 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Strategies for Efficient Embodied Reasoning
May 13, 2025Robot chain-of-thought reasoning (CoT) -- wherein a model predicts helpful intermediate representations before choosing actions -- provides an effective method for improving the generalization and performance of robot policies, especially vision-language-action models (VLAs). While such approaches have been shown to improve performance and generalization, they suffer from core limitations, like needing specialized robot reasoning data and slow inference speeds. To design new robot reasoning approaches that address these issues, a more complete characterization of why reasoning helps policy performance is critical. We hypothesize several mechanisms by which robot reasoning improves policies -- (1) better representation learning, (2) improved learning curricularization, and (3) increased expressivity -- then devise simple variants of robot CoT reasoning to isolate and test each one. We find that learning to generate reasonings does lead to better VLA representations, while attending to the reasonings aids in actually leveraging these features for improved action prediction. Our results provide us with a better understanding of why CoT reasoning helps VLAs, which we use to introduce two simple and lightweight alternative recipes for robot reasoning. Our proposed approaches achieve significant performance gains over non-reasoning policies, state-of-the-art results on the LIBERO-90 benchmark, and a 3x inference speedup compared to standard robot reasoning.
A Taxonomy for Evaluating Generalist Robot Policies
Mar 03, 2025


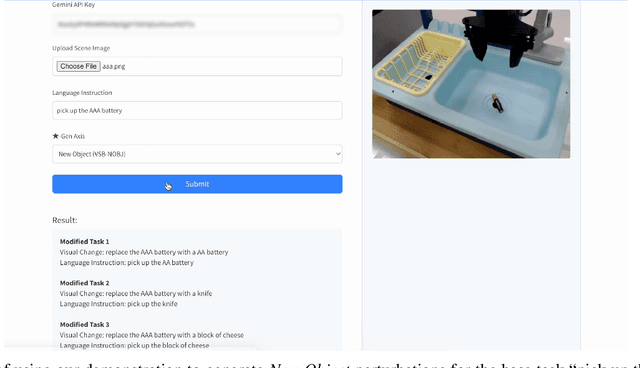
Machine learning for robotics promises to unlock generalization to novel tasks and environments. Guided by this promise, many recent works have focused on scaling up robot data collection and developing larger, more expressive policies to achieve this. But how do we measure progress towards this goal of policy generalization in practice? Evaluating and quantifying generalization is the Wild West of modern robotics, with each work proposing and measuring different types of generalization in their own, often difficult to reproduce, settings. In this work, our goal is (1) to outline the forms of generalization we believe are important in robot manipulation in a comprehensive and fine-grained manner, and (2) to provide reproducible guidelines for measuring these notions of generalization. We first propose STAR-Gen, a taxonomy of generalization for robot manipulation structured around visual, semantic, and behavioral generalization. We discuss how our taxonomy encompasses most prior notions of generalization in robotics. Next, we instantiate STAR-Gen with a concrete real-world benchmark based on the widely-used Bridge V2 dataset. We evaluate a variety of state-of-the-art models on this benchmark to demonstrate the utility of our taxonomy in practice. Our taxonomy of generalization can yield many interesting insights into existing models: for example, we observe that current vision-language-action models struggle with various types of semantic generalization, despite the promise of pre-training on internet-scale language datasets. We believe STAR-Gen and our guidelines can improve the dissemination and evaluation of progress towards generalization in robotics, which we hope will guide model design and future data collection efforts. We provide videos and demos at our website stargen-taxonomy.github.io.
Action-Free Reasoning for Policy Generalization
Feb 06, 2025



