 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Pre-Training on Unlabeled Images using Reinforcement Learning
Jun 13, 2025In reinforcement learning (RL), value-based algorithms learn to associate each observation with the states and rewards that are likely to be reached from it. We observe that many self-supervised image pre-training methods bear similarity to this formulation: learning features that associate crops of images with those of nearby views, e.g., by taking a different crop or color augmentation. In this paper, we complete this analogy and explore a method that directly casts pre-training on unlabeled image data like web crawls and video frames as an RL problem. We train a general value function in a dynamical system where an agent transforms an image by changing the view or adding image augmentations. Learning in this way resembles crop-consistency self-supervision, but through the reward function, offers a simple lever to shape feature learning using curated images or weakly labeled captions when they exist. Our experiments demonstrate improved representations when training on unlabeled images in the wild, including video data like EpicKitchens, scene data like COCO, and web-crawl data like CC12M.
$π_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Apr 22, 2025



In order for robots to be useful, they must perform practically relevant tasks in the real world, outside of the lab. While vision-language-action (VLA) models have demonstrated impressive results for end-to-end robot control, it remains an open question how far such models can generalize in the wild. We describe $\pi_{0.5}$, a new model based on $\pi_{0}$ that uses co-training on heterogeneous tasks to enable broad generalization. $\pi_{0.5}$\ uses data from multiple robots, high-level semantic prediction, web data, and other sources to enable broadly generalizable real-world robotic manipulation. Our system uses a combination of co-training and hybrid multi-modal examples that combine image observations, language commands, object detections, semantic subtask prediction, and low-level actions. Our experiments show that this kind of knowledge transfer is essential for effective generalization, and we demonstrate for the first time that an end-to-end learning-enabled robotic system can perform long-horizon and dexterous manipulation skills, such as cleaning a kitchen or bedroom, in entirely new homes.
What Do Learning Dynamics Reveal About Generalization in LLM Reasoning?
Nov 12, 2024



Despite the remarkable capabilities of modern large language models (LLMs), the mechanisms behind their problem-solving abilities remain elusive. In this work, we aim to better understand how the learning dynamics of LLM finetuning shapes downstream generalization. Our analysis focuses on reasoning tasks, whose problem structure allows us to distinguish between memorization (the exact replication of reasoning steps from the training data) and performance (the correctness of the final solution). We find that a model's generalization behavior can be effectively characterized by a training metric we call pre-memorization train accuracy: the accuracy of model samples on training queries before they begin to copy the exact reasoning steps from the training set. On the dataset level, this metric is able to reliably predict test accuracy, achieving $R^2$ of around or exceeding 0.9 across various models (Llama3 8, Gemma2 9B), datasets (GSM8k, MATH), and training configurations. On a per-example level, this metric is also indicative of whether individual model predictions are robust to perturbations in the training query. By connecting a model's learning behavior to its generalization, pre-memorization train accuracy can guide targeted improvements to training strategies. We focus on data curation as an example, and show that prioritizing examples with low pre-memorization accuracy leads to 1.5-2x improvements in data efficiency compared to i.i.d. data scaling, and outperforms other standard data curation techniques.
Octo: An Open-Source Generalist Robot Policy
May 20, 2024



Large policies pretrained on diverse robot datasets have the potential to transform robotic learning: instead of training new policies from scratch, such generalist robot policies may be finetuned with only a little in-domain data, yet generalize broadly. However, to be widely applicable across a range of robotic learning scenarios, environments, and tasks, such policies need to handle diverse sensors and action spaces, accommodate a variety of commonly used robotic platforms, and finetune readily and efficiently to new domains. In this work, we aim to lay the groundwork for developing open-source, widely applicable, generalist policies for robotic manipulation. As a first step, we introduce Octo, a large transformer-based policy trained on 800k trajectories from the Open X-Embodiment dataset, the largest robot manipulation dataset to date. It can be instructed via language commands or goal images and can be effectively finetuned to robot setups with new sensory inputs and action spaces within a few hours on standard consumer GPUs. In experiments across 9 robotic platforms, we demonstrate that Octo serves as a versatile policy initialization that can be effectively finetuned to new observation and action spaces. We also perform detailed ablations of design decisions for the Octo model, from architecture to training data, to guide future research on building generalist robot models.
