 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Price of Ignorance: Information-Free Quotation for Data Retention in Machine Unlearning
Apr 13, 2026When users exercise data deletion rights under the General Data Protection Regulation (GDPR) and similar regulations, mobile network operators face a tradeoff: excessive machine unlearning degrades model accuracy and incurs retraining costs, yet existing pricing mechanisms for data retention require the server to know every user's private privacy and accuracy preferences, which is infeasible under the very regulations that motivate unlearning. We ask: what is the welfare cost of operating without this private information? We design an information-free ascending quotation mechanism where the server broadcasts progressively higher prices and users self-select their data supply, requiring no knowledge of users' parameters. Under complete information, the protocol admits a unique subgame-perfect Nash equilibrium characterized by single-period selling. We formalize the Price of Ignorance -- the welfare gap between optimal personalized pricing (which knows everything) and our information-free quotation (which knows nothing) -- and prove a three-regime efficiency ordering. Numerical evaluation across seven mechanisms and 5000 Monte Carlo runs shows that this price is near zero: the information-free mechanism achieves >=99% of the welfare of its information-intensive benchmarks, while providing noise-robust guarantees and comparable fairness.
PLawBench: A Rubric-Based Benchmark for Evaluating LLMs in Real-World Legal Practice
Jan 23, 2026As large language models (LLMs) are increasingly applied to legal domain-specific tasks, evaluating their ability to perform legal work in real-world settings has become essential. However, existing legal benchmarks rely on simplified and highly standardized tasks, failing to capture the ambiguity, complexity, and reasoning demands of real legal practice. Moreover, prior evaluations often adopt coarse, single-dimensional metrics and do not explicitly assess fine-grained legal reasoning. To address these limitations, we introduce PLawBench, a Practical Law Benchmark designed to evaluate LLMs in realistic legal practice scenarios. Grounded in real-world legal workflows, PLawBench models the core processes of legal practitioners through three task categories: public legal consultation, practical case analysis, and legal document generation. These tasks assess a model's ability to identify legal issues and key facts, perform structured legal reasoning, and generate legally coherent documents. PLawBench comprises 850 questions across 13 practical legal scenarios, with each question accompanied by expert-designed evaluation rubrics, resulting in approximately 12,500 rubric items for fine-grained assessment. Using an LLM-based evaluator aligned with human expert judgments, we evaluate 10 state-of-the-art LLMs. Experimental results show that none achieves strong performance on PLawBench, revealing substantial limitations in the fine-grained legal reasoning capabilities of current LLMs and highlighting important directions for future evaluation and development of legal LLMs. Data is available at: https://github.com/skylenage/PLawbench.
Ferret-UI Lite: Lessons from Building Small On-Device GUI Agents
Sep 30, 2025
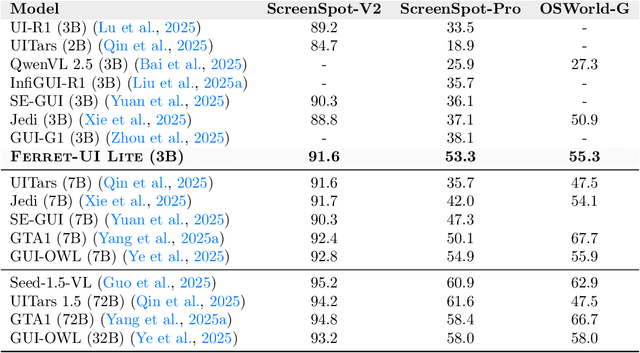
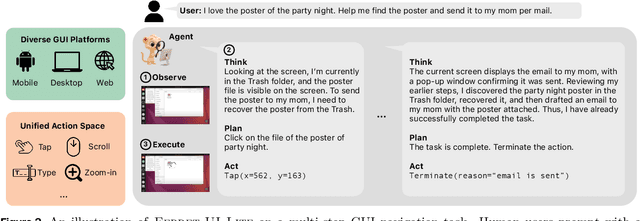
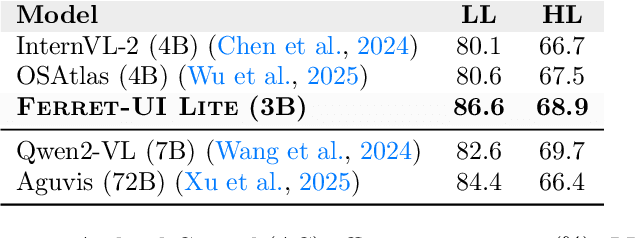
Developing autonomous agents that effectively interact with Graphic User Interfaces (GUIs) remains a challenging open problem, especially for small on-device models. In this paper, we present Ferret-UI Lite, a compact, end-to-end GUI agent that operates across diverse platforms, including mobile, web, and desktop. Utilizing techniques optimized for developing small models, we build our 3B Ferret-UI Lite agent through curating a diverse GUI data mixture from real and synthetic sources, strengthening inference-time performance through chain-of-thought reasoning and visual tool-use, and reinforcement learning with designed rewards. Ferret-UI Lite achieves competitive performance with other small-scale GUI agents. In GUI grounding, Ferret-UI Lite attains scores of $91.6\%$, $53.3\%$, and $61.2\%$ on the ScreenSpot-V2, ScreenSpot-Pro, and OSWorld-G benchmarks, respectively. For GUI navigation, Ferret-UI Lite achieves success rates of $28.0\%$ on AndroidWorld and $19.8\%$ on OSWorld. We share our methods and lessons learned from developing compact, on-device GUI agents.
