 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Action Models are Zero-shot Policies
Feb 17, 2026State-of-the-art Vision-Language-Action (VLA) models excel at semantic generalization but struggle to generalize to unseen physical motions in novel environments. We introduce DreamZero, a World Action Model (WAM) built upon a pretrained video diffusion backbone. Unlike VLAs, WAMs learn physical dynamics by predicting future world states and actions, using video as a dense representation of how the world evolves. By jointly modeling video and action, DreamZero learns diverse skills effectively from heterogeneous robot data without relying on repetitive demonstrations. This results in over 2x improvement in generalization to new tasks and environments compared to state-of-the-art VLAs in real robot experiments. Crucially, through model and system optimizations, we enable a 14B autoregressive video diffusion model to perform real-time closed-loop control at 7Hz. Finally, we demonstrate two forms of cross-embodiment transfer: video-only demonstrations from other robots or humans yield a relative improvement of over 42% on unseen task performance with just 10-20 minutes of data. More surprisingly, DreamZero enables few-shot embodiment adaptation, transferring to a new embodiment with only 30 minutes of play data while retaining zero-shot generalization.
Stop Regressing: Training Value Functions via Classification for Scalable Deep RL
Mar 06, 2024



Value functions are a central component of deep reinforcement learning (RL). These functions, parameterized by neural networks, are trained using a mean squared error regression objective to match bootstrapped target values. However, scaling value-based RL methods that use regression to large networks, such as high-capacity Transformers, has proven challenging. This difficulty is in stark contrast to supervised learning: by leveraging a cross-entropy classification loss, supervised methods have scaled reliably to massive networks. Observing this discrepancy, in this paper, we investigate whether the scalability of deep RL can also be improved simply by using classification in place of regression for training value functions. We demonstrate that value functions trained with categorical cross-entropy significantly improves performance and scalability in a variety of domains. These include: single-task RL on Atari 2600 games with SoftMoEs, multi-task RL on Atari with large-scale ResNets, robotic manipulation with Q-transformers, playing Chess without search, and a language-agent Wordle task with high-capacity Transformers, achieving state-of-the-art results on these domains. Through careful analysis, we show that the benefits of categorical cross-entropy primarily stem from its ability to mitigate issues inherent to value-based RL, such as noisy targets and non-stationarity. Overall, we argue that a simple shift to training value functions with categorical cross-entropy can yield substantial improvements in the scalability of deep RL at little-to-no cost.
RT-H: Action Hierarchies Using Language
Mar 04, 2024



Language provides a way to break down complex concepts into digestible pieces. Recent works in robot imitation learning use language-conditioned policies that predict actions given visual observations and the high-level task specified in language. These methods leverage the structure of natural language to share data between semantically similar tasks (e.g., "pick coke can" and "pick an apple") in multi-task datasets. However, as tasks become more semantically diverse (e.g., "pick coke can" and "pour cup"), sharing data between tasks becomes harder, so learning to map high-level tasks to actions requires much more demonstration data. To bridge tasks and actions, our insight is to teach the robot the language of actions, describing low-level motions with more fine-grained phrases like "move arm forward". Predicting these language motions as an intermediate step between tasks and actions forces the policy to learn the shared structure of low-level motions across seemingly disparate tasks. Furthermore, a policy that is conditioned on language motions can easily be corrected during execution through human-specified language motions. This enables a new paradigm for flexible policies that can learn from human intervention in language. Our method RT-H builds an action hierarchy using language motions: it first learns to predict language motions, and conditioned on this and the high-level task, it predicts actions, using visual context at all stages. We show that RT-H leverages this language-action hierarchy to learn policies that are more robust and flexible by effectively tapping into multi-task datasets. We show that these policies not only allow for responding to language interventions, but can also learn from such interventions and outperform methods that learn from teleoperated interventions. Our website and videos are found at https://rt-hierarchy.github.io.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Robotic Offline RL from Internet Videos via Value-Function Pre-Training
Sep 22, 2023Pre-training on Internet data has proven to be a key ingredient for broad generalization in many modern ML systems. What would it take to enable such capabilities in robotic reinforcement learning (RL)? Offline RL methods, which learn from datasets of robot experience, offer one way to leverage prior data into the robotic learning pipeline. However, these methods have a "type mismatch" with video data (such as Ego4D), the largest prior datasets available for robotics, since video offers observation-only experience without the action or reward annotations needed for RL methods. In this paper, we develop a system for leveraging large-scale human video datasets in robotic offline RL, based entirely on learning value functions via temporal-difference learning. We show that value learning on video datasets learns representations that are more conducive to downstream robotic offline RL than other approaches for learning from video data. Our system, called V-PTR, combines the benefits of pre-training on video data with robotic offline RL approaches that train on diverse robot data, resulting in value functions and policies for manipulation tasks that perform better, act robustly, and generalize broadly. On several manipulation tasks on a real WidowX robot, our framework produces policies that greatly improve over prior methods. Our video and additional details can be found at https://dibyaghosh.com/vptr/
Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions
Sep 18, 2023



