 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolaRiS: Scalable Real-to-Sim Evaluations for Generalist Robot Policies
Dec 18, 2025A significant challenge for robot learning research is our ability to accurately measure and compare the performance of robot policies. Benchmarking in robotics is historically challenging due to the stochasticity, reproducibility, and time-consuming nature of real-world rollouts. This challenge is exacerbated for recent generalist policies, which has to be evaluated across a wide variety of scenes and tasks. Evaluation in simulation offers a scalable complement to real world evaluations, but the visual and physical domain gap between existing simulation benchmarks and the real world has made them an unreliable signal for policy improvement. Furthermore, building realistic and diverse simulated environments has traditionally required significant human effort and expertise. To bridge the gap, we introduce Policy Evaluation and Environment Reconstruction in Simulation (PolaRiS), a scalable real-to-sim framework for high-fidelity simulated robot evaluation. PolaRiS utilizes neural reconstruction methods to turn short video scans of real-world scenes into interactive simulation environments. Additionally, we develop a simple simulation data co-training recipe that bridges remaining real-to-sim gaps and enables zero-shot evaluation in unseen simulation environments. Through extensive paired evaluations between simulation and the real world, we demonstrate that PolaRiS evaluations provide a much stronger correlation to real world generalist policy performance than existing simulated benchmarks. Its simplicity also enables rapid creation of diverse simulated environments. As such, this work takes a step towards distributed and democratized evaluation for the next generation of robotic foundation models.
Evaluating Gemini Robotics Policies in a Veo World Simulator
Dec 11, 2025Generative world models hold significant potential for simulating interactions with visuomotor policies in varied environments. Frontier video models can enable generation of realistic observations and environment interactions in a scalable and general manner. However, the use of video models in robotics has been limited primarily to in-distribution evaluations, i.e., scenarios that are similar to ones used to train the policy or fine-tune the base video model. In this report, we demonstrate that video models can be used for the entire spectrum of policy evaluation use cases in robotics: from assessing nominal performance to out-of-distribution (OOD) generalization, and probing physical and semantic safety. We introduce a generative evaluation system built upon a frontier video foundation model (Veo). The system is optimized to support robot action conditioning and multi-view consistency, while integrating generative image-editing and multi-view completion to synthesize realistic variations of real-world scenes along multiple axes of generalization. We demonstrate that the system preserves the base capabilities of the video model to enable accurate simulation of scenes that have been edited to include novel interaction objects, novel visual backgrounds, and novel distractor objects. This fidelity enables accurately predicting the relative performance of different policies in both nominal and OOD conditions, determining the relative impact of different axes of generalization on policy performance, and performing red teaming of policies to expose behaviors that violate physical or semantic safety constraints. We validate these capabilities through 1600+ real-world evaluations of eight Gemini Robotics policy checkpoints and five tasks for a bimanual manipulator.
What Matters in RL-Based Methods for Object-Goal Navigation? An Empirical Study and A Unified Framework
Oct 02, 2025
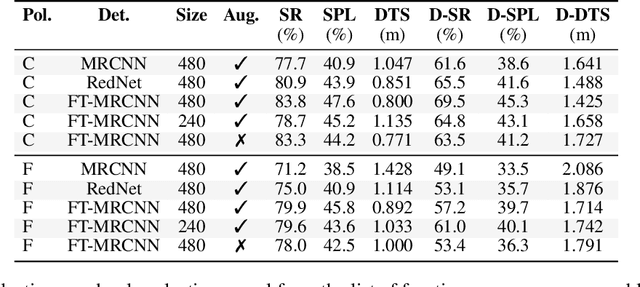
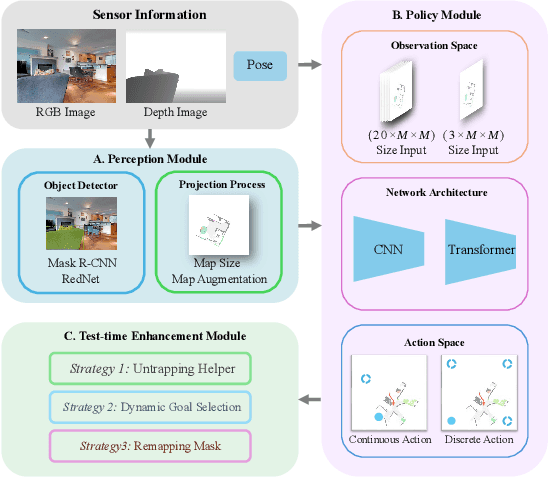
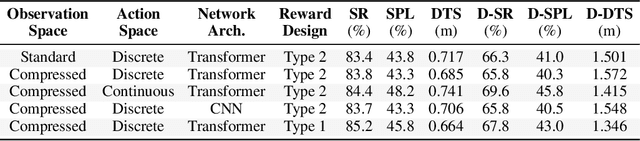