Buyer-Initiated Auction Mechanism for Data Redemption in Machine Unlearning
Apr 01, 2025



The rapid growth of artificial intelligence (AI) has raised privacy concerns over user data, leading to regulations like the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA). With the essential toolbox provided by machine unlearning, AI service providers are now able to remove user data from their trained models as well as the training datasets, so as to comply with such regulations. However, extensive data redemption can be costly and degrade model accuracy. To balance the cost of unlearning and the privacy protection, we propose a buyer-initiated auction mechanism for data redemption, enabling the service provider to purchase data from willing users with appropriate compensation. This approach does not require the server to have any a priori knowledge about the users' privacy preference, and provides an efficient solution for maximizing the social welfare in the investigated problem.
Ferret-UI 2: Mastering Universal User Interface Understanding Across Platforms
Oct 24, 2024Building a generalist model for user interface (UI) understanding is challenging due to various foundational issues, such as platform diversity, resolution variation, and data limitation. In this paper, we introduce Ferret-UI 2, a multimodal large language model (MLLM) designed for universal UI understanding across a wide range of platforms, including iPhone, Android, iPad, Webpage, and AppleTV. Building on the foundation of Ferret-UI, Ferret-UI 2 introduces three key innovations: support for multiple platform types, high-resolution perception through adaptive scaling, and advanced task training data generation powered by GPT-4o with set-of-mark visual prompting. These advancements enable Ferret-UI 2 to perform complex, user-centered interactions, making it highly versatile and adaptable for the expanding diversity of platform ecosystems. Extensive empirical experiments on referring, grounding, user-centric advanced tasks (comprising 9 subtasks $\times$ 5 platforms), GUIDE next-action prediction dataset, and GUI-World multi-platform benchmark demonstrate that Ferret-UI 2 significantly outperforms Ferret-UI, and also shows strong cross-platform transfer capabilities.
LCA-on-the-Line: Benchmarking Out-of-Distribution Generalization with Class Taxonomies
Jul 22, 2024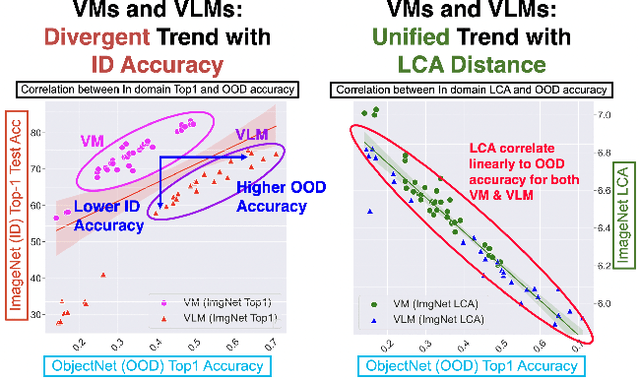
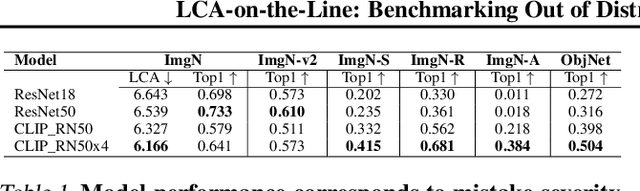
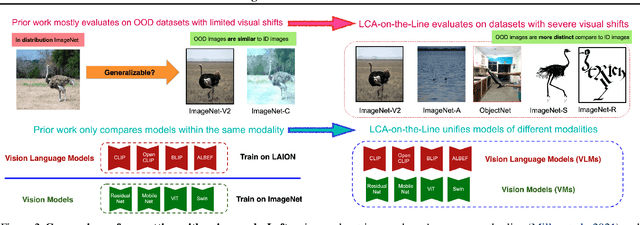
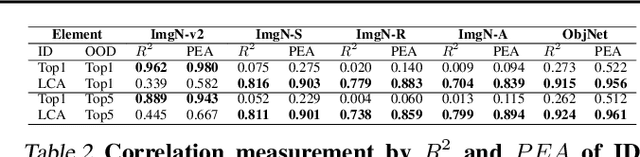