In this work, we present a scalable reinforcement learning method for training multi-task policies from large offline datasets that can leverage both human demonstrations and autonomously collected data. Our method uses a Transformer to provide a scalable representation for Q-functions trained via offline temporal difference backups. We therefore refer to the method as Q-Transformer. By discretizing each action dimension and representing the Q-value of each action dimension as separate tokens, we can apply effective high-capacity sequence modeling techniques for Q-learning. We present several design decisions that enable good performance with offline RL training, and show that Q-Transformer outperforms prior offline RL algorithms and imitation learning techniques on a large diverse real-world robotic manipulation task suite. The project's website and videos can be found at https://q-transformer.github.io
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Jul 28, 2023We study how vision-language models trained on Internet-scale data can be incorporated directly into end-to-end robotic control to boost generalization and enable emergent semantic reasoning. Our goal is to enable a single end-to-end trained model to both learn to map robot observations to actions and enjoy the benefits of large-scale pretraining on language and vision-language data from the web. To this end, we propose to co-fine-tune state-of-the-art vision-language models on both robotic trajectory data and Internet-scale vision-language tasks, such as visual question answering. In contrast to other approaches, we propose a simple, general recipe to achieve this goal: in order to fit both natural language responses and robotic actions into the same format, we express the actions as text tokens and incorporate them directly into the training set of the model in the same way as natural language tokens. We refer to such category of models as vision-language-action models (VLA) and instantiate an example of such a model, which we call RT-2. Our extensive evaluation (6k evaluation trials) shows that our approach leads to performant robotic policies and enables RT-2 to obtain a range of emergent capabilities from Internet-scale training. This includes significantly improved generalization to novel objects, the ability to interpret commands not present in the robot training data (such as placing an object onto a particular number or icon), and the ability to perform rudimentary reasoning in response to user commands (such as picking up the smallest or largest object, or the one closest to another object). We further show that incorporating chain of thought reasoning allows RT-2 to perform multi-stage semantic reasoning, for example figuring out which object to pick up for use as an improvised hammer (a rock), or which type of drink is best suited for someone who is tired (an energy drink).
Deep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators
May 05, 2023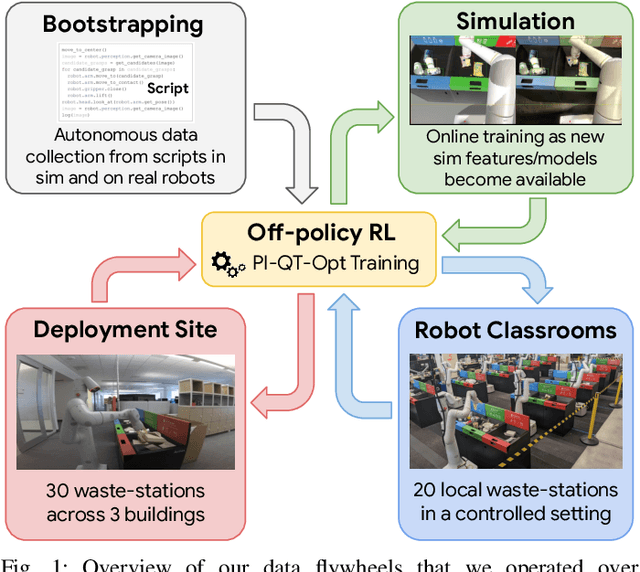


