 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLA-AN: An Efficient and Onboard Vision-Language-Action Framework for Aerial Navigation in Complex Environments
Dec 19, 2025



This paper proposes VLA-AN, an efficient and onboard Vision-Language-Action (VLA) framework dedicated to autonomous drone navigation in complex environments. VLA-AN addresses four major limitations of existing large aerial navigation models: the data domain gap, insufficient temporal navigation with reasoning, safety issues with generative action policies, and onboard deployment constraints. First, we construct a high-fidelity dataset utilizing 3D Gaussian Splatting (3D-GS) to effectively bridge the domain gap. Second, we introduce a progressive three-stage training framework that sequentially reinforces scene comprehension, core flight skills, and complex navigation capabilities. Third, we design a lightweight, real-time action module coupled with geometric safety correction. This module ensures fast, collision-free, and stable command generation, mitigating the safety risks inherent in stochastic generative policies. Finally, through deep optimization of the onboard deployment pipeline, VLA-AN achieves a robust real-time 8.3x improvement in inference throughput on resource-constrained UAVs. Extensive experiments demonstrate that VLA-AN significantly improves spatial grounding, scene reasoning, and long-horizon navigation, achieving a maximum single-task success rate of 98.1%, and providing an efficient, practical solution for realizing full-chain closed-loop autonomy in lightweight aerial robots.
RTMap: Real-Time Recursive Mapping with Change Detection and Localization
Jul 01, 2025While recent online HD mapping methods relieve burdened offline pipelines and solve map freshness, they remain limited by perceptual inaccuracies, occlusion in dense traffic, and an inability to fuse multi-agent observations. We propose RTMap to enhance these single-traversal methods by persistently crowdsourcing a multi-traversal HD map as a self-evolutional memory. On onboard agents, RTMap simultaneously addresses three core challenges in an end-to-end fashion: (1) Uncertainty-aware positional modeling for HD map elements, (2) probabilistic-aware localization w.r.t. the crowdsourced prior-map, and (3) real-time detection for possible road structural changes. Experiments on several public autonomous driving datasets demonstrate our solid performance on both the prior-aided map quality and the localization accuracy, demonstrating our effectiveness of robustly serving downstream prediction and planning modules while gradually improving the accuracy and freshness of the crowdsourced prior-map asynchronously. Our source-code will be made publicly available at https://github.com/CN-ADLab/RTMap (Camera ready version incorporating reviewer suggestions will be updated soon).
ApexNav: An Adaptive Exploration Strategy for Zero-Shot Object Navigation with Target-centric Semantic Fusion
Apr 22, 2025



