 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost and Reward Infused Metric Elicitation
Jan 01, 2025



In machine learning, metric elicitation refers to the selection of performance metrics that best reflect an individual's implicit preferences for a given application. Currently, metric elicitation methods only consider metrics that depend on the accuracy values encoded within a given model's confusion matrix. However, focusing solely on confusion matrices does not account for other model feasibility considerations such as varied monetary costs or latencies. In our work, we build upon the multiclass metric elicitation framework of Hiranandani et al., extrapolating their proposed Diagonal Linear Performance Metric Elicitation (DLPME) algorithm to account for additional bounded costs and rewards. Our experimental results with synthetic data demonstrate our approach's ability to quickly converge to the true metric.
Re-Mix: Optimizing Data Mixtures for Large Scale Imitation Learning
Aug 26, 2024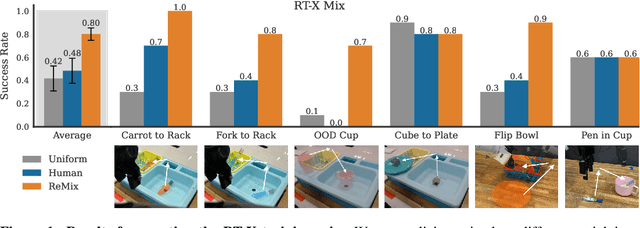
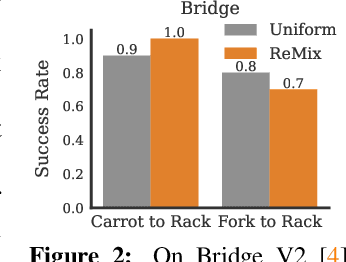

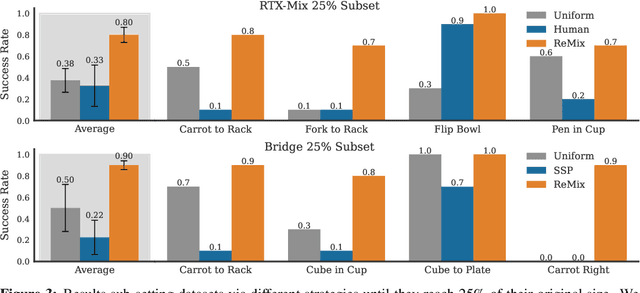
Increasingly large imitation learning datasets are being collected with the goal of training foundation models for robotics. However, despite the fact that data selection has been of utmost importance in vision and natural language processing, little work in robotics has questioned what data such models should actually be trained on. In this work we investigate how to weigh different subsets or ``domains'' of robotics datasets for robot foundation model pre-training. Concrete, we use distributionally robust optimization (DRO) to maximize worst-case performance across all possible downstream domains. Our method, Re-Mix, addresses the wide range of challenges that arise when applying DRO to robotics datasets including variability in action spaces and dynamics across different datasets. Re-Mix employs early stopping, action normalization, and discretization to counteract these issues. Through extensive experimentation on the largest open-source robot manipulation dataset, the Open X-Embodiment dataset, we demonstrate that data curation can have an outsized impact on downstream performance. Specifically, domain weights learned by Re-Mix outperform uniform weights by 38\% on average and outperform human-selected weights by 32\% on datasets used to train existing generalist robot policies, specifically the RT-X models.
Robotic Offline RL from Internet Videos via Value-Function Pre-Training
Sep 22, 2023Pre-training on Internet data has proven to be a key ingredient for broad generalization in many modern ML systems. What would it take to enable such capabilities in robotic reinforcement learning (RL)? Offline RL methods, which learn from datasets of robot experience, offer one way to leverage prior data into the robotic learning pipeline. However, these methods have a "type mismatch" with video data (such as Ego4D), the largest prior datasets available for robotics, since video offers observation-only experience without the action or reward annotations needed for RL methods. In this paper, we develop a system for leveraging large-scale human video datasets in robotic offline RL, based entirely on learning value functions via temporal-difference learning. We show that value learning on video datasets learns representations that are more conducive to downstream robotic offline RL than other approaches for learning from video data. Our system, called V-PTR, combines the benefits of pre-training on video data with robotic offline RL approaches that train on diverse robot data, resulting in value functions and policies for manipulation tasks that perform better, act robustly, and generalize broadly. On several manipulation tasks on a real WidowX robot, our framework produces policies that greatly improve over prior methods. Our video and additional details can be found at https://dibyaghosh.com/vptr/
Reinforcement Learning from Passive Data via Latent Intentions
Apr 10, 2023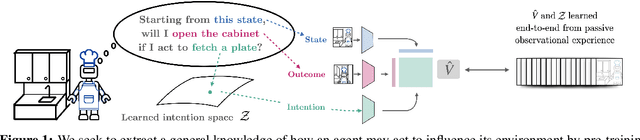
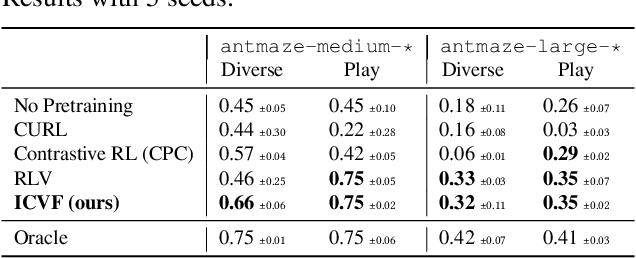
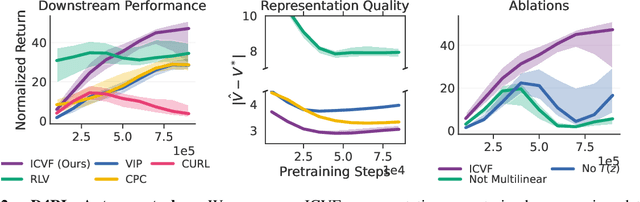

Passive observational data, such as human videos, is abundant and rich in information, yet remains largely untapped by current RL methods. Perhaps surprisingly, we show that passive data, despite not having reward or action labels, can still be used to learn features that accelerate downstream RL. Our approach learns from passive data by modeling intentions: measuring how the likelihood of future outcomes change when the agent acts to achieve a particular task. We propose a temporal difference learning objective to learn about intentions, resulting in an algorithm similar to conventional RL, but which learns entirely from passive data. When optimizing this objective, our agent simultaneously learns representations of states, of policies, and of possible outcomes in an environment, all from raw observational data. Both theoretically and empirically, this scheme learns features amenable for value prediction for downstream tasks, and our experiments demonstrate the ability to learn from many forms of passive data, including cross-embodiment video data and YouTube videos.