 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposer 2 Technical Report
Mar 25, 2026Composer 2 is a specialized model designed for agentic software engineering. The model demonstrates strong long-term planning and coding intelligence while maintaining the ability to efficiently solve problems for interactive use. The model is trained in two phases: first, continued pretraining to improve the model's knowledge and latent coding ability, followed by large-scale reinforcement learning to improve end-to-end coding performance through stronger reasoning, accurate multi-step execution, and coherence on long-horizon realistic coding problems. We develop infrastructure to support training in the same Cursor harness that is used by the deployed model, with equivalent tools and structure, and use environments that match real problems closely. To measure the ability of the model on increasingly difficult tasks, we introduce a benchmark derived from real software engineering problems in large codebases including our own. Composer 2 is a frontier-level coding model and demonstrates a process for training strong domain-specialized models. On our CursorBench evaluations the model achieves a major improvement in accuracy compared to previous Composer models (61.3). On public benchmarks the model scores 61.7 on Terminal-Bench and 73.7 on SWE-bench Multilingual in our harness, comparable to state-of-the-art systems.
Scaffolding Dexterous Manipulation with Vision-Language Models
Jun 24, 2025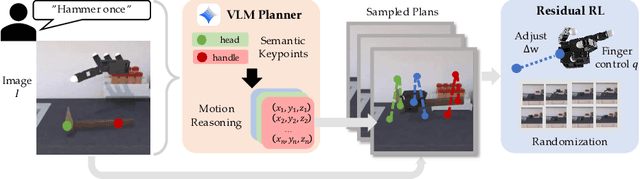
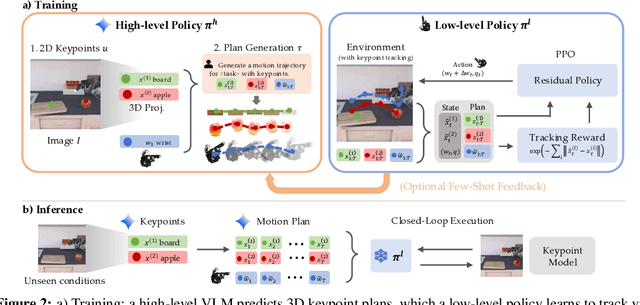
Dexterous robotic hands are essential for performing complex manipulation tasks, yet remain difficult to train due to the challenges of demonstration collection and high-dimensional control. While reinforcement learning (RL) can alleviate the data bottleneck by generating experience in simulation, it typically relies on carefully designed, task-specific reward functions, which hinder scalability and generalization. Thus, contemporary works in dexterous manipulation have often bootstrapped from reference trajectories. These trajectories specify target hand poses that guide the exploration of RL policies and object poses that enable dense, task-agnostic rewards. However, sourcing suitable trajectories - particularly for dexterous hands - remains a significant challenge. Yet, the precise details in explicit reference trajectories are often unnecessary, as RL ultimately refines the motion. Our key insight is that modern vision-language models (VLMs) already encode the commonsense spatial and semantic knowledge needed to specify tasks and guide exploration effectively. Given a task description (e.g., "open the cabinet") and a visual scene, our method uses an off-the-shelf VLM to first identify task-relevant keypoints (e.g., handles, buttons) and then synthesize 3D trajectories for hand motion and object motion. Subsequently, we train a low-level residual RL policy in simulation to track these coarse trajectories or "scaffolds" with high fidelity. Across a number of simulated tasks involving articulated objects and semantic understanding, we demonstrate that our method is able to learn robust dexterous manipulation policies. Moreover, we showcase that our method transfers to real-world robotic hands without any human demonstrations or handcrafted rewards.
Robot Data Curation with Mutual Information Estimators
Feb 12, 2025The performance of imitation learning policies often hinges on the datasets with which they are trained. Consequently, investment in data collection for robotics has grown across both industrial and academic labs. However, despite the marked increase in the quantity of demonstrations collected, little work has sought to assess the quality of said data despite mounting evidence of its importance in other areas such as vision and language. In this work, we take a critical step towards addressing the data quality in robotics. Given a dataset of demonstrations, we aim to estimate the relative quality of individual demonstrations in terms of both state diversity and action predictability. To do so, we estimate the average contribution of a trajectory towards the mutual information between states and actions in the entire dataset, which precisely captures both the entropy of the state distribution and the state-conditioned entropy of actions. Though commonly used mutual information estimators require vast amounts of data often beyond the scale available in robotics, we introduce a novel technique based on k-nearest neighbor estimates of mutual information on top of simple VAE embeddings of states and actions. Empirically, we demonstrate that our approach is able to partition demonstration datasets by quality according to human expert scores across a diverse set of benchmarks spanning simulation and real world environments. Moreover, training policies based on data filtered by our method leads to a 5-10% improvement in RoboMimic and better performance on real ALOHA and Franka setups.