Object-Goal Navigation (ObjectNav) is a critical component toward deploying mobile robots in everyday, uncontrolled environments such as homes, schools, and workplaces. In this context, a robot must locate target objects in previously unseen environments using only its onboard perception. Success requires the integration of semantic understanding, spatial reasoning, and long-horizon planning, which is a combination that remains extremely challenging. While reinforcement learning (RL) has become the dominant paradigm, progress has spanned a wide range of design choices, yet the field still lacks a unifying analysis to determine which components truly drive performance. In this work, we conduct a large-scale empirical study of modular RL-based ObjectNav systems, decomposing them into three key components: perception, policy, and test-time enhancement. Through extensive controlled experiments, we isolate the contribution of each and uncover clear trends: perception quality and test-time strategies are decisive drivers of performance, whereas policy improvements with current methods yield only marginal gains. Building on these insights, we propose practical design guidelines and demonstrate an enhanced modular system that surpasses State-of-the-Art (SotA) methods by 6.6% on SPL and by a 2.7% success rate. We also introduce a human baseline under identical conditions, where experts achieve an average 98% success, underscoring the gap between RL agents and human-level navigation. Our study not only sets the SotA performance but also provides principled guidance for future ObjectNav development and evaluation.
Bridging Perception and Action: Spatially-Grounded Mid-Level Representations for Robot Generalization
Jun 06, 2025In this work, we investigate how spatially grounded auxiliary representations can provide both broad, high-level grounding as well as direct, actionable information to improve policy learning performance and generalization for dexterous tasks. We study these mid-level representations across three critical dimensions: object-centricity, pose-awareness, and depth-awareness. We use these interpretable mid-level representations to train specialist encoders via supervised learning, then feed them as inputs to a diffusion policy to solve dexterous bimanual manipulation tasks in the real world. We propose a novel mixture-of-experts policy architecture that combines multiple specialized expert models, each trained on a distinct mid-level representation, to improve policy generalization. This method achieves an average success rate that is 11% higher than a language-grounded baseline and 24 percent higher than a standard diffusion policy baseline on our evaluation tasks. Furthermore, we find that leveraging mid-level representations as supervision signals for policy actions within a weighted imitation learning algorithm improves the precision with which the policy follows these representations, yielding an additional performance increase of 10%. Our findings highlight the importance of grounding robot policies not only with broad perceptual tasks but also with more granular, actionable representations. For further information and videos, please visit https://mid-level-moe.github.io.
Guiding Data Collection via Factored Scaling Curves
May 12, 2025Generalist imitation learning policies trained on large datasets show great promise for solving diverse manipulation tasks. However, to ensure generalization to different conditions, policies need to be trained with data collected across a large set of environmental factor variations (e.g., camera pose, table height, distractors) $-$ a prohibitively expensive undertaking, if done exhaustively. We introduce a principled method for deciding what data to collect and how much to collect for each factor by constructing factored scaling curves (FSC), which quantify how policy performance varies as data scales along individual or paired factors. These curves enable targeted data acquisition for the most influential factor combinations within a given budget. We evaluate the proposed method through extensive simulated and real-world experiments, across both training-from-scratch and fine-tuning settings, and show that it boosts success rates in real-world tasks in new environments by up to 26% over existing data-collection strategies. We further demonstrate how factored scaling curves can effectively guide data collection using an offline metric, without requiring real-world evaluation at scale.
