 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAurora: Are Android Malware Classifiers Reliable under Distribution Shift?
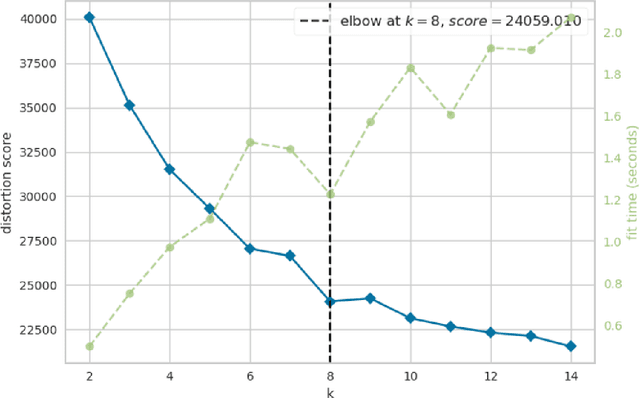
May 28, 2025The performance figures of modern drift-adaptive malware classifiers appear promising, but does this translate to genuine operational reliability? The standard evaluation paradigm primarily focuses on baseline performance metrics, neglecting confidence-error alignment and operational stability. While TESSERACT established the importance of temporal evaluation, we take a complementary direction by investigating whether malware classifiers maintain reliable confidence estimates under distribution shifts and exploring the tensions between scientific advancement and practical impacts when they do not. We propose AURORA, a framework to evaluate malware classifiers based on their confidence quality and operational resilience. AURORA subjects the confidence profile of a given model to verification to assess the reliability of its estimates. Unreliable confidence estimates erode operational trust, waste valuable annotation budget on non-informative samples for active learning, and leave error-prone instances undetected in selective classification. AURORA is further complemented by a set of metrics designed to go beyond point-in-time performance, striving towards a more holistic assessment of operational stability throughout temporal evaluation periods. The fragility we observe in state-of-the-art frameworks across datasets of varying drift severity suggests the need for a return to the whiteboard.
Gemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
FedMap: Iterative Magnitude-Based Pruning for Communication-Efficient Federated Learning
Jun 27, 2024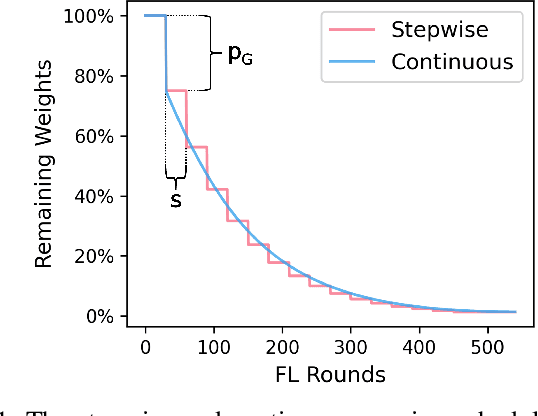
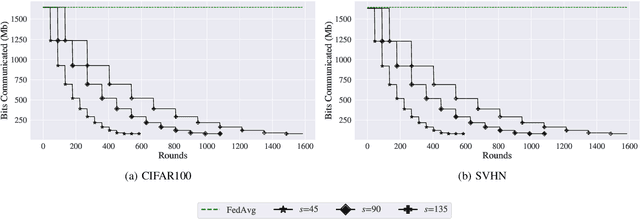
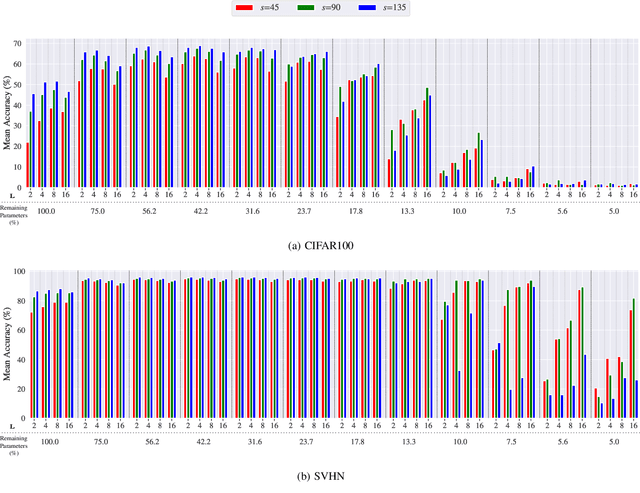
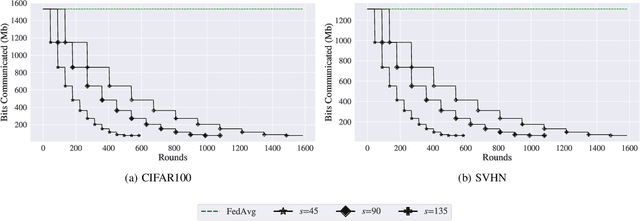
Federated Learning (FL) is a distributed machine learning approach that enables training on decentralized data while preserving privacy. However, FL systems often involve resource-constrained client devices with limited computational power, memory, storage, and bandwidth. This paper introduces FedMap, a novel method that aims to enhance the communication efficiency of FL deployments by collaboratively learning an increasingly sparse global model through iterative, unstructured pruning. Importantly, FedMap trains a global model from scratch, unlike other methods reported in the literature, making it ideal for privacy-critical use cases such as in the medical and finance domains, where suitable pre-training data is often limited. FedMap adapts iterative magnitude-based pruning to the FL setting, ensuring all clients prune and refine the same subset of the global model parameters, therefore gradually reducing the global model size and communication overhead. The iterative nature of FedMap, forming subsequent models as subsets of predecessors, avoids parameter reactivation issues seen in prior work, resulting in stable performance. In this paper we provide an extensive evaluation of FedMap across diverse settings, datasets, model architectures, and hyperparameters, assessing performance in both IID and non-IID environments. Comparative analysis against the baseline approach demonstrates FedMap's ability to achieve more stable client model performance. For IID scenarios, FedMap achieves over $90$\% pruning without significant performance degradation. In non-IID settings, it achieves at least $~80$\% pruning while maintaining accuracy. FedMap offers a promising solution to alleviate communication bottlenecks in FL systems while retaining model accuracy.
Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions
Sep 18, 2023



In this work, we present a scalable reinforcement learning method for training multi-task policies from large offline datasets that can leverage both human demonstrations and autonomously collected data. Our method uses a Transformer to provide a scalable representation for Q-functions trained via offline temporal difference backups. We therefore refer to the method as Q-Transformer. By discretizing each action dimension and representing the Q-value of each action dimension as separate tokens, we can apply effective high-capacity sequence modeling techniques for Q-learning. We present several design decisions that enable good performance with offline RL training, and show that Q-Transformer outperforms prior offline RL algorithms and imitation learning techniques on a large diverse real-world robotic manipulation task suite. The project's website and videos can be found at https://q-transformer.github.io
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Jul 28, 2023We study how vision-language models trained on Internet-scale data can be incorporated directly into end-to-end robotic control to boost generalization and enable emergent semantic reasoning. Our goal is to enable a single end-to-end trained model to both learn to map robot observations to actions and enjoy the benefits of large-scale pretraining on language and vision-language data from the web. To this end, we propose to co-fine-tune state-of-the-art vision-language models on both robotic trajectory data and Internet-scale vision-language tasks, such as visual question answering. In contrast to other approaches, we propose a simple, general recipe to achieve this goal: in order to fit both natural language responses and robotic actions into the same format, we express the actions as text tokens and incorporate them directly into the training set of the model in the same way as natural language tokens. We refer to such category of models as vision-language-action models (VLA) and instantiate an example of such a model, which we call RT-2. Our extensive evaluation (6k evaluation trials) shows that our approach leads to performant robotic policies and enables RT-2 to obtain a range of emergent capabilities from Internet-scale training. This includes significantly improved generalization to novel objects, the ability to interpret commands not present in the robot training data (such as placing an object onto a particular number or icon), and the ability to perform rudimentary reasoning in response to user commands (such as picking up the smallest or largest object, or the one closest to another object). We further show that incorporating chain of thought reasoning allows RT-2 to perform multi-stage semantic reasoning, for example figuring out which object to pick up for use as an improvised hammer (a rock), or which type of drink is best suited for someone who is tired (an energy drink).
