 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProactive Query Expansion for Streaming Data Using External Source
Jan 17, 2022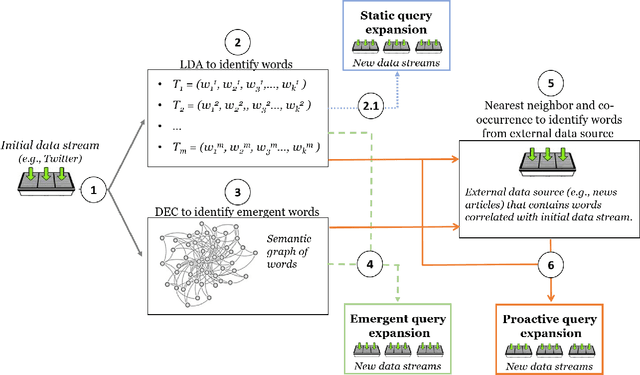
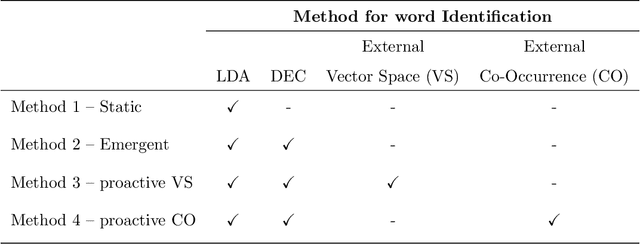

Query expansion is the process of reformulating the original query by adding relevant words. Choosing which terms to add in order to improve the performance of the query expansion methods or to enhance the quality of the retrieved results is an important aspect of any information retrieval system. Adding words that can positively impact the quality of the search query or are informative enough play an important role in returning or gathering relevant documents that cover a certain topic can result in improving the efficiency of the information retrieval system. Typically, query expansion techniques are used to add or substitute words to a given search query to collect relevant data. In this paper, we design and implement a pipeline of automated query expansion. We outline several tools using different methods to expand the query. Our methods depend on targeting emergent events in streaming data over time and finding the hidden topics from targeted documents using probabilistic topic models. We employ Dynamic Eigenvector Centrality to trigger the emergent events, and the Latent Dirichlet Allocation to discover the topics. Also, we use an external data source as a secondary stream to supplement the primary stream with relevant words and expand the query using the words from both primary and secondary streams. An experimental study is performed on Twitter data (primary stream) related to the events that happened during protests in Baltimore in 2015. The quality of the retrieved results was measured using a quality indicator of the streaming data: tweets count, hashtag count, and hashtag clustering.