We tackle the challenge of predicting models' Out-of-Distribution (OOD) performance using in-distribution (ID) measurements without requiring OOD data. Existing evaluations with "Effective Robustness", which use ID accuracy as an indicator of OOD accuracy, encounter limitations when models are trained with diverse supervision and distributions, such as class labels (Vision Models, VMs, on ImageNet) and textual descriptions (Visual-Language Models, VLMs, on LAION). VLMs often generalize better to OOD data than VMs despite having similar or lower ID performance. To improve the prediction of models' OOD performance from ID measurements, we introduce the Lowest Common Ancestor (LCA)-on-the-Line framework. This approach revisits the established concept of LCA distance, which measures the hierarchical distance between labels and predictions within a predefined class hierarchy, such as WordNet. We assess 75 models using ImageNet as the ID dataset and five significantly shifted OOD variants, uncovering a strong linear correlation between ID LCA distance and OOD top-1 accuracy. Our method provides a compelling alternative for understanding why VLMs tend to generalize better. Additionally, we propose a technique to construct a taxonomic hierarchy on any dataset using K-means clustering, demonstrating that LCA distance is robust to the constructed taxonomic hierarchy. Moreover, we demonstrate that aligning model predictions with class taxonomies, through soft labels or prompt engineering, can enhance model generalization. Open source code in our Project Page: https://elvishelvis.github.io/papers/lca/.
FastOcc: Accelerating 3D Occupancy Prediction by Fusing the 2D Bird's-Eye View and Perspective View
Mar 05, 2024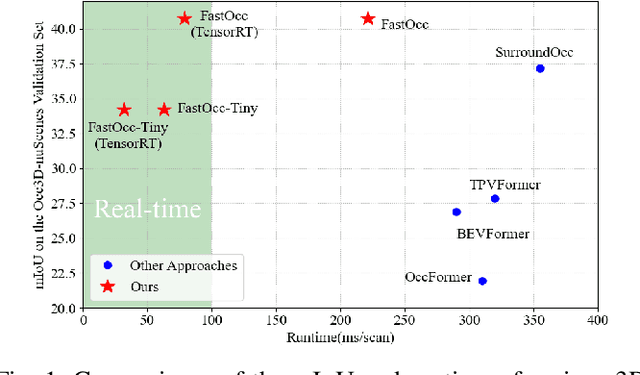
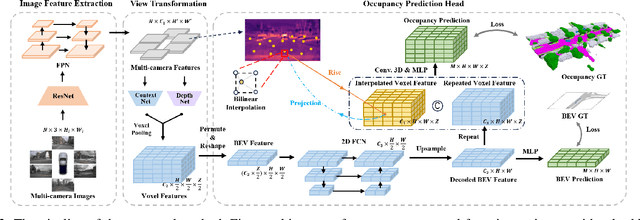
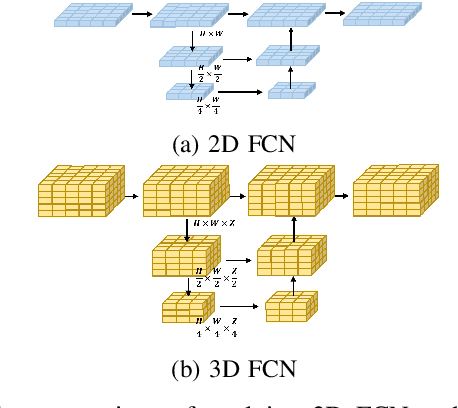
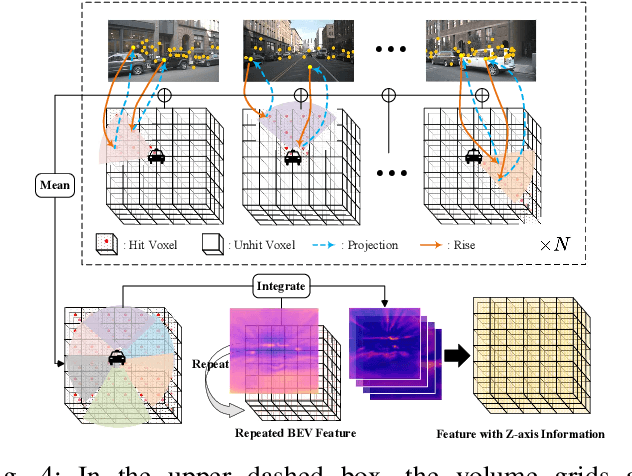
In autonomous driving, 3D occupancy prediction outputs voxel-wise status and semantic labels for more comprehensive understandings of 3D scenes compared with traditional perception tasks, such as 3D object detection and bird's-eye view (BEV) semantic segmentation. Recent researchers have extensively explored various aspects of this task, including view transformation techniques, ground-truth label generation, and elaborate network design, aiming to achieve superior performance. However, the inference speed, crucial for running on an autonomous vehicle, is neglected. To this end, a new method, dubbed FastOcc, is proposed. By carefully analyzing the network effect and latency from four parts, including the input image resolution, image backbone, view transformation, and occupancy prediction head, it is found that the occupancy prediction head holds considerable potential for accelerating the model while