Efficiently Generating Expressive Quadruped Behaviors via Language-Guided Preference Learning
Feb 06, 2025Expressive robotic behavior is essential for the widespread acceptance of robots in social environments. Recent advancements in learned legged locomotion controllers have enabled more dynamic and versatile robot behaviors. However, determining the optimal behavior for interactions with different users across varied scenarios remains a challenge. Current methods either rely on natural language input, which is efficient but low-resolution, or learn from human preferences, which, although high-resolution, is sample inefficient. This paper introduces a novel approach that leverages priors generated by pre-trained LLMs alongside the precision of preference learning. Our method, termed Language-Guided Preference Learning (LGPL), uses LLMs to generate initial behavior samples, which are then refined through preference-based feedback to learn behaviors that closely align with human expectations. Our core insight is that LLMs can guide the sampling process for preference learning, leading to a substantial improvement in sample efficiency. We demonstrate that LGPL can quickly learn accurate and expressive behaviors with as few as four queries, outperforming both purely language-parameterized models and traditional preference learning approaches. Website with videos: https://lgpl-gaits.github.io/
Vision Language Models are In-Context Value Learners
Nov 07, 2024
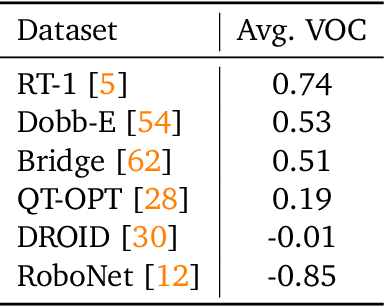
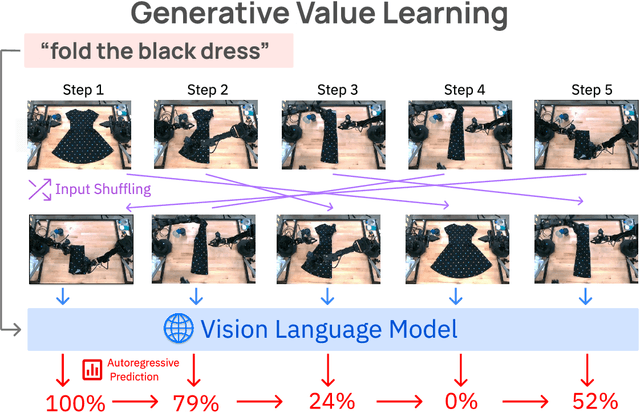
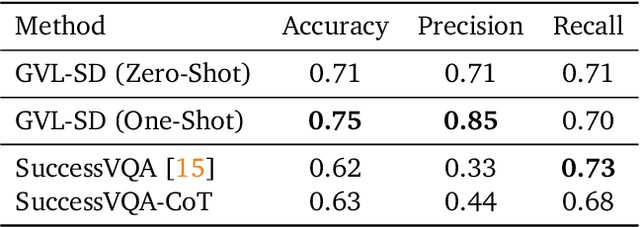
Predicting temporal progress from visual trajectories is important for intelligent robots that can learn, adapt, and improve. However, learning such progress estimator, or temporal value function, across different tasks and domains requires both a large amount of diverse data and methods which can scale and generalize. To address these challenges, we present Generative Value Learning (\GVL), a universal value function estimator that leverages the world knowledge embedded in vision-language models (VLMs) to predict task progress. Naively asking a VLM to predict values for a video sequence performs poorly due to the strong temporal correlation between successive frames. Instead, GVL poses value estimation as a temporal ordering problem over shuffled video frames; this seemingly more challenging task encourages VLMs to more fully exploit their underlying semantic and temporal grounding capabilities to differentiate frames based on their perceived task progress, consequently producing significantly better value predictions. Without any robot or task specific training, GVL can in-context zero-shot and few-shot predict effective values for more than 300 distinct real-world tasks across diverse robot platforms, including challenging bimanual manipulation tasks. Furthermore, we demonstrate that GVL permits flexible multi-modal in-context learning via examples from heterogeneous tasks and embodiments, such as human videos. The generality of GVL enables various downstream applications pertinent to visuomotor policy learning, including dataset filtering, success detection, and advantage-weighted regression -- all without any model training or finetuning.