Deep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators
May 05, 2023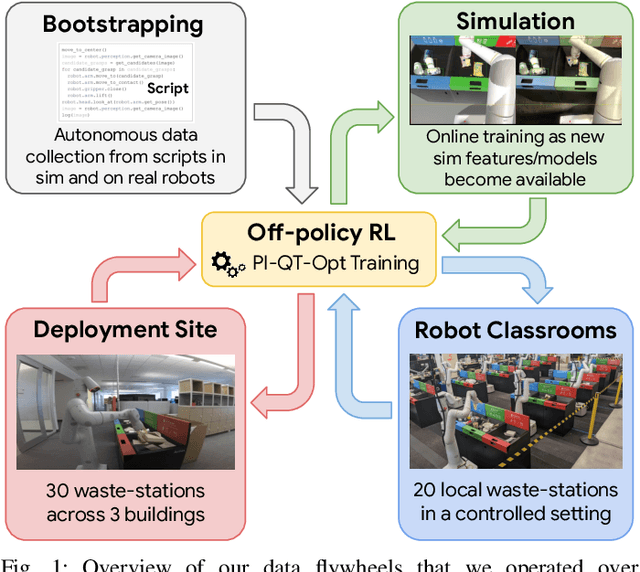

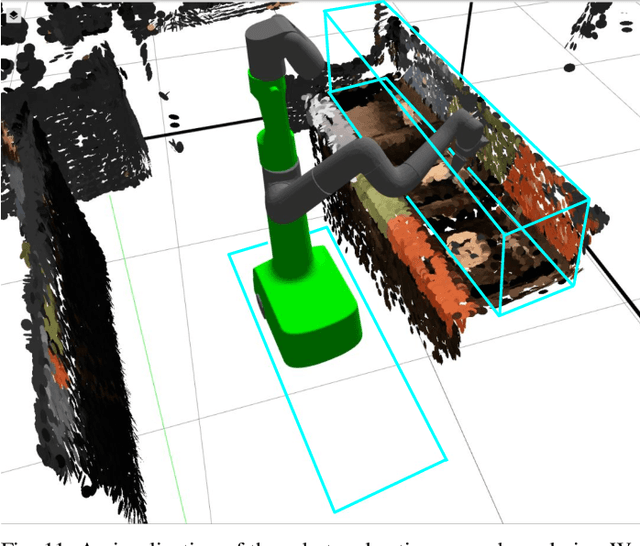

We describe a system for deep reinforcement learning of robotic manipulation skills applied to a large-scale real-world task: sorting recyclables and trash in office buildings. Real-world deployment of deep RL policies requires not only effective training algorithms, but the ability to bootstrap real-world training and enable broad generalization. To this end, our system combines scalable deep RL from real-world data with bootstrapping from training in simulation, and incorporates auxiliary inputs from existing computer vision systems as a way to boost generalization to novel objects, while retaining the benefits of end-to-end training. We analyze the tradeoffs of different design decisions in our system, and present a large-scale empirical validation that includes training on real-world data gathered over the course of 24 months of experimentation, across a fleet of 23 robots in three office buildings, with a total training set of 9527 hours of robotic experience. Our final validation also consists of 4800 evaluation trials across 240 waste station configurations, in order to evaluate in detail the impact of the design decisions in our system, the scaling effects of including more real-world data, and the performance of the method on novel objects. The projects website and videos can be found at \href{http://rl-at-scale.github.io}{rl-at-scale.github.io}.
Proactive Query Expansion for Streaming Data Using External Source
Jan 17, 2022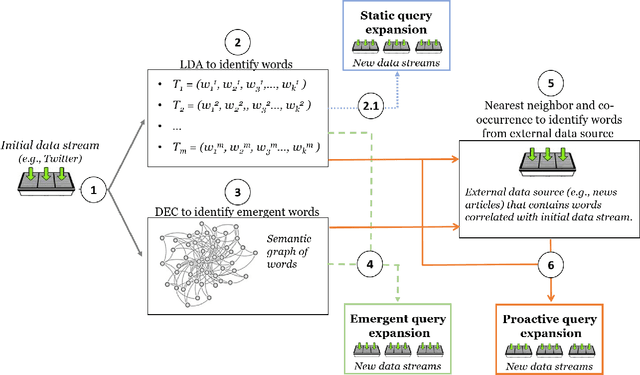
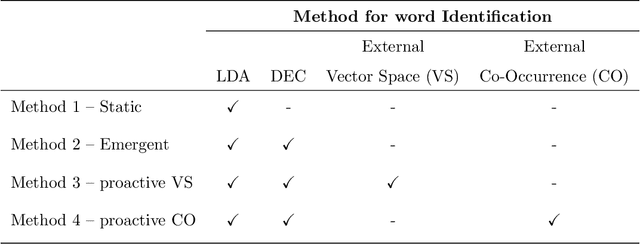

Query expansion is the process of reformulating the original query by adding relevant words. Choosing which terms to add in order to improve the performance of the query expansion methods or to enhance the quality of the retrieved results is an important aspect of any information retrieval system. Adding words that can positively impact the quality of the search query or are informative enough play an important role in returning or gathering relevant documents that cover a certain topic can result in improving the efficiency of the information retrieval system. Typically, query expansion techniques are used to add or substitute words to a given search query to collect relevant data. In this paper, we design and implement a pipeline of automated query expansion. We outline several tools using different methods to expand the query. Our methods depend on targeting emergent events in streaming data over time and finding the hidden topics from targeted documents using probabilistic topic models. We employ Dynamic Eigenvector Centrality to trigger the emergent events, and the Latent Dirichlet Allocation to discover the topics. Also, we use an external data source as a secondary stream to supplement the primary stream with relevant words and expand the query using the words from both primary and secondary streams. An experimental study is performed on Twitter data (primary stream) related to the events that happened during protests in Baltimore in 2015. The quality of the retrieved results was measured using a quality indicator of the streaming data: tweets count, hashtag count, and hashtag clustering.
