 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLCA-on-the-Line: Benchmarking Out-of-Distribution Generalization with Class Taxonomies
Paper and Code
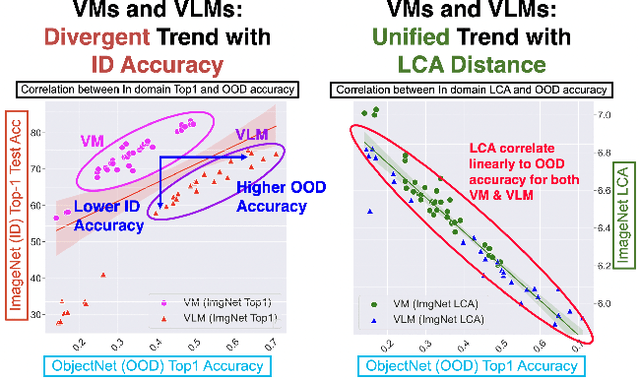
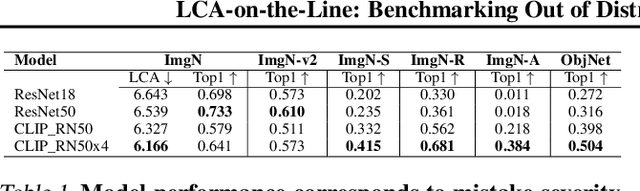
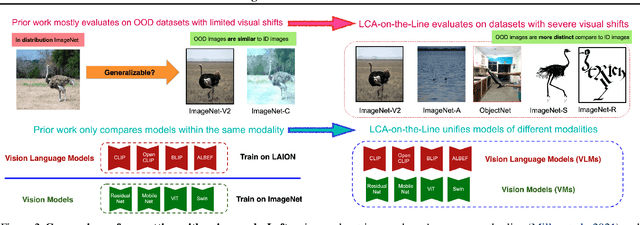
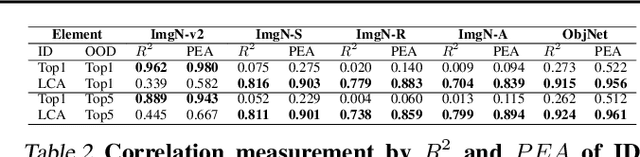
We tackle the challenge of predicting models' Out-of-Distribution (OOD) performance using in-distribution (ID) measurements without requiring OOD data. Existing evaluations with "Effective Robustness", which use ID accuracy as an indicator of OOD accuracy, encounter limitations when models are trained with diverse supervision and distributions, such as class labels (Vision Models, VMs, on ImageNet) and textual descriptions (Visual-Language Models, VLMs, on LAION). VLMs often generalize better to OOD data than VMs despite having similar or lower ID performance. To improve the prediction of models' OOD performance from ID measurements, we introduce the Lowest Common Ancestor (LCA)-on-the-Line framework. This approach revisits the established concept of LCA distance, which measures the hierarchical distance between labels and predictions within a predefined class hierarchy, such as WordNet. We assess 75 models using ImageNet as the ID dataset and five significantly shifted OOD variants, uncovering a strong linear correlation between ID LCA distance and OOD top-1 accuracy. Our method provides a compelling alternative for understanding why VLMs tend to generalize better. Additionally, we propose a technique to construct a taxonomic hierarchy on any dataset using K-means clustering, demonstrating that LCA distance is robust to the constructed taxonomic hierarchy. Moreover, we demonstrate that aligning model predictions with class taxonomies, through soft labels or prompt engineering, can enhance model generalization. Open source code in our Project Page: https://elvishelvis.github.io/papers/lca/.