So You Think You Can Scale Up Autonomous Robot Data Collection?
Nov 04, 2024A long-standing goal in robot learning is to develop methods for robots to acquire new skills autonomously. While reinforcement learning (RL) comes with the promise of enabling autonomous data collection, it remains challenging to scale in the real-world partly due to the significant effort required for environment design and instrumentation, including the need for designing reset functions or accurate success detectors. On the other hand, imitation learning (IL) methods require little to no environment design effort, but instead require significant human supervision in the form of collected demonstrations. To address these shortcomings, recent works in autonomous IL start with an initial seed dataset of human demonstrations that an autonomous policy can bootstrap from. While autonomous IL approaches come with the promise of addressing the challenges of autonomous RL as well as pure IL strategies, in this work, we posit that such techniques do not deliver on this promise and are still unable to scale up autonomous data collection in the real world. Through a series of real-world experiments, we demonstrate that these approaches, when scaled up to realistic settings, face much of the same scaling challenges as prior attempts in RL in terms of environment design. Further, we perform a rigorous study of autonomous IL methods across different data scales and 7 simulation and real-world tasks, and demonstrate that while autonomous data collection can modestly improve performance, simply collecting more human data often provides significantly more improvement. Our work suggests a negative result: that scaling up autonomous data collection for learning robot policies for real-world tasks is more challenging and impractical than what is suggested in prior work. We hope these insights about the core challenges of scaling up data collection help inform future efforts in autonomous learning.
MotIF: Motion Instruction Fine-tuning
Sep 16, 2024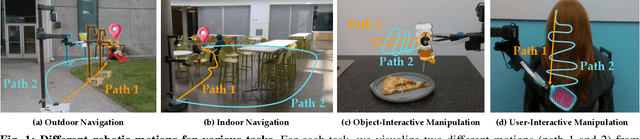

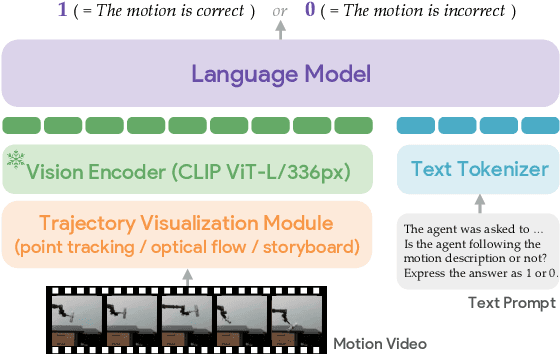

While success in many robotics tasks can be determined by only observing the final state and how it differs from the initial state - e.g., if an apple is picked up - many tasks require observing the full motion of the robot to correctly determine success. For example, brushing hair requires repeated strokes that correspond to the contours and type of hair. Prior works often use off-the-shelf vision-language models (VLMs) as success detectors; however, when success depends on the full trajectory, VLMs struggle to make correct judgments for two reasons. First, modern VLMs are trained only on single frames, and cannot capture changes over a full trajectory. Second, even if we provide state-of-the-art VLMs with an aggregate input of multiple frames, they still fail to detect success due to a lack of robot data. Our key idea is to fine-tune VLMs using abstract representations that are able to capture trajectory-level information such as the path the robot takes by overlaying keypoint trajectories on the final image. We propose motion instruction fine-tuning (MotIF), a method that fine-tunes VLMs using the aforementioned abstract representations to semantically ground the robot's behavior in the environment. To benchmark and fine-tune VLMs for robotic motion understanding, we introduce the MotIF-1K dataset containing 653 human and 369 robot demonstrations across 13 task categories. MotIF assesses the success of robot motion given the image observation of the trajectory, task instruction, and motion description. Our model significantly outperforms state-of-the-art VLMs by at least twice in precision and 56.1% in recall, generalizing across unseen motions, tasks, and environments. Finally, we demonstrate practical applications of MotIF in refining and terminating robot planning, and ranking trajectories on how they align with task and motion descriptions. Project page: https://motif-1k.github.io
Re-Mix: Optimizing Data Mixtures for Large Scale Imitation Learning
Aug 26, 2024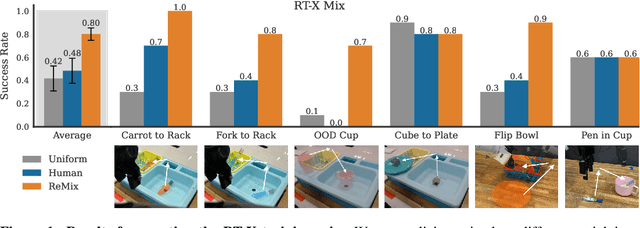
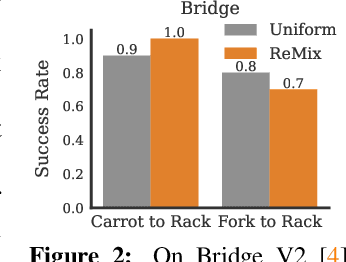