End-to-end imitation learning offers a promising approach for training robot policies. However, generalizing to new settings remains a significant challenge. Although large-scale robot demonstration datasets have shown potential for inducing generalization, they are resource-intensive to scale. In contrast, human video data is abundant and diverse, presenting an attractive alternative. Yet, these human-video datasets lack action labels, complicating their use in imitation learning. Existing methods attempt to extract grounded action representations (e.g., hand poses), but resulting policies struggle to bridge the embodiment gap between human and robot actions. We propose an alternative approach: leveraging language-based reasoning from human videos-essential for guiding robot actions-to train generalizable robot policies. Building on recent advances in reasoning-based policy architectures, we introduce Reasoning through Action-free Data (RAD). RAD learns from both robot demonstration data (with reasoning and action labels) and action-free human video data (with only reasoning labels). The robot data teaches the model to map reasoning to low-level actions, while the action-free data enhances reasoning capabilities. Additionally, we will release a new dataset of 3,377 human-hand demonstrations with reasoning annotations compatible with the Bridge V2 benchmark and aimed at facilitating future research on reasoning-driven robot learning. Our experiments show that RAD enables effective transfer across the embodiment gap, allowing robots to perform tasks seen only in action-free data. Furthermore, scaling up action-free reasoning data significantly improves policy performance and generalization to novel tasks. These results highlight the promise of reasoning-driven learning from action-free datasets for advancing generalizable robot control. Project page: https://rad-generalization.github.io
So You Think You Can Scale Up Autonomous Robot Data Collection?
Nov 04, 2024A long-standing goal in robot learning is to develop methods for robots to acquire new skills autonomously. While reinforcement learning (RL) comes with the promise of enabling autonomous data collection, it remains challenging to scale in the real-world partly due to the significant effort required for environment design and instrumentation, including the need for designing reset functions or accurate success detectors. On the other hand, imitation learning (IL) methods require little to no environment design effort, but instead require significant human supervision in the form of collected demonstrations. To address these shortcomings, recent works in autonomous IL start with an initial seed dataset of human demonstrations that an autonomous policy can bootstrap from. While autonomous IL approaches come with the promise of addressing the challenges of autonomous RL as well as pure IL strategies, in this work, we posit that such techniques do not deliver on this promise and are still unable to scale up autonomous data collection in the real world. Through a series of real-world experiments, we demonstrate that these approaches, when scaled up to realistic settings, face much of the same scaling challenges as prior attempts in RL in terms of environment design. Further, we perform a rigorous study of autonomous IL methods across different data scales and 7 simulation and real-world tasks, and demonstrate that while autonomous data collection can modestly improve performance, simply collecting more human data often provides significantly more improvement. Our work suggests a negative result: that scaling up autonomous data collection for learning robot policies for real-world tasks is more challenging and impractical than what is suggested in prior work. We hope these insights about the core challenges of scaling up data collection help inform future efforts in autonomous learning.
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
RT-H: Action Hierarchies Using Language
Mar 04, 2024



Language provides a way to break down complex concepts into digestible pieces. Recent works in robot imitation learning use language-conditioned policies that predict actions given visual observations and the high-level task specified in language. These methods leverage the structure of natural language to share data between semantically similar tasks (e.g., "pick coke can" and "pick an apple") in multi-task datasets. However, as tasks become more semantically diverse (e.g., "pick coke can" and "pour cup"), sharing data between tasks becomes harder, so learning to map high-level tasks to actions requires much more demonstration data. To bridge tasks and actions, our insight is to teach the robot the language of actions, describing low-level motions with more fine-grained phrases like "move arm forward". Predicting these language motions as an intermediate step between tasks and actions forces the policy to learn the shared structure of low-level motions across seemingly disparate tasks. Furthermore, a policy that is conditioned on language motions can easily be corrected during execution through human-specified language motions. This enables a new paradigm for flexible policies that can learn from human intervention in language. Our method RT-H builds an action hierarchy using language motions: it first learns to predict language motions, and conditioned on this and the high-level task, it predicts actions, using visual context at all stages. We show that RT-H leverages this language-action hierarchy to learn policies that are more robust and flexible by effectively tapping into multi-task datasets. We show that these policies not only allow for responding to language interventions, but can also learn from such interventions and outperform methods that learn from teleoperated interventions. Our website and videos are found at https://rt-hierarchy.github.io.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
KITE: Keypoint-Conditioned Policies for Semantic Manipulation
Jul 06, 2023



