, facilitating the reconstruction of dense reflectance images in real-world settings. The key contributions of this work include a comprehensive dataset for LiDAR reflectance image densification, a densification network tailored for NRS-LiDAR, and diverse applications such as loop closure and traffic lane detection using the generated dense reflectance images.
Robust Few-Shot Vision-Language Model Adaptation
Jun 05, 2025Pretrained VLMs achieve strong performance on downstream tasks when adapted with just a few labeled examples. As the adapted models inevitably encounter out-of-distribution (OOD) test data that deviates from the in-distribution (ID) task-specific training data, enhancing OOD generalization in few-shot adaptation is critically important. We study robust few-shot VLM adaptation, aiming to increase both ID and OOD accuracy. By comparing different adaptation methods (e.g., prompt tuning, linear probing, contrastive finetuning, and full finetuning), we uncover three key findings: (1) finetuning with proper hyperparameters significantly outperforms the popular VLM adaptation methods prompt tuning and linear probing; (2) visual encoder-only finetuning achieves better efficiency and accuracy than contrastively finetuning both visual and textual encoders; (3) finetuning the top layers of the visual encoder provides the best balance between ID and OOD accuracy. Building on these findings, we propose partial finetuning of the visual encoder empowered with two simple augmentation techniques: (1) retrieval augmentation which retrieves task-relevant data from the VLM's pretraining dataset to enhance adaptation, and (2) adversarial perturbation which promotes robustness during finetuning. Results show that the former/latter boosts OOD/ID accuracy while slightly sacrificing the ID/OOD accuracy. Yet, perhaps understandably, naively combining the two does not maintain their best OOD/ID accuracy. We address this dilemma with the developed SRAPF, Stage-wise Retrieval Augmentation-based Adversarial Partial Finetuning. SRAPF consists of two stages: (1) partial finetuning the visual encoder using both ID and retrieved data, and (2) adversarial partial finetuning with few-shot ID data. Extensive experiments demonstrate that SRAPF achieves the state-of-the-art ID and OOD accuracy on the ImageNet OOD benchmarks.
UAL-Bench: The First Comprehensive Unusual Activity Localization Benchmark
Oct 02, 2024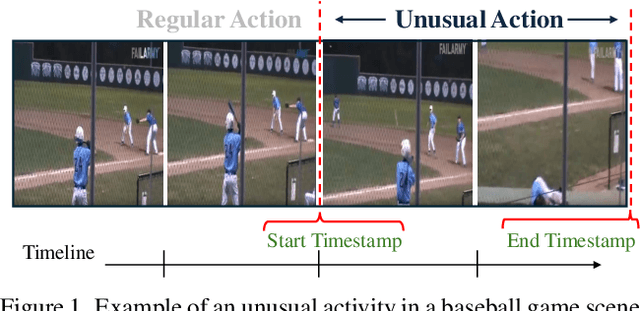
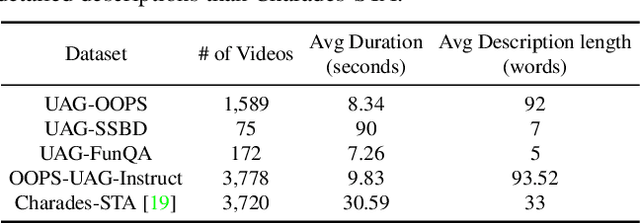
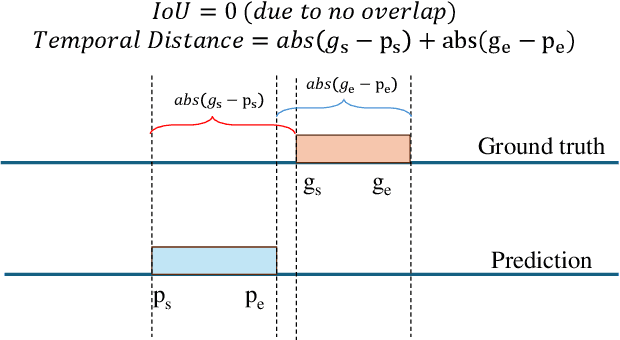
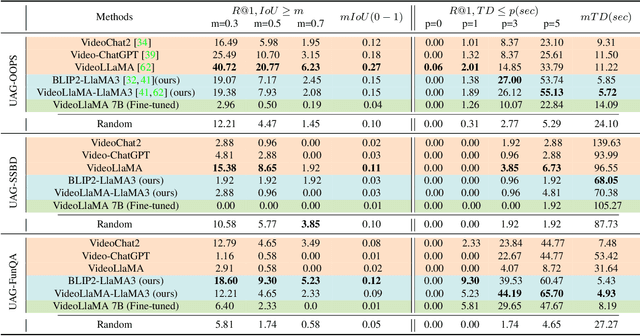
Localizing unusual activities, such as human errors or surveillance incidents, in videos holds practical significance. However, current video understanding models struggle with localizing these unusual events likely because of their insufficient representation in models' pretraining datasets. To explore foundation models' capability in localizing unusual activity, we introduce UAL-Bench, a comprehensive benchmark for unusual activity localization, featuring three video datasets: UAG-OOPS, UAG-SSBD, UAG-FunQA, and an instruction-tune dataset: OOPS-UAG-Instruct, to improve model capabilities. UAL-Bench evaluates three approaches: Video-Language Models (Vid-LLMs), instruction-tuned Vid-LLMs, and a novel integration of Vision-Language Models and Large Language Models (VLM-LLM). Our results show the VLM-LLM approach excels in localizing short-span unusual events and predicting their onset (start time) more accurately than Vid-LLMs. We also propose a new metric, R@1, TD <= p, to address limitations in existing evaluation methods. Our findings highlight the challenges posed by long-duration videos, particularly in autism diagnosis scenarios, and the need for further advancements in localization techniques. Our work not only provides a benchmark for unusual activity localization but also outlines the key challenges for existing foundation models, suggesting future research directions on this important task.