We describe a system for deep reinforcement learning of robotic manipulation skills applied to a large-scale real-world task: sorting recyclables and trash in office buildings. Real-world deployment of deep RL policies requires not only effective training algorithms, but the ability to bootstrap real-world training and enable broad generalization. To this end, our system combines scalable deep RL from real-world data with bootstrapping from training in simulation, and incorporates auxiliary inputs from existing computer vision systems as a way to boost generalization to novel objects, while retaining the benefits of end-to-end training. We analyze the tradeoffs of different design decisions in our system, and present a large-scale empirical validation that includes training on real-world data gathered over the course of 24 months of experimentation, across a fleet of 23 robots in three office buildings, with a total training set of 9527 hours of robotic experience. Our final validation also consists of 4800 evaluation trials across 240 waste station configurations, in order to evaluate in detail the impact of the design decisions in our system, the scaling effects of including more real-world data, and the performance of the method on novel objects. The projects website and videos can be found at \href{http://rl-at-scale.github.io}{rl-at-scale.github.io}.
PaLM-E: An Embodied Multimodal Language Model
Mar 06, 2023

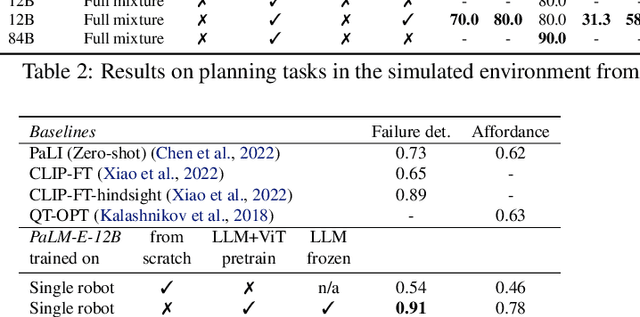

Large language models excel at a wide range of complex tasks. However, enabling general inference in the real world, e.g., for robotics problems, raises the challenge of grounding. We propose embodied language models to directly incorporate real-world continuous sensor modalities into language models and thereby establish the link between words and percepts. Input to our embodied language model are multi-modal sentences that interleave visual, continuous state estimation, and textual input encodings. We train these encodings end-to-end, in conjunction with a pre-trained large language model, for multiple embodied tasks including sequential robotic manipulation planning, visual question answering, and captioning. Our evaluations show that PaLM-E, a single large embodied multimodal model, can address a variety of embodied reasoning tasks, from a variety of observation modalities, on multiple embodiments, and further, exhibits positive transfer: the model benefits from diverse joint training across internet-scale language, vision, and visual-language domains. Our largest model, PaLM-E-562B with 562B parameters, in addition to being trained on robotics tasks, is a visual-language generalist with state-of-the-art performance on OK-VQA, and retains generalist language capabilities with increasing scale.
RT-1: Robotics Transformer for Real-World Control at Scale
Dec 13, 2022



By transferring knowledge from large, diverse, task-agnostic datasets, modern machine learning models can solve specific downstream tasks either zero-shot or with small task-specific datasets to a high level of performance. While this capability has been demonstrated in other fields such as computer vision, natural language processing or speech recognition, it remains to be shown in robotics, where the generalization capabilities of the models are particularly critical due to the difficulty of collecting real-world robotic data. We argue that one of the keys to the success of such general robotic models lies with open-ended task-agnostic training, combined with high-capacity architectures that can absorb all of the diverse, robotic data. In this paper, we present a model class, dubbed Robotics Transformer, that exhibits promising scalable model properties. We verify our conclusions in a study of different model classes and their ability to generalize as a function of the data size, model size, and data diversity based on a large-scale data collection on real robots performing real-world tasks. The project's website and videos can be found at robotics-transformer.github.io