Navigating unknown environments to find a target object is a significant challenge. While semantic information is crucial for navigation, relying solely on it for decision-making may not always be efficient, especially in environments with weak semantic cues. Additionally, many methods are susceptible to misdetections, especially in environments with visually similar objects. To address these limitations, we propose ApexNav, a zero-shot object navigation framework that is both more efficient and reliable. For efficiency, ApexNav adaptively utilizes semantic information by analyzing its distribution in the environment, guiding exploration through semantic reasoning when cues are strong, and switching to geometry-based exploration when they are weak. For reliability, we propose a target-centric semantic fusion method that preserves long-term memory of the target object and similar objects, reducing false detections and minimizing task failures. We evaluate ApexNav on the HM3Dv1, HM3Dv2, and MP3D datasets, where it outperforms state-of-the-art methods in both SR and SPL metrics. Comprehensive ablation studies further demonstrate the effectiveness of each module. Furthermore, real-world experiments validate the practicality of ApexNav in physical environments. Project page is available at https://robotics-star.com/ApexNav.
FastOcc: Accelerating 3D Occupancy Prediction by Fusing the 2D Bird's-Eye View and Perspective View
Mar 05, 2024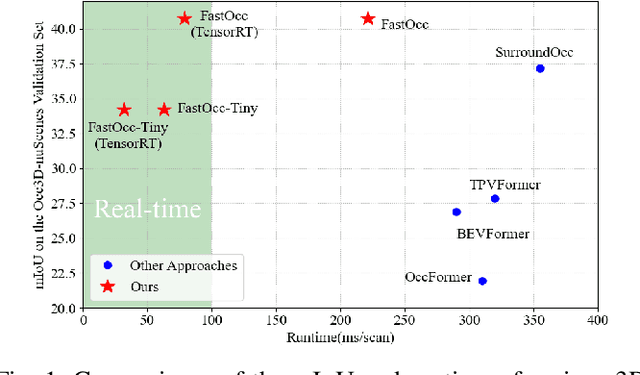
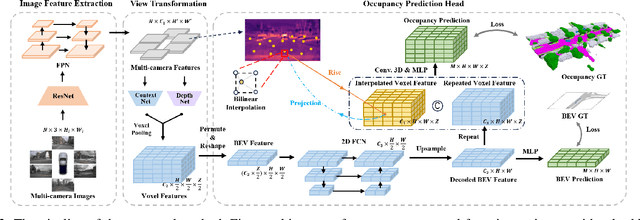
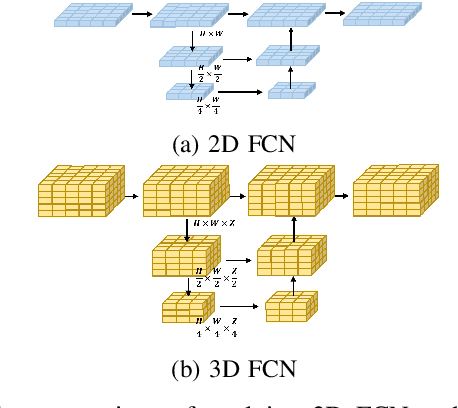
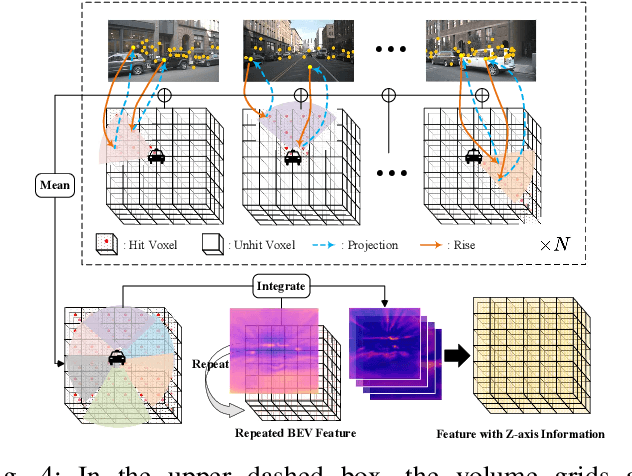
In autonomous driving, 3D occupancy prediction outputs voxel-wise status and semantic labels for more comprehensive understandings of 3D scenes compared with traditional perception tasks, such as 3D object detection and bird's-eye view (BEV) semantic segmentation. Recent researchers have extensively explored various aspects of this task, including view transformation techniques, ground-truth label generation, and elaborate network design, aiming to achieve superior performance. However, the inference speed, crucial for running on an autonomous vehicle, is neglected. To this end, a new method, dubbed FastOcc, is proposed. By carefully analyzing the network effect and latency from four parts, including the input image resolution, image backbone, view transformation, and occupancy prediction head, it is found that the occupancy prediction head holds considerable potential for accelerating the model while keeping its accuracy. Targeted at improving this component, the time-consuming 3D convolution network is replaced with a novel residual-like architecture, where features are mainly digested by a lightweight 2D BEV convolution network and compensated by integrating the 3D voxel features interpolated from the original image features. Experiments on the Occ3D-nuScenes benchmark demonstrate that our FastOcc achieves state-of-the-art results with a fast inference speed.
Proactive Query Expansion for Streaming Data Using External Source
Jan 17, 2022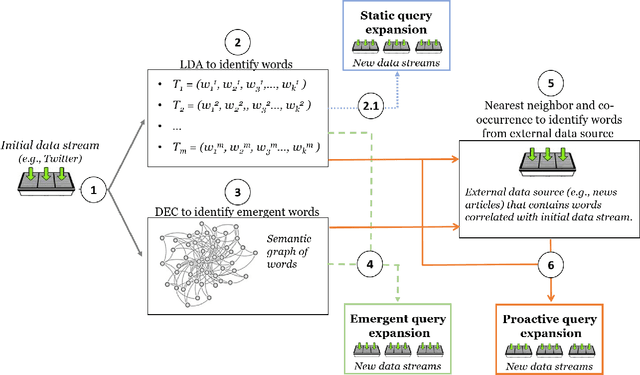
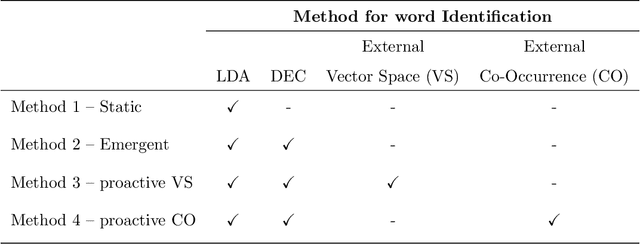