Lidar Panoptic Segmentation in an Open World
Sep 22, 2024Addressing Lidar Panoptic Segmentation (LPS ) is crucial for safe deployment of autonomous vehicles. LPS aims to recognize and segment lidar points w.r.t. a pre-defined vocabulary of semantic classes, including thing classes of countable objects (e.g., pedestrians and vehicles) and stuff classes of amorphous regions (e.g., vegetation and road). Importantly, LPS requires segmenting individual thing instances (e.g., every single vehicle). Current LPS methods make an unrealistic assumption that the semantic class vocabulary is fixed in the real open world, but in fact, class ontologies usually evolve over time as robots encounter instances of novel classes that are considered to be unknowns w.r.t. the pre-defined class vocabulary. To address this unrealistic assumption, we study LPS in the Open World (LiPSOW): we train models on a dataset with a pre-defined semantic class vocabulary and study their generalization to a larger dataset where novel instances of thing and stuff classes can appear. This experimental setting leads to interesting conclusions. While prior art train class-specific instance segmentation methods and obtain state-of-the-art results on known classes, methods based on class-agnostic bottom-up grouping perform favorably on classes outside of the initial class vocabulary (i.e., unknown classes). Unfortunately, these methods do not perform on-par with fully data-driven methods on known classes. Our work suggests a middle ground: we perform class-agnostic point clustering and over-segment the input cloud in a hierarchical fashion, followed by binary point segment classification, akin to Region Proposal Network [1]. We obtain the final point cloud segmentation by computing a cut in the weighted hierarchical tree of point segments, independently of semantic classification. Remarkably, this unified approach leads to strong performance on both known and unknown classes.
LCA-on-the-Line: Benchmarking Out-of-Distribution Generalization with Class Taxonomies
Jul 22, 2024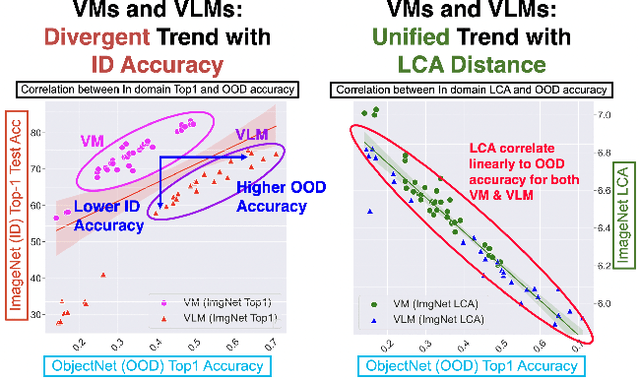
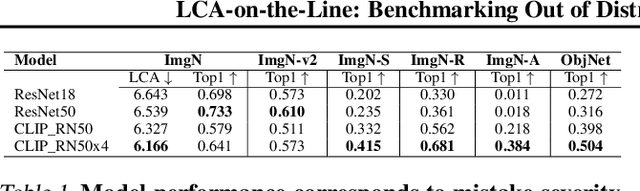
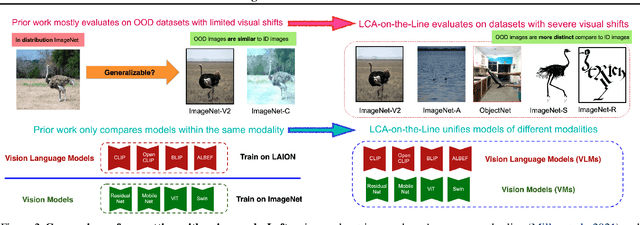
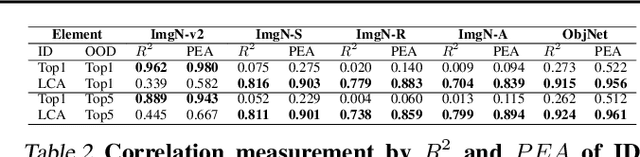
We tackle the challenge of predicting models' Out-of-Distribution (OOD) performance using in-distribution (ID) measurements without requiring OOD data. Existing evaluations with "Effective Robustness", which use ID accuracy as an indicator of OOD accuracy, encounter limitations when models are trained with diverse supervision and distributions, such as class labels (Vision Models, VMs, on ImageNet) and textual descriptions (Visual-Language Models, VLMs, on LAION). VLMs often generalize better to OOD data than VMs despite having similar or lower ID performance. To improve the prediction of models' OOD performance from ID measurements, we introduce the Lowest Common Ancestor (LCA)-on-the-Line framework. This approach revisits the established concept of LCA distance, which measures the hierarchical distance between labels and predictions within a predefined class hierarchy, such as WordNet. We assess 75 models using ImageNet as the ID dataset and five significantly shifted OOD variants, uncovering a strong linear correlation between ID LCA distance and OOD top-1 accuracy. Our method provides a compelling alternative for understanding why VLMs tend to generalize better. Additionally, we propose a technique to construct a taxonomic hierarchy on any dataset using K-means clustering, demonstrating that LCA distance is robust to the constructed taxonomic hierarchy. Moreover, we demonstrate that aligning model predictions with class taxonomies, through soft labels or prompt engineering, can enhance model generalization. Open source code in our Project Page: https://elvishelvis.github.io/papers/lca/.