keeping its accuracy. Targeted at improving this component, the time-consuming 3D convolution network is replaced with a novel residual-like architecture, where features are mainly digested by a lightweight 2D BEV convolution network and compensated by integrating the 3D voxel features interpolated from the original image features. Experiments on the Occ3D-nuScenes benchmark demonstrate that our FastOcc achieves state-of-the-art results with a fast inference speed.
Revisiting Multi-modal 3D Semantic Segmentation in Real-world Autonomous Driving
Oct 13, 2023LiDAR and camera are two critical sensors for multi-modal 3D semantic segmentation and are supposed to be fused efficiently and robustly to promise safety in various real-world scenarios. However, existing multi-modal methods face two key challenges: 1) difficulty with efficient deployment and real-time execution; and 2) drastic performance degradation under weak calibration between LiDAR and cameras. To address these challenges, we propose CPGNet-LCF, a new multi-modal fusion framework extending the LiDAR-only CPGNet. CPGNet-LCF solves the first challenge by inheriting the easy deployment and real-time capabilities of CPGNet. For the second challenge, we introduce a novel weak calibration knowledge distillation strategy during training to improve the robustness against the weak calibration. CPGNet-LCF achieves state-of-the-art performance on the nuScenes and SemanticKITTI benchmarks. Remarkably, it can be easily deployed to run in 20ms per frame on a single Tesla V100 GPU using TensorRT TF16 mode. Furthermore, we benchmark performance over four weak calibration levels, demonstrating the robustness of our proposed approach.
Priors are Powerful: Improving a Transformer for Multi-camera 3D Detection with 2D Priors
Jan 31, 2023



Transfomer-based approaches advance the recent development of multi-camera 3D detection both in academia and industry. In a vanilla transformer architecture, queries are randomly initialised and optimised for the whole dataset, without considering the differences among input frames. In this work, we propose to leverage the predictions from an image backbone, which is often highly optimised for 2D tasks, as priors to the transformer part of a 3D detection network. The method works by (1). augmenting image feature maps with 2D priors, (2). sampling query locations via ray-casting along 2D box centroids, as well as (3). initialising query features with object-level image features. Experimental results shows that 2D priors not only help the model converge faster, but also largely improve the baseline approach by up to 12% in terms of average precision.