AW-Opt: Learning Robotic Skills with Imitation and Reinforcement at Scale
Nov 11, 2021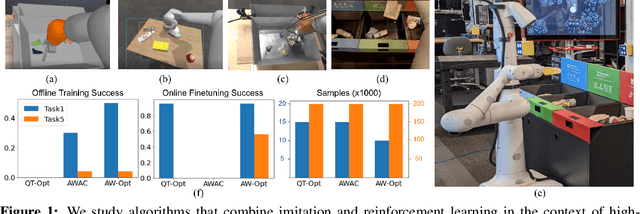
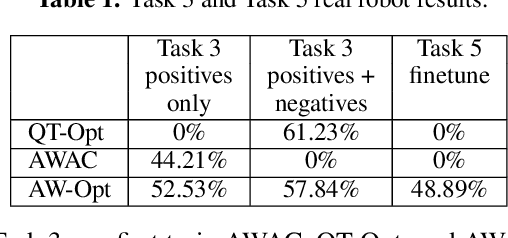
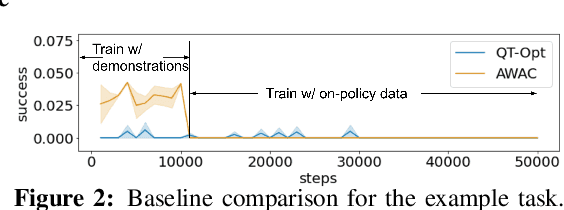
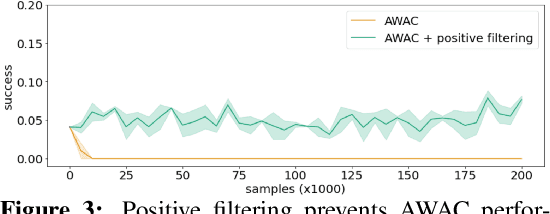
Robotic skills can be learned via imitation learning (IL) using user-provided demonstrations, or via reinforcement learning (RL) using large amountsof autonomously collected experience.Both methods have complementarystrengths and weaknesses: RL can reach a high level of performance, but requiresexploration, which can be very time consuming and unsafe; IL does not requireexploration, but only learns skills that are as good as the provided demonstrations.Can a single method combine the strengths of both approaches? A number ofprior methods have aimed to address this question, proposing a variety of tech-niques that integrate elements of IL and RL. However, scaling up such methodsto complex robotic skills that integrate diverse offline data and generalize mean-ingfully to real-world scenarios still presents a major challenge. In this paper, ouraim is to test the scalability of prior IL + RL algorithms and devise a system basedon detailed empirical experimentation that combines existing components in themost effective and scalable way. To that end, we present a series of experimentsaimed at understanding the implications of each design decision, so as to develop acombined approach that can utilize demonstrations and heterogeneous prior datato attain the best performance on a range of real-world and realistic simulatedrobotic problems. Our complete method, which we call AW-Opt, combines ele-ments of advantage-weighted regression [1, 2] and QT-Opt [3], providing a unifiedapproach for integrating demonstrations and offline data for robotic manipulation.Please see https://awopt.github.io for more details.
