 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-Mix: Optimizing Data Mixtures for Large Scale Imitation Learning
Paper and Code
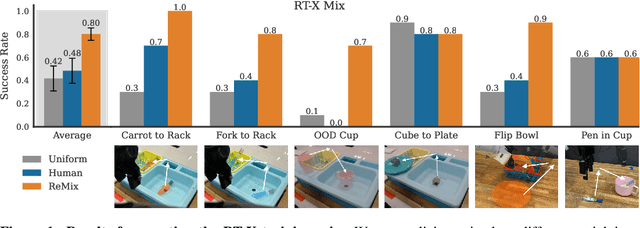
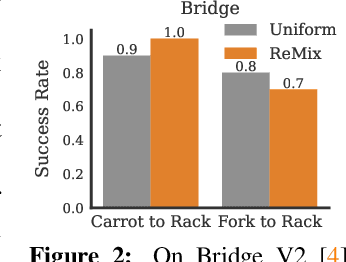

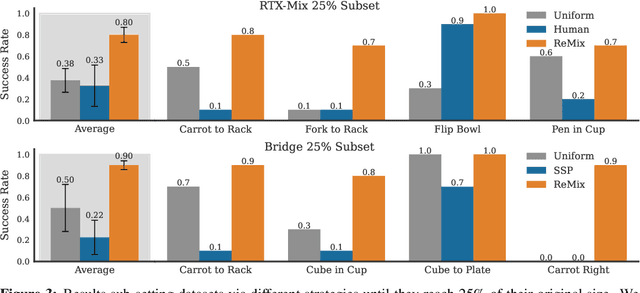
Increasingly large imitation learning datasets are being collected with the goal of training foundation models for robotics. However, despite the fact that data selection has been of utmost importance in vision and natural language processing, little work in robotics has questioned what data such models should actually be trained on. In this work we investigate how to weigh different subsets or ``domains'' of robotics datasets for robot foundation model pre-training. Concrete, we use distributionally robust optimization (DRO) to maximize worst-case performance across all possible downstream domains. Our method, Re-Mix, addresses the wide range of challenges that arise when applying DRO to robotics datasets including variability in action spaces and dynamics across different datasets. Re-Mix employs early stopping, action normalization, and discretization to counteract these issues. Through extensive experimentation on the largest open-source robot manipulation dataset, the Open X-Embodiment dataset, we demonstrate that data curation can have an outsized impact on downstream performance. Specifically, domain weights learned by Re-Mix outperform uniform weights by 38\% on average and outperform human-selected weights by 32\% on datasets used to train existing generalist robot policies, specifically the RT-X models.