Query expansion is the process of reformulating the original query by adding relevant words. Choosing which terms to add in order to improve the performance of the query expansion methods or to enhance the quality of the retrieved results is an important aspect of any information retrieval system. Adding words that can positively impact the quality of the search query or are informative enough play an important role in returning or gathering relevant documents that cover a certain topic can result in improving the efficiency of the information retrieval system. Typically, query expansion techniques are used to add or substitute words to a given search query to collect relevant data. In this paper, we design and implement a pipeline of automated query expansion. We outline several tools using different methods to expand the query. Our methods depend on targeting emergent events in streaming data over time and finding the hidden topics from targeted documents using probabilistic topic models. We employ Dynamic Eigenvector Centrality to trigger the emergent events, and the Latent Dirichlet Allocation to discover the topics. Also, we use an external data source as a secondary stream to supplement the primary stream with relevant words and expand the query using the words from both primary and secondary streams. An experimental study is performed on Twitter data (primary stream) related to the events that happened during protests in Baltimore in 2015. The quality of the retrieved results was measured using a quality indicator of the streaming data: tweets count, hashtag count, and hashtag clustering.
Style Control for Schema-Guided Natural Language Generation
Sep 24, 2021

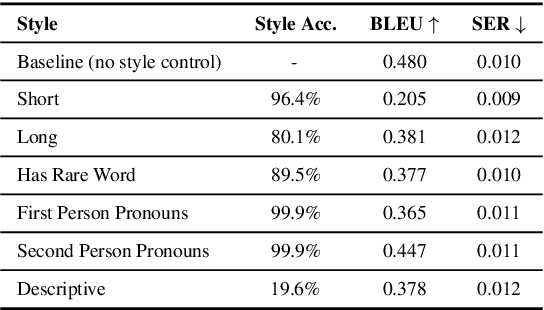

Natural Language Generation (NLG) for task-oriented dialogue systems focuses on communicating specific content accurately, fluently, and coherently. While these attributes are crucial for a successful dialogue, it is also desirable to simultaneously accomplish specific stylistic goals, such as response length, point-of-view, descriptiveness, sentiment, formality, and empathy. In this work, we focus on stylistic control and evaluation for schema-guided NLG, with joint goals of achieving both semantic and stylistic control. We experiment in detail with various controlled generation methods for large pretrained language models: specifically, conditional training, guided fine-tuning, and guided decoding. We discuss their advantages and limitations, and evaluate them with a broad range of automatic and human evaluation metrics. Our results show that while high style accuracy and semantic correctness are easier to achieve for more lexically-defined styles with conditional training, stylistic control is also achievable for more semantically complex styles using discriminator-based guided decoding methods. The results also suggest that methods that are more scalable (with less hyper-parameters tuning) and that disentangle content generation and stylistic variations are more effective at achieving semantic correctness and style accuracy.
Schema-Guided Natural Language Generation
May 11, 2020


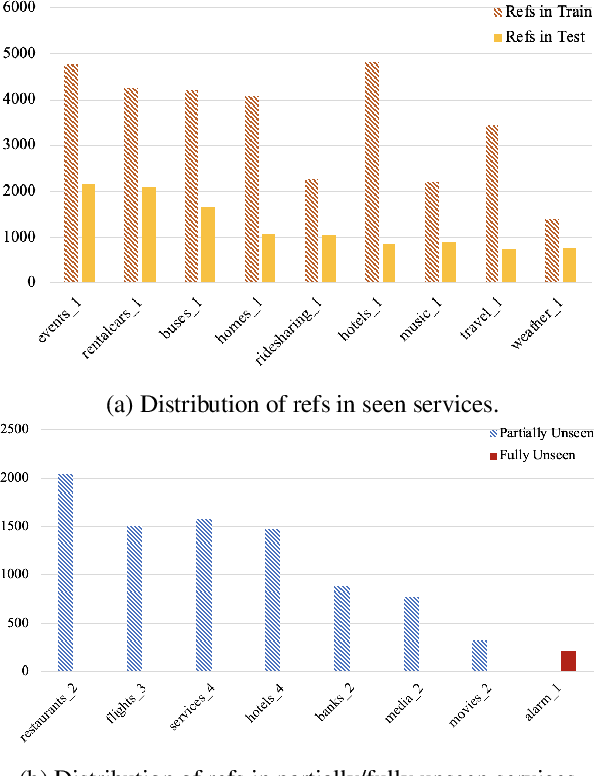
Neural network based approaches to natural language generation (NLG) have gained popularity in recent years. The goal of the task is to generate a natural language string to realize an input meaning representation, hence large datasets of paired utterances and their meaning representations are used for training the network. However, dataset creation for language generation is an arduous task, and popular datasets designed for training these generators mostly consist of simple meaning representations composed of slot and value tokens to be realized. These simple meaning representations do not include any contextual information that may be helpful for training an NLG system to generalize, such as domain information and descriptions of slots and values. In this paper, we present the novel task of Schema-Guided Natural Language Generation, in which we repurpose an existing dataset for another task: dialog state tracking. Dialog state tracking data includes a large and rich schema spanning multiple different attributes, including information about the domain, user intent, and slot descriptions. We train different state-of-the-art models for neural natural language generation on this data and show that inclusion of the rich schema allows our models to produce higher quality outputs both in terms of semantics and diversity. We also conduct experiments comparing model performance on seen versus unseen domains. Finally, we present human evaluation results and analysis demonstrating high ratings for overall output quality.