Learning to Drive Anywhere with Model-Based Reannotation11
May 08, 2025Developing broadly generalizable visual navigation policies for robots is a significant challenge, primarily constrained by the availability of large-scale, diverse training data. While curated datasets collected by researchers offer high quality, their limited size restricts policy generalization. To overcome this, we explore leveraging abundant, passively collected data sources, including large volumes of crowd-sourced teleoperation data and unlabeled YouTube videos, despite their potential for lower quality or missing action labels. We propose Model-Based ReAnnotation (MBRA), a framework that utilizes a learned short-horizon, model-based expert model to relabel or generate high-quality actions for these passive datasets. This relabeled data is then distilled into LogoNav, a long-horizon navigation policy conditioned on visual goals or GPS waypoints. We demonstrate that LogoNav, trained using MBRA-processed data, achieves state-of-the-art performance, enabling robust navigation over distances exceeding 300 meters in previously unseen indoor and outdoor environments. Our extensive real-world evaluations, conducted across a fleet of robots (including quadrupeds) in six cities on three continents, validate the policy's ability to generalize and navigate effectively even amidst pedestrians in crowded settings.
ResearchCodeAgent: An LLM Multi-Agent System for Automated Codification of Research Methodologies
Apr 28, 2025
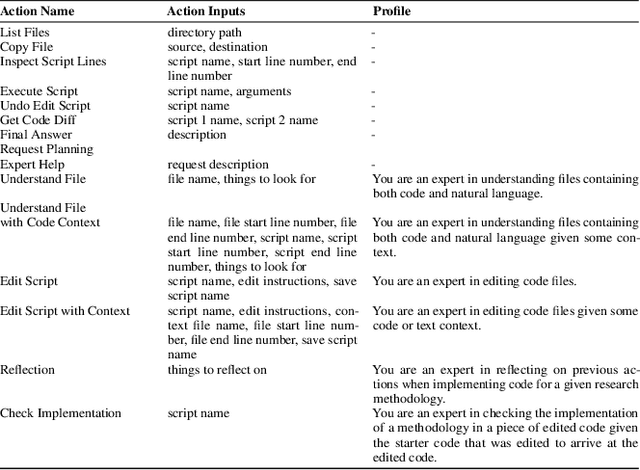
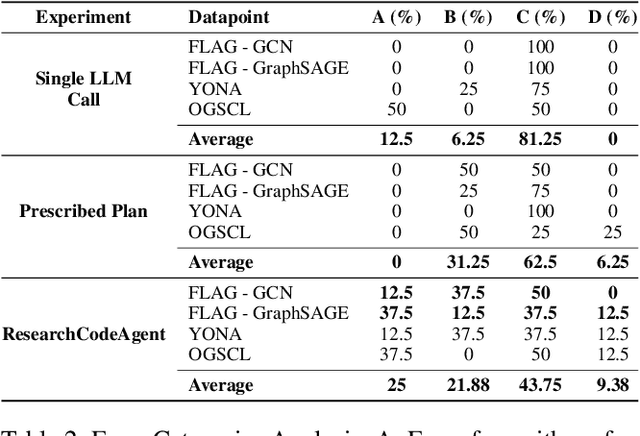
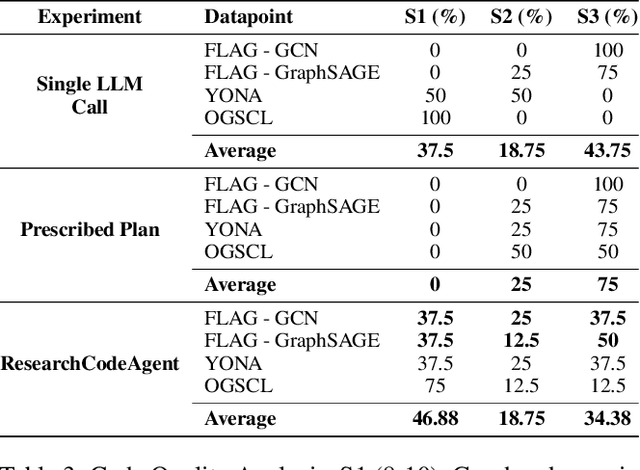
In this paper we introduce ResearchCodeAgent, a novel multi-agent system leveraging large language models (LLMs) agents to automate the codification of research methodologies described in machine learning literature. The system bridges the gap between high-level research concepts and their practical implementation, allowing researchers auto-generating code of existing research papers for benchmarking or building on top-of existing methods specified in the literature with availability of partial or complete starter code. ResearchCodeAgent employs a flexible agent architecture with a comprehensive action suite, enabling context-aware interactions with the research environment. The system incorporates a dynamic planning mechanism, utilizing both short and long-term memory to adapt its approach iteratively. We evaluate ResearchCodeAgent on three distinct machine learning tasks with distinct task complexity and representing different parts of the ML pipeline: data augmentation, optimization, and data batching. Our results demonstrate the system's effectiveness and generalizability, with 46.9% of generated code being high-quality and error-free, and 25% showing performance improvements over baseline implementations. Empirical analysis shows an average reduction of 57.9% in coding time compared to manual implementation. We observe higher gains for more complex tasks. ResearchCodeAgent represents a significant step towards automating the research implementation process, potentially accelerating the pace of machine learning research.
Gemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
A Taxonomy for Evaluating Generalist Robot Policies