Accelerating Exploration with Unlabeled Prior Data
Nov 21, 2023Learning to solve tasks from a sparse reward signal is a major challenge for standard reinforcement learning (RL) algorithms. However, in the real world, agents rarely need to solve sparse reward tasks entirely from scratch. More often, we might possess prior experience to draw on that provides considerable guidance about which actions and outcomes are possible in the world, which we can use to explore more effectively for new tasks. In this work, we study how prior data without reward labels may be used to guide and accelerate exploration for an agent solving a new sparse reward task. We propose a simple approach that learns a reward model from online experience, labels the unlabeled prior data with optimistic rewards, and then uses it concurrently alongside the online data for downstream policy and critic optimization. This general formula leads to rapid exploration in several challenging sparse-reward domains where tabula rasa exploration is insufficient, including the AntMaze domain, Adroit hand manipulation domain, and a visual simulated robotic manipulation domain. Our results highlight the ease of incorporating unlabeled prior data into existing online RL algorithms, and the (perhaps surprising) effectiveness of doing so.
Robotic Offline RL from Internet Videos via Value-Function Pre-Training
Sep 22, 2023Pre-training on Internet data has proven to be a key ingredient for broad generalization in many modern ML systems. What would it take to enable such capabilities in robotic reinforcement learning (RL)? Offline RL methods, which learn from datasets of robot experience, offer one way to leverage prior data into the robotic learning pipeline. However, these methods have a "type mismatch" with video data (such as Ego4D), the largest prior datasets available for robotics, since video offers observation-only experience without the action or reward annotations needed for RL methods. In this paper, we develop a system for leveraging large-scale human video datasets in robotic offline RL, based entirely on learning value functions via temporal-difference learning. We show that value learning on video datasets learns representations that are more conducive to downstream robotic offline RL than other approaches for learning from video data. Our system, called V-PTR, combines the benefits of pre-training on video data with robotic offline RL approaches that train on diverse robot data, resulting in value functions and policies for manipulation tasks that perform better, act robustly, and generalize broadly. On several manipulation tasks on a real WidowX robot, our framework produces policies that greatly improve over prior methods. Our video and additional details can be found at https://dibyaghosh.com/vptr/
HIQL: Offline Goal-Conditioned RL with Latent States as Actions
Jul 22, 2023



Unsupervised pre-training has recently become the bedrock for computer vision and natural language processing. In reinforcement learning (RL), goal-conditioned RL can potentially provide an analogous self-supervised approach for making use of large quantities of unlabeled (reward-free) data. However, building effective algorithms for goal-conditioned RL that can learn directly from diverse offline data is challenging, because it is hard to accurately estimate the exact value function for faraway goals. Nonetheless, goal-reaching problems exhibit structure, such that reaching distant goals entails first passing through closer