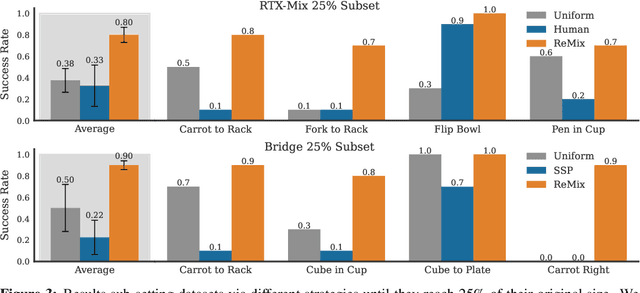
Increasingly large imitation learning datasets are being collected with the goal of training foundation models for robotics. However, despite the fact that data selection has been of utmost importance in vision and natural language processing, little work in robotics has questioned what data such models should actually be trained on. In this work we investigate how to weigh different subsets or ``domains'' of robotics datasets for robot foundation model pre-training. Concrete, we use distributionally robust optimization (DRO) to maximize worst-case performance across all possible downstream domains. Our method, Re-Mix, addresses the wide range of challenges that arise when applying DRO to robotics datasets including variability in action spaces and dynamics across different datasets. Re-Mix employs early stopping, action normalization, and discretization to counteract these issues. Through extensive experimentation on the largest open-source robot manipulation dataset, the Open X-Embodiment dataset, we demonstrate that data curation can have an outsized impact on downstream performance. Specifically, domain weights learned by Re-Mix outperform uniform weights by 38\% on average and outperform human-selected weights by 32\% on datasets used to train existing generalist robot policies, specifically the RT-X models.
Show, Don't Tell: Aligning Language Models with Demonstrated Feedback
Jun 02, 2024Language models are aligned to emulate the collective voice of many, resulting in outputs that align with no one in particular. Steering LLMs away from generic output is possible through supervised finetuning or RLHF, but requires prohibitively large datasets for new ad-hoc tasks. We argue that it is instead possible to align an LLM to a specific setting by leveraging a very small number ($<10$) of demonstrations as feedback. Our method, Demonstration ITerated Task Optimization (DITTO), directly aligns language model outputs to a user's demonstrated behaviors. Derived using ideas from online imitation learning, DITTO cheaply generates online comparison data by treating users' demonstrations as preferred over output from the LLM and its intermediate checkpoints. We evaluate DITTO's ability to learn fine-grained style and task alignment across domains such as news articles, emails, and blog posts. Additionally, we conduct a user study soliciting a range of demonstrations from participants ($N=16$). Across our benchmarks and user study, we find that win-rates for DITTO outperform few-shot prompting, supervised fine-tuning, and other self-play methods by an average of 19% points. By using demonstrations as feedback directly, DITTO offers a novel method for effective customization of LLMs.
Octo: An Open-Source Generalist Robot Policy
May 20, 2024



Large policies pretrained on diverse robot datasets have the potential to transform robotic learning: instead of training new policies from scratch, such generalist robot policies may be finetuned with only a little in-domain data, yet generalize broadly. However, to be widely applicable across a range of robotic learning scenarios, environments, and tasks, such policies need to handle diverse sensors and action spaces, accommodate a variety of commonly used robotic platforms, and finetune readily and efficiently to new domains. In this work, we aim to lay the groundwork for developing open-source, widely applicable, generalist policies for robotic manipulation. As a first step, we introduce Octo, a large transformer-based policy trained on 800k trajectories from the Open X-Embodiment dataset, the largest robot manipulation dataset to date. It can be instructed via language commands or goal images and can be effectively finetuned to robot setups with new sensory inputs and action spaces within a few hours on standard consumer GPUs. In experiments across 9 robotic platforms, we demonstrate that Octo serves as a versatile policy initialization that can be effectively finetuned to new observation and action spaces. We also perform detailed ablations of design decisions for the Octo model, from architecture to training data, to guide future research on building generalist robot models.