Mar 03, 2025Machine learning for robotics promises to unlock generalization to novel tasks and environments. Guided by this promise, many recent works have focused on scaling up robot data collection and developing larger, more expressive policies to achieve this. But how do we measure progress towards this goal of policy generalization in practice? Evaluating and quantifying generalization is the Wild West of modern robotics, with each work proposing and measuring different types of generalization in their own, often difficult to reproduce, settings. In this work, our goal is (1) to outline the forms of generalization we believe are important in robot manipulation in a comprehensive and fine-grained manner, and (2) to provide reproducible guidelines for measuring these notions of generalization. We first propose STAR-Gen, a taxonomy of generalization for robot manipulation structured around visual, semantic, and behavioral generalization. We discuss how our taxonomy encompasses most prior notions of generalization in robotics. Next, we instantiate STAR-Gen with a concrete real-world benchmark based on the widely-used Bridge V2 dataset. We evaluate a variety of state-of-the-art models on this benchmark to demonstrate the utility of our taxonomy in practice. Our taxonomy of generalization can yield many interesting insights into existing models: for example, we observe that current vision-language-action models struggle with various types of semantic generalization, despite the promise of pre-training on internet-scale language datasets. We believe STAR-Gen and our guidelines can improve the dissemination and evaluation of progress towards generalization in robotics, which we hope will guide model design and future data collection efforts. We provide videos and demos at our website stargen-taxonomy.github.io.
Robot Data Curation with Mutual Information Estimators
Feb 12, 2025The performance of imitation learning policies often hinges on the datasets with which they are trained. Consequently, investment in data collection for robotics has grown across both industrial and academic labs. However, despite the marked increase in the quantity of demonstrations collected, little work has sought to assess the quality of said data despite mounting evidence of its importance in other areas such as vision and language. In this work, we take a critical step towards addressing the data quality in robotics. Given a dataset of demonstrations, we aim to estimate the relative quality of individual demonstrations in terms of both state diversity and action predictability. To do so, we estimate the average contribution of a trajectory towards the mutual information between states and actions in the entire dataset, which precisely captures both the entropy of the state distribution and the state-conditioned entropy of actions. Though commonly used mutual information estimators require vast amounts of data often beyond the scale available in robotics, we introduce a novel technique based on k-nearest neighbor estimates of mutual information on top of simple VAE embeddings of states and actions. Empirically, we demonstrate that our approach is able to partition demonstration datasets by quality according to human expert scores across a diverse set of benchmarks spanning simulation and real world environments. Moreover, training policies based on data filtered by our method leads to a 5-10% improvement in RoboMimic and better performance on real ALOHA and Franka setups.