Accelerating Text Mining Using Domain-Specific Stop Word Lists
Nov 18, 2020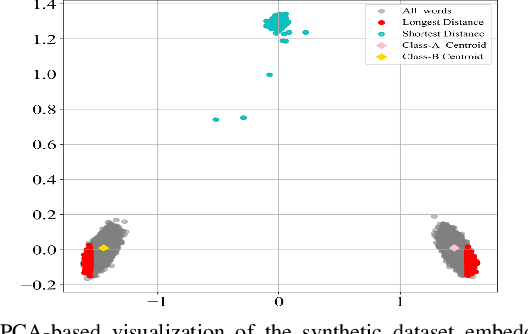
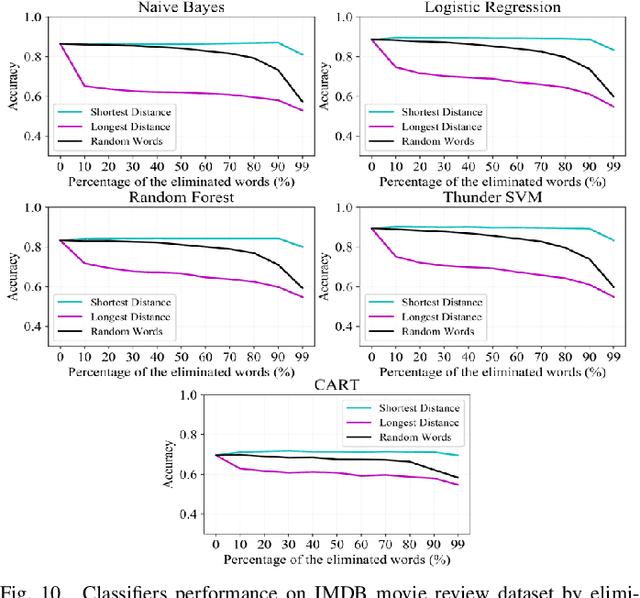
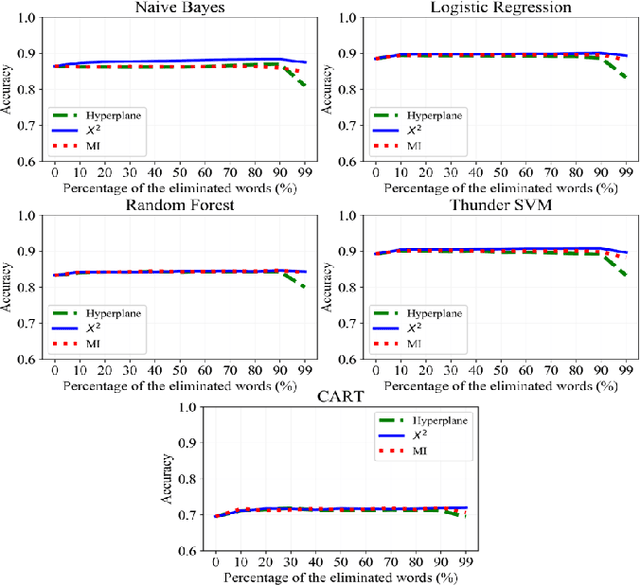
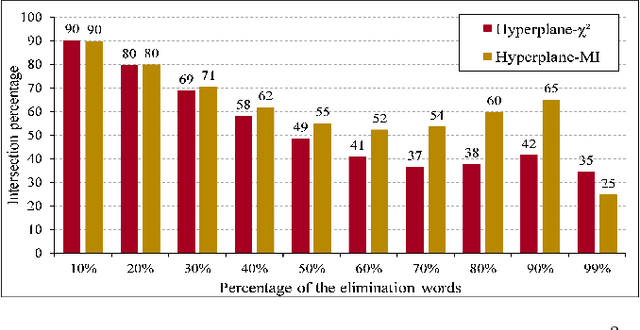
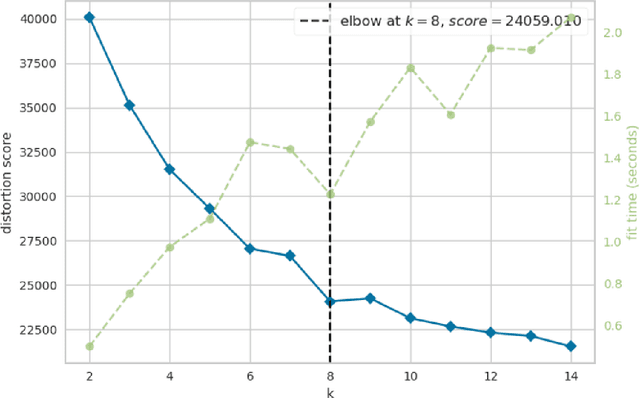
Text preprocessing is an essential step in text mining. Removing words that can negatively impact the quality of prediction algorithms or are not informative enough is a crucial storage-saving technique in text indexing and results in improved computational efficiency. Typically, a generic stop word list is applied to a dataset regardless of the domain. However, many common words are different from one domain to another but have no significance within a particular domain. Eliminating domain-specific common words in a corpus reduces the dimensionality of the feature space, and improves the performance of text mining tasks. In this paper, we present a novel mathematical approach for the automatic extraction of domain-specific words called the hyperplane-based approach. This new approach depends on the notion of low dimensional representation of the word in vector space and its distance from hyperplane. The hyperplane-based approach can significantly reduce text dimensionality by eliminating irrelevant features. We compare the hyperplane-based approach with other feature selection methods, namely \c{hi}2 and mutual information. An experimental study is performed on three different datasets and five classification algorithms, and measure the dimensionality reduction and the increase in the classification performance. Results indicate that the hyperplane-based approach can reduce the dimensionality of the corpus by 90% and outperforms mutual information. The computational time to identify the domain-specific words is significantly lower than mutual information.