 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Perceive the World Through Control: Empowerment-Based Representation Learning
May 28, 2026In many practical reinforcement learning environments, observations are far higher-dimensional than the variables that matter for control. In this work, we ask: can we learn representations that capture only control-relevant features of the environment? We study this question through the empowerment objective, which maximizes an agent's influence over the environment and is widely used for unsupervised skill learning. We show that empowerment agents induce two distinct representations -- forward and backward -- that capture complementary aspects of the state, and both of which are invariant to control-irrelevant features. Thus, empowerment maximization leads agents to learn an implicit, control-centric model of the world. Our analysis highlights the importance of learning representations through interaction rather than from passive datasets: interaction aimed at maximizing control is essential for learning useful invariance properties, a perspective that aligns closely with the causal learning literature.
Behavior-Consistent Deep Reinforcement Learning
May 21, 2026Reinforcement learning (RL) often exhibits high variance across training runs, leading to unreliable performance and posing a major challenge to deployment in real-world domains. In this work, we address the challenge of cross-run policy divergence by formalizing the problem of behavior-consistent RL, where the objective is to obtain policies that are both high-performing and distributionally similar across training runs. Our key observation is that maximum-entropy RL provides a direct mechanism for controlling behavioral divergence by anchoring runs to a common (uniform) prior. We prove that, for Boltzmann policies, choosing the temperature proportional to $Q$-function disagreement bounds the pairwise KL divergence between the induced policies. However, we also show that naïvely increasing entropy might impair policy optimization while amplifying off-policy error. Building upon these observations, we propose $Q$-value Expectile Disagreement (QED), a state-dependent temperature schedule that uses double-critic disagreement as a single-run proxy for cross-run disagreement. Empirically, we demonstrate that across 18 continuous-control tasks, QED reduces across-run divergence by two orders of magnitude without sacrificing performance, resulting in a considerable reduction in return variance at modest sample-efficiency costs.
Unifying Goal-Conditioned RL and Unsupervised Skill Learning via Control-Maximization
May 07, 2026Unsupervised pretraining has driven empirical advances in goal-conditioned reinforcement learning (GCRL), but its theoretical foundations remain poorly understood. In particular, an influential class of methods, mutual information skill learning (MISL), discovers behaviorally diverse skills that can later be used for downstream goal-reaching. However, it remains a theoretical mystery why skills learned through MISL should support goal-reaching. A subtle challenge is that both GCRL and MISL are umbrella terms: different GCRL tasks use distinct criteria for measuring goal-reaching performance, while different MISL methods optimize distinct notions of behavioral diversity. We address this challenge and unify GCRL and MISL as instances of control maximization. We identify three canonical GCRL formulations and prove that they are fundamentally inequivalent: they can induce incompatible optimal policies even in the same environment. Nevertheless, they all share a common interpretation: a well-performing goal-conditioned policy is one whose future trajectory is highly sensitive to the commanded goal, with the precise notion of sensitivity determined by the GCRL formulation. Noting that MISL objectives can be understood as measures of skill-sensitivity akin to goal-sensitivity, we show that MISL objectives are bounded by formulation-specific downstream goal-sensitivities. These bounds establish a precise correspondence between MISL methods and downstream GCRL tasks: for every GCRL formulation, there exists a matching MISL objective for which more diverse skills afford greater downstream goal sensitivity. Our results thus lay a theoretical foundation for RL pretraining and have important practical implications, such as suggesting which pretraining objectives to use when a user cares about a specific class of downstream tasks.