Few-Shot Recognition via Stage-Wise Augmented Finetuning
Jun 17, 2024

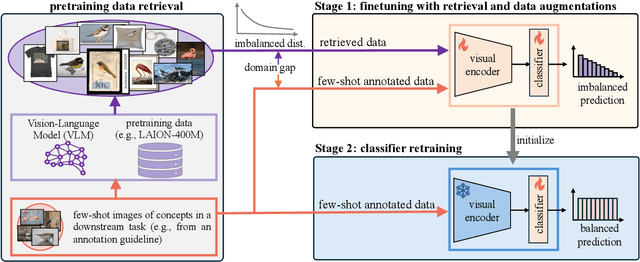
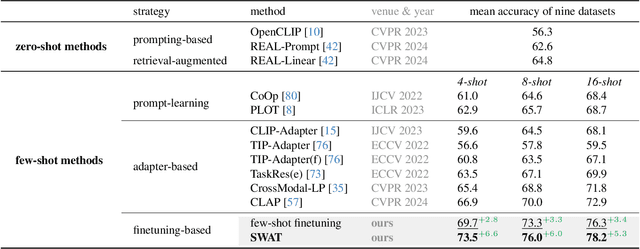
Few-shot recognition aims to train a classification model with only a few labeled examples of pre-defined concepts, where annotation can be costly in a downstream task. In another related research area, zero-shot recognition, which assumes no access to any downstream-task data, has been greatly advanced by using pretrained Vision-Language Models (VLMs). In this area, retrieval-augmented learning (RAL) effectively boosts zero-shot accuracy by retrieving and learning from external data relevant to downstream concepts. Motivated by these advancements, our work explores RAL for few-shot recognition. While seemingly straightforward despite being under-explored in the literature (till now!), we present novel challenges and opportunities for applying RAL for few-shot recognition. First, perhaps surprisingly, simply finetuning the VLM on a large amount of retrieved data barely surpasses state-of-the-art zero-shot methods due to the imbalanced distribution of retrieved data and its domain gaps compared to few-shot annotated data. Second, finetuning a VLM on few-shot examples alone significantly outperforms prior methods, and finetuning on the mix of retrieved and few-shot data yields even better results. Third, to mitigate the imbalanced distribution and domain gap issue, we propose Stage-Wise Augmented fineTuning (SWAT) method, which involves end-to-end finetuning on mixed data for the first stage and retraining the classifier solely on the few-shot data in the second stage. Extensive experiments show that SWAT achieves the best performance on standard benchmark datasets, resoundingly outperforming prior works by ~10% in accuracy. Code is available at https://github.com/tian1327/SWAT.
CriSp: Leveraging Tread Depth Maps for Enhanced Crime-Scene Shoeprint Matching
Apr 25, 2024



Shoeprints are a common type of evidence found at crime scenes and are used regularly in forensic investigations. However, existing methods cannot effectively employ deep learning techniques to match noisy and occluded crime-scene shoeprints to a shoe database due to a lack of training data. Moreover, all existing methods match crime-scene shoeprints to clean reference prints, yet our analysis shows matching to more informative tread depth maps yields better retrieval results. The matching task is further complicated by the necessity to identify similarities only in corresponding regions (heels, toes, etc) of prints and shoe treads. To overcome these challenges, we leverage shoe tread images from online retailers and utilize an off-the-shelf predictor to estimate depth maps and clean prints. Our method, named CriSp, matches crime-scene shoeprints to tread depth maps by training on this data. CriSp incorporates data augmentation to simulate crime-scene shoeprints, an encoder to learn spatially-aware features, and a masking module to ensure only visible regions of crime-scene prints affect retrieval results. To validate our approach, we introduce two validation sets by reprocessing existing datasets of crime-scene shoeprints and establish a benchmarking protocol for comparison. On this benchmark, CriSp significantly outperforms state-of-the-art methods in both automated shoeprint matching and image retrieval tailored to this task.