subgoals. This structure can be very useful, as assessing the quality of actions for nearby goals is typically easier than for more distant goals. Based on this idea, we propose a hierarchical algorithm for goal-conditioned RL from offline data. Using one action-free value function, we learn two policies that allow us to exploit this structure: a high-level policy that treats states as actions and predicts (a latent representation of) a subgoal and a low-level policy that predicts the action for reaching this subgoal. Through analysis and didactic examples, we show how this hierarchical decomposition makes our method robust to noise in the estimated value function. We then apply our method to offline goal-reaching benchmarks, showing that our method can solve long-horizon tasks that stymie prior methods, can scale to high-dimensional image observations, and can readily make use of action-free data. Our code is available at https://seohong.me/projects/hiql/
Reinforcement Learning from Passive Data via Latent Intentions
Apr 10, 2023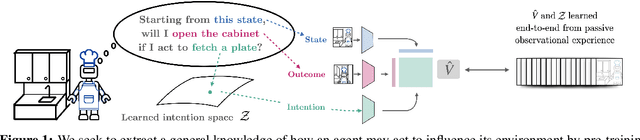
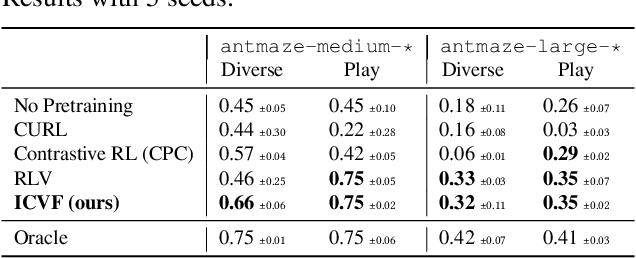
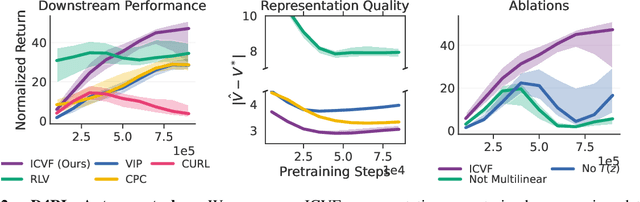

Passive observational data, such as human videos, is abundant and rich in information, yet remains largely untapped by current RL methods. Perhaps surprisingly, we show that passive data, despite not having reward or action labels, can still be used to learn features that accelerate downstream RL. Our approach learns from passive data by modeling intentions: measuring how the likelihood of future outcomes change when the agent acts to achieve a particular task. We propose a temporal difference learning objective to learn about intentions, resulting in an algorithm similar to conventional RL, but which learns entirely from passive data. When optimizing this objective, our agent simultaneously learns representations of states, of policies, and of possible outcomes in an environment, all from raw observational data. Both theoretically and empirically, this scheme learns features amenable for value prediction for downstream tasks, and our experiments demonstrate the ability to learn from many forms of passive data, including cross-embodiment video data and YouTube videos.
Distributionally Adaptive Meta Reinforcement Learning
Oct 06, 2022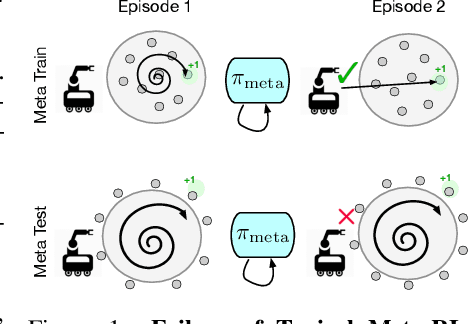

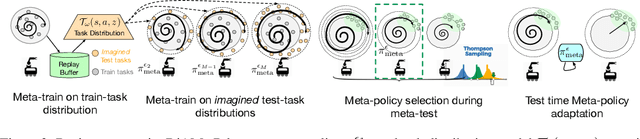
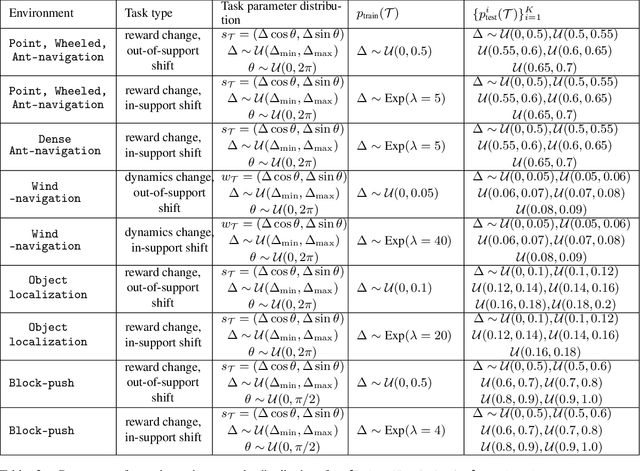
Meta-reinforcement learning algorithms provide a data-driven way to acquire policies that quickly adapt to many tasks with varying rewards or dynamics functions. However, learned meta-policies are often effective only on the exact task distribution on which they were trained and struggle in the presence of distribution shift of test-time rewards or transition dynamics. In this work, we develop a framework for meta-RL algorithms that are able to behave appropriately under test-time distribution shifts in the space of tasks. Our framework centers on an adaptive approach to distributional robustness that trains a population of meta-policies to be robust to varying levels of distribution shift. When evaluated on a potentially shifted test-time distribution of tasks, this allows us to choose the meta-policy with the most appropriate level of robustness, and use it to perform fast adaptation. We formally show how our framework allows for improved regret under distribution shift, and empirically show its efficacy on simulated robotics problems under a wide range of distribution shifts.