DeepFusion: A Robust and Modular 3D Object Detector for Lidars, Cameras and Radars
Sep 27, 2022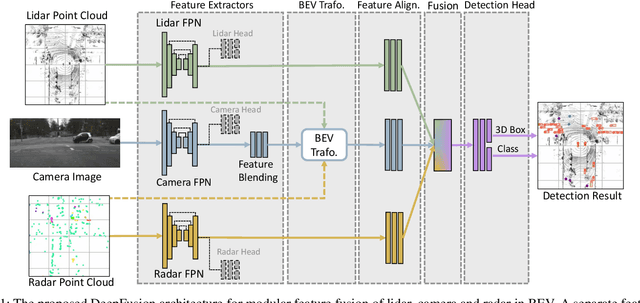
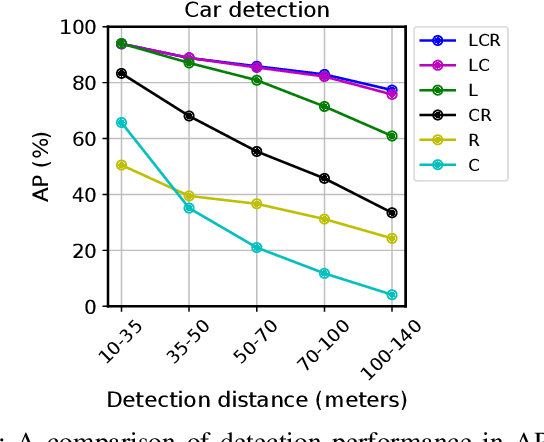
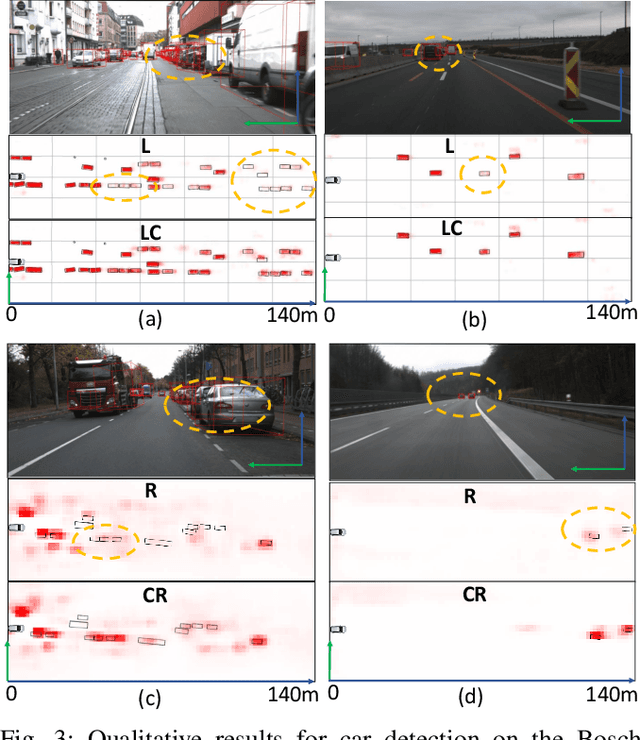
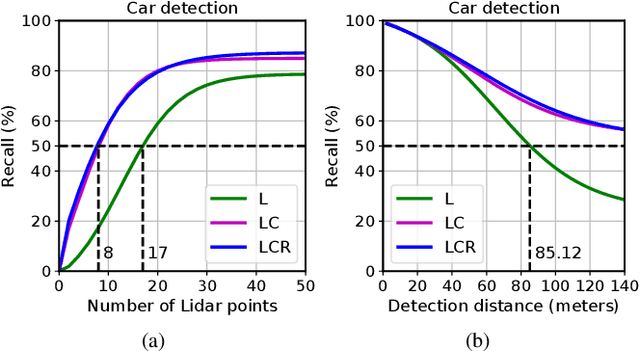
We propose DeepFusion, a modular multi-modal architecture to fuse lidars, cameras and radars in different combinations for 3D object detection. Specialized feature extractors take advantage of each modality and can be exchanged easily, making the approach simple and flexible. Extracted features are transformed into bird's-eye-view as a common representation for fusion. Spatial and semantic alignment is performed prior to fusing modalities in the feature space. Finally, a detection head exploits rich multi-modal features for improved 3D detection performance. Experimental results for lidar-camera, lidar-camera-radar and camera-radar fusion show the flexibility and effectiveness of our fusion approach. In the process, we study the largely unexplored task of faraway car detection up to 225 meters, showing the benefits of our lidar-camera fusion. Furthermore, we investigate the required density of lidar points for 3D object detection and illustrate implications at the example of robustness against adverse weather conditions. Moreover, ablation studies on our camera-radar fusion highlight the importance of accurate depth estimation.