Occupancy Reward Shaping: Improving Credit Assignment for Offline Goal-Conditioned Reinforcement Learning
Apr 22, 2026The temporal lag between actions and their long-term consequences makes credit assignment a challenge when learning goal-directed behaviors from data. Generative world models capture the distribution of future states an agent may visit, indicating that they have captured temporal information. How can that temporal information be extracted to perform credit assignment? In this paper, we formalize how the temporal information stored in world models encodes the underlying geometry of the world. Leveraging optimal transport, we extract this geometry from a learned model of the occupancy measure into a reward function that captures goal-reaching information. Our resulting method, Occupancy Reward Shaping, largely mitigates the problem of credit assignment in sparse reward settings. ORS provably does not alter the optimal policy, yet empirically improves performance by 2.2x across 13 diverse long-horizon locomotion and manipulation tasks. Moreover, we demonstrate the effectiveness of ORS in the real world for controlling nuclear fusion on 3 Tokamak control tasks. Code: https://github.com/aravindvenu7/occupancy_reward_shaping; Website: https://aravindvenu7.github.io/website/ors/
Temporal Representations for Exploration: Learning Complex Exploratory Behavior without Extrinsic Rewards
Mar 02, 2026Effective exploration in reinforcement learning requires not only tracking where an agent has been, but also understanding how the agent perceives and represents the world. To learn powerful representations, an agent should actively explore states that contribute to its knowledge of the environment. Temporal representations can capture the information necessary to solve a wide range of potential tasks while avoiding the computational cost associated with full state reconstruction. In this paper, we propose an exploration method that leverages temporal contrastive representations to guide exploration, prioritizing states with unpredictable future outcomes. We demonstrate that such representations can enable the learning of complex exploratory x in locomotion, manipulation, and embodied-AI tasks, revealing capabilities and behaviors that traditionally require extrinsic rewards. Unlike approaches that rely on explicit distance learning or episodic memory mechanisms (e.g., quasimetric-based methods), our method builds directly on temporal similarities, yielding a simpler yet effective strategy for exploration.
UpSkill: Mutual Information Skill Learning for Structured Response Diversity in LLMs
Feb 25, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has improved the reasoning abilities of large language models (LLMs) on mathematics and programming tasks, but standard approaches that optimize single-attempt accuracy can inadvertently suppress response diversity across repeated attempts, narrowing exploration and overlooking underrepresented strategies. We introduce UpSkill, a training time method that adapts Mutual Information Skill Learning (MISL) to LLMs for optimizing pass@k correctness. We propose a novel reward that we implement within Group Relative Policy Optimization (GRPO): a token-level mutual information (MI) reward that encourages trajectory specificity to z. Experiments on GSM8K with three open-weight models, Llama 3.1-8B, Qwen 2.5-7B, and R1-Distilled-Qwen2.5-Math-1.5B, show that UpSkill improves multi-attempt metrics on the stronger base models, yielding mean gains of ~3% in pass@k for both Qwen and Llama without degrading pass@1. Additionally, we find both empirical and theoretical evidence that improvements in pass@k are closely tied to the mutual information objective.
On the Role of Iterative Computation in Reinforcement Learning
Feb 17, 2026How does the amount of compute available to a reinforcement learning (RL) policy affect its learning? Can policies using a fixed amount of parameters, still benefit from additional compute? The standard RL framework does not provide a language to answer these questions formally. Empirically, deep RL policies are often parameterized as neural networks with static architectures, conflating the amount of compute and the number of parameters. In this paper, we formalize compute bounded policies and prove that policies which use more compute can solve problems and generalize to longer-horizon tasks that are outside the scope of policies with less compute. Building on prior work in algorithmic learning and model-free planning, we propose a minimal architecture that can use a variable amount of compute. Our experiments complement our theory. On a set 31 different tasks spanning online and offline RL, we show that $(1)$ this architecture achieves stronger performance simply by using more compute, and $(2)$ stronger generalization on longer-horizon test tasks compared to standard feedforward networks or deep residual network using up to 5 times more parameters.
Can We Really Learn One Representation to Optimize All Rewards?