While natural language offers a convenient shared interface for humans and robots, enabling robots to interpret and follow language commands remains a longstanding challenge in manipulation. A crucial step to realizing a performant instruction-following robot is achieving semantic manipulation, where a robot interprets language at different specificities, from high-level instructions like "Pick up the stuffed animal" to more detailed inputs like "Grab the left ear of the elephant." To tackle this, we propose Keypoints + Instructions to Execution (KITE), a two-step framework for semantic manipulation which attends to both scene semantics (distinguishing between different objects in a visual scene) and object semantics (precisely localizing different parts within an object instance). KITE first grounds an input instruction in a visual scene through 2D image keypoints, providing a highly accurate object-centric bias for downstream action inference. Provided an RGB-D scene observation, KITE then executes a learned keypoint-conditioned skill to carry out the instruction. The combined precision of keypoints and parameterized skills enables fine-grained manipulation with generalization to scene and object variations. Empirically, we demonstrate KITE in 3 real-world environments: long-horizon 6-DoF tabletop manipulation, semantic grasping, and a high-precision coffee-making task. In these settings, KITE achieves a 75%, 70%, and 71% overall success rate for instruction-following, respectively. KITE outperforms frameworks that opt for pre-trained visual language models over keypoint-based grounding, or omit skills in favor of end-to-end visuomotor control, all while being trained from fewer or comparable amounts of demonstrations. Supplementary material, datasets, code, and videos can be found on our website: http://tinyurl.com/kite-site.
HYDRA: Hybrid Robot Actions for Imitation Learning
Jun 29, 2023Imitation Learning (IL) is a sample efficient paradigm for robot learning using expert demonstrations. However, policies learned through IL suffer from state distribution shift at test time, due to compounding errors in action prediction which lead to previously unseen states. Choosing an action representation for the policy that minimizes this distribution shift is critical in imitation learning. Prior work propose using temporal action abstractions to reduce compounding errors, but they often sacrifice policy dexterity or require domain-specific knowledge. To address these trade-offs, we introduce HYDRA, a method that leverages a hybrid action space with two levels of action abstractions: sparse high-level waypoints and dense low-level actions. HYDRA dynamically switches between action abstractions at test time to enable both coarse and fine-grained control of a robot. In addition, HYDRA employs action relabeling to increase the consistency of actions in the dataset, further reducing distribution shift. HYDRA outperforms prior imitation learning methods by 30-40% on seven challenging simulation and real world environments, involving long-horizon tasks in the real world like making coffee and toasting bread. Videos are found on our website: https://tinyurl.com/3mc6793z
Parallel Sampling of Diffusion Models
Jun 08, 2023



Diffusion models are powerful generative models but suffer from slow sampling, often taking 1000 sequential denoising steps for one sample. As a result, considerable efforts have been directed toward reducing the number of denoising steps, but these methods hurt sample quality. Instead of reducing the number of denoising steps (trading quality for speed), in this paper we explore an orthogonal approach: can we run the denoising steps in parallel (trading compute for speed)? In spite of the sequential nature of the denoising steps, we show that surprisingly it is possible to parallelize sampling via Picard iterations, by guessing the solution of future denoising steps and iteratively refining until convergence. With this insight, we present ParaDiGMS, a novel method to accelerate the sampling of pretrained diffusion models by denoising multiple steps in parallel. ParaDiGMS is the first diffusion sampling method that enables trading compute for speed and is even compatible with existing fast sampling techniques such as DDIM and DPMSolver. Using ParaDiGMS, we improve sampling speed by 2-4x across a range of robotics and image generation models, giving state-of-the-art sampling speeds of 0.2s on 100-step DiffusionPolicy and 16s on 1000-step StableDiffusion-v2 with no measurable degradation of task reward, FID score, or CLIP score.