Offline RL Policies Should be Trained to be Adaptive
Jul 05, 2022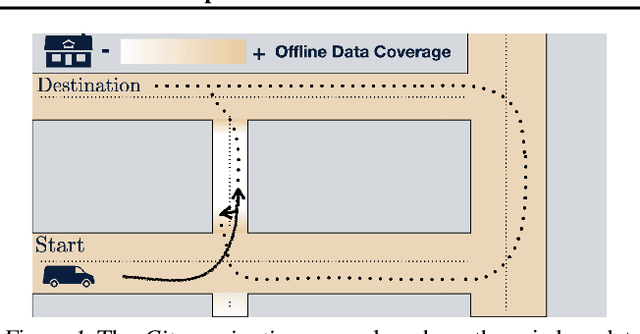
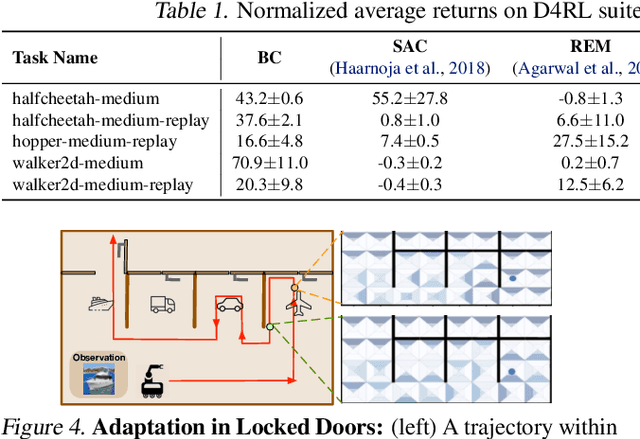
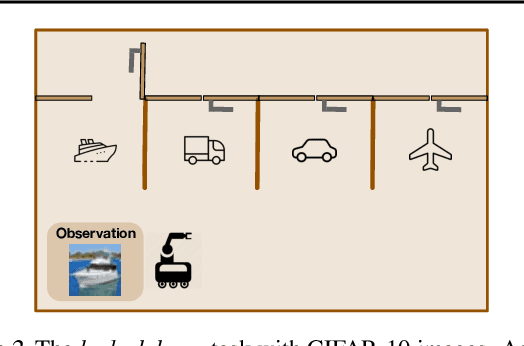
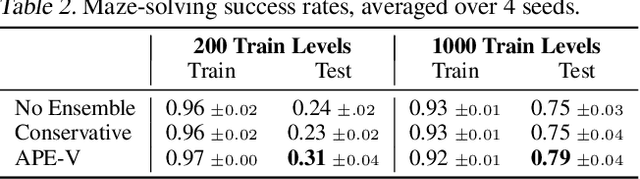
Offline RL algorithms must account for the fact that the dataset they are provided may leave many facets of the environment unknown. The most common way to approach this challenge is to employ pessimistic or conservative methods, which avoid behaviors that are too dissimilar from those in the training dataset. However, relying exclusively on conservatism has drawbacks: performance is sensitive to the exact degree of conservatism, and conservative objectives can recover highly suboptimal policies. In this work, we propose that offline RL methods should instead be adaptive in the presence of uncertainty. We show that acting optimally in offline RL in a Bayesian sense involves solving an implicit POMDP. As a result, optimal policies for offline RL must be adaptive, depending not just on the current state but rather all the transitions seen so far during evaluation.We present a model-free algorithm for approximating this optimal adaptive policy, and demonstrate the efficacy of learning such adaptive policies in offline RL benchmarks.