Feb 11, 2026As machine learning has moved towards leveraging large models as priors for downstream tasks, the community has debated the right form of prior for solving reinforcement learning (RL) problems. If one were to try to prefetch as much computation as possible, they would attempt to learn a prior over the policies for some yet-to-be-determined reward function. Recent work (forward-backward (FB) representation learning) has tried this, arguing that an unsupervised representation learning procedure can enable optimal control over arbitrary rewards without further fine-tuning. However, FB's training objective and learning behavior remain mysterious. In this paper, we demystify FB by clarifying when such representations can exist, what its objective optimizes, and how it converges in practice. We draw connections with rank matching, fitted Q-evaluation, and contraction mapping. Our analysis suggests a simplified unsupervised pre-training method for RL that, instead of enabling optimal control, performs one step of policy improvement. We call our proposed method $\textbf{one-step forward-backward representation learning (one-step FB)}$. Experiments in didactic settings, as well as in $10$ state-based and image-based continuous control domains, demonstrate that one-step FB converges to errors $10^5$ smaller and improves zero-shot performance by $+24\%$ on average. Our project website is available at https://chongyi-zheng.github.io/onestep-fb.
On Computation and Reinforcement Learning
Feb 05, 2026How does the amount of compute available to a reinforcement learning (RL) policy affect its learning? Can policies using a fixed amount of parameters, still benefit from additional compute? The standard RL framework does not provide a language to answer these questions formally. Empirically, deep RL policies are often parameterized as neural networks with static architectures, conflating the amount of compute and the number of parameters. In this paper, we formalize compute bounded policies and prove that policies which use more compute can solve problems and generalize to longer-horizon tasks that are outside the scope of policies with less compute. Building on prior work in algorithmic learning and model-free planning, we propose a minimal architecture that can use a variable amount of compute. Our experiments complement our theory. On a set 31 different tasks spanning online and offline RL, we show that $(1)$ this architecture achieves stronger performance simply by using more compute, and $(2)$ stronger generalization on longer-horizon test tasks compared to standard feedforward networks or deep residual network using up to 5 times more parameters.
Multistep Quasimetric Learning for Scalable Goal-conditioned Reinforcement Learning
Nov 14, 2025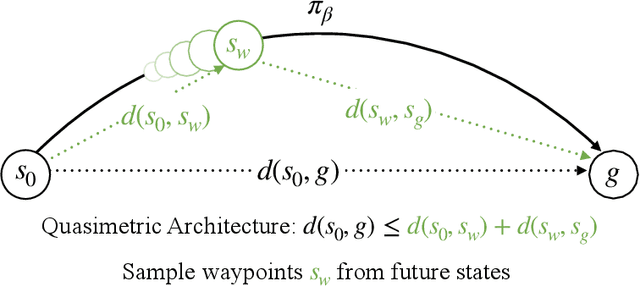


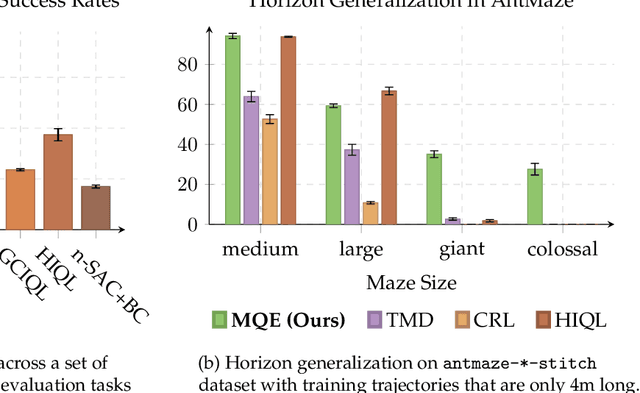
Learning how to reach goals in an environment is a longstanding challenge in AI, yet reasoning over long horizons remains a challenge for modern methods. The key question is how to estimate the temporal distance between pairs of observations. While temporal difference methods leverage local updates to provide optimality guarantees, they often perform worse than Monte Carlo methods that perform global updates (e.g., with multi-step returns), which lack such guarantees. We show how these approaches can be integrated into a practical GCRL method that fits a quasimetric distance using a multistep Monte-Carlo return. We show our method outperforms existing GCRL methods on long-horizon simulated tasks with up to 4000 steps, even with visual observations. We also demonstrate that our method can enable stitching in the real-world robotic manipulation domain (Bridge setup). Our approach is the first end-to-end GCRL method that enables multistep stitching in this real-world manipulation domain from an unlabeled offline dataset of visual observations.