COCOI: Contact-aware Online Context Inference for Generalizable Non-planar Pushing
Nov 23, 2020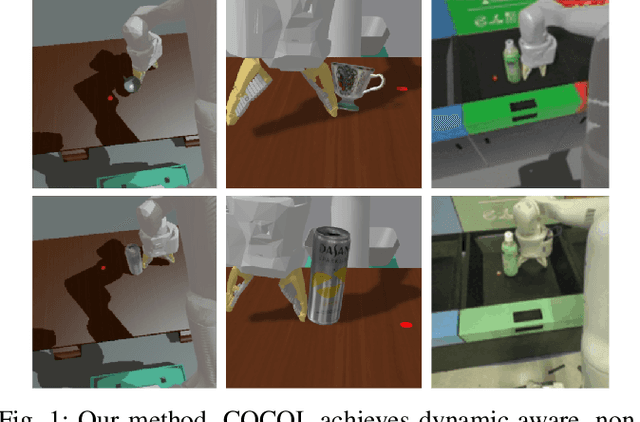
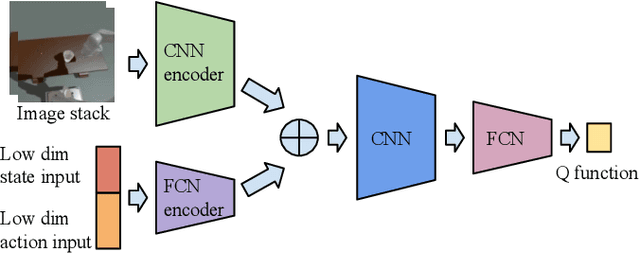
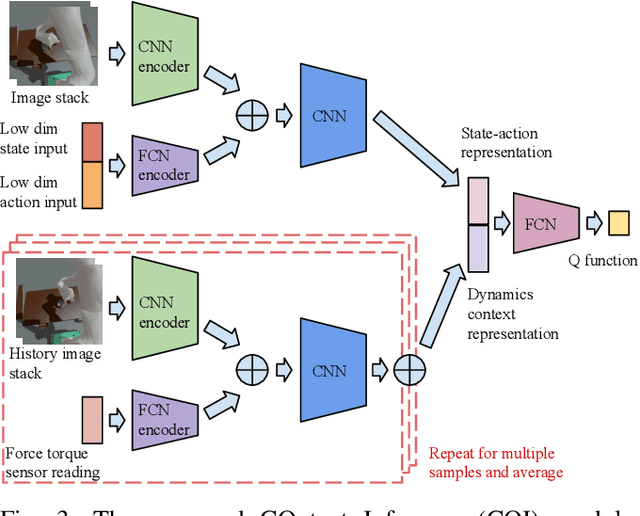
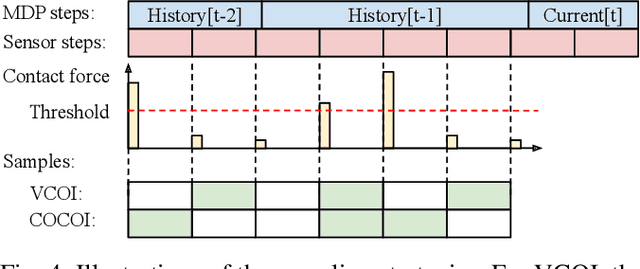
General contact-rich manipulation problems are long-standing challenges in robotics due to the difficulty of understanding complicated contact physics. Deep reinforcement learning (RL) has shown great potential in solving robot manipulation tasks. However, existing RL policies have limited adaptability to environments with diverse dynamics properties, which is pivotal in solving many contact-rich manipulation tasks. In this work, we propose Contact-aware Online COntext Inference (COCOI), a deep RL method that encodes a context embedding of dynamics properties online using contact-rich interactions. We study this method based on a novel and challenging non-planar pushing task, where the robot uses a monocular camera image and wrist force torque sensor reading to push an object to a goal location while keeping it upright. We run extensive experiments to demonstrate the capability of COCOI in a wide range of settings and dynamics properties in simulation, and also in a sim-to-real transfer scenario on a real robot (Video: https://youtu.be/nrmJYksh1Kc)
Accelerating Text Mining Using Domain-Specific Stop Word Lists
Nov 18, 2020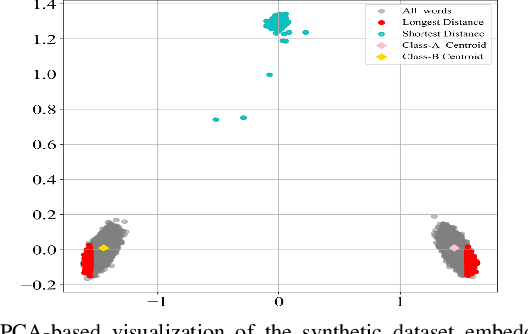
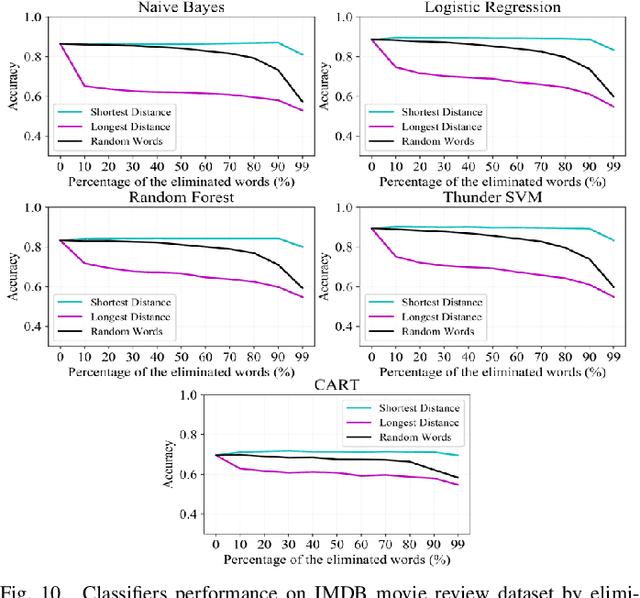
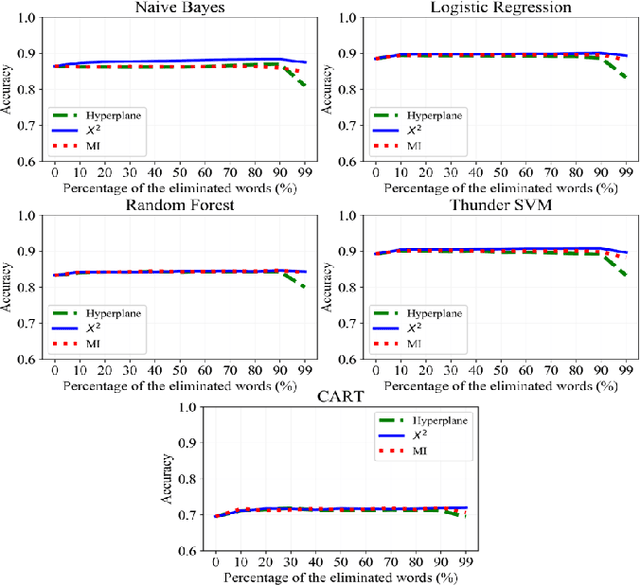
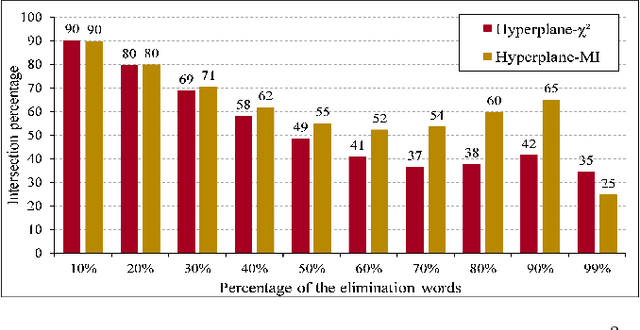
Text preprocessing is an essential step in text mining. Removing words that can negatively impact the quality of prediction algorithms or are not informative enough is a crucial storage-saving technique in text indexing and results in improved computational efficiency. Typically, a generic stop word list is applied to a dataset regardless of the domain. However, many common words are different from one domain to another but have no significance within a particular domain. Eliminating domain-specific common words in a corpus reduces the dimensionality of the feature space, and improves the performance of text mining tasks. In this paper, we present a novel mathematical approach for the automatic extraction of domain-specific words called the hyperplane-based approach. This new approach depends on the notion of low dimensional representation of the word in vector space and its distance from hyperplane. The hyperplane-based approach can significantly reduce text dimensionality by eliminating irrelevant features. We compare the hyperplane-based approach with other feature selection methods, namely \c{hi}2 and mutual information. An experimental study is performed on three different datasets and five classification algorithms, and measure the dimensionality reduction and the increase in the classification performance. Results indicate that the hyperplane-based approach can reduce the dimensionality of the corpus by 90% and outperforms mutual information. The computational time to identify the domain-specific words is significantly lower than mutual information.