 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning When to Plan: Efficiently Allocating Test-Time Compute for LLM Agents
Sep 03, 2025



Training large language models (LLMs) to reason via reinforcement learning (RL) significantly improves their problem-solving capabilities. In agentic settings, existing methods like ReAct prompt LLMs to explicitly plan before every action; however, we demonstrate that always planning is computationally expensive and degrades performance on long-horizon tasks, while never planning further limits performance. To address this, we introduce a conceptual framework formalizing dynamic planning for LLM agents, enabling them to flexibly decide when to allocate test-time compute for planning. We propose a simple two-stage training pipeline: (1) supervised fine-tuning on diverse synthetic data to prime models for dynamic planning, and (2) RL to refine this capability in long-horizon environments. Experiments on the Crafter environment show that dynamic planning agents trained with this approach are more sample-efficient and consistently achieve more complex objectives. Additionally, we demonstrate that these agents can be effectively steered by human-written plans, surpassing their independent capabilities. To our knowledge, this work is the first to explore training LLM agents for dynamic test-time compute allocation in sequential decision-making tasks, paving the way for more efficient, adaptive, and controllable agentic systems.
Can a MISL Fly? Analysis and Ingredients for Mutual Information Skill Learning
Dec 11, 2024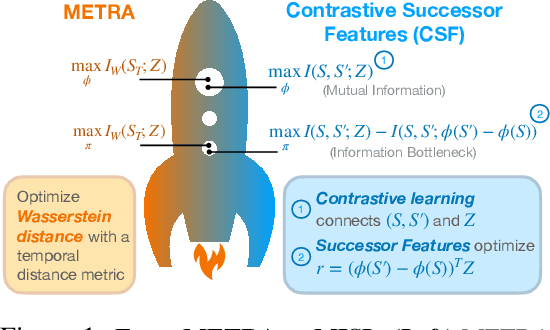
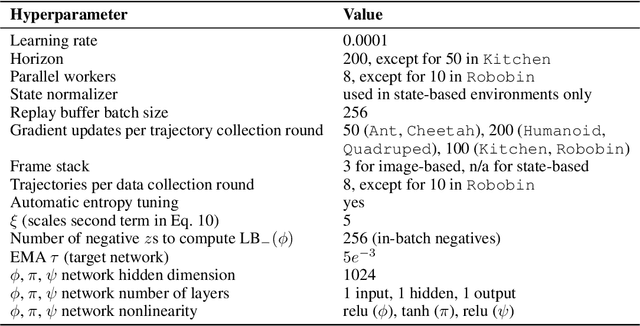
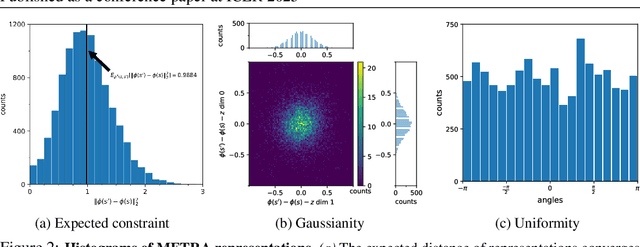
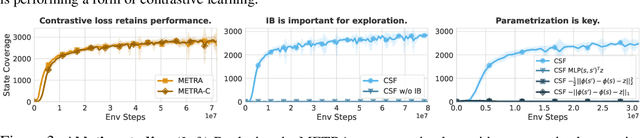
Self-supervised learning has the potential of lifting several of the key challenges in reinforcement learning today, such as exploration, representation learning, and reward design. Recent work (METRA) has effectively argued that moving away from mutual information and instead optimizing a certain Wasserstein distance is important for good performance. In this paper, we argue that the benefits seen in that paper can largely be explained within the existing framework of mutual information skill learning (MISL). Our analysis suggests a new MISL method (contrastive successor features) that retains the excellent performance of METRA with fewer moving parts, and highlights connections between skill learning, contrastive representation learning, and successor features. Finally, through careful ablation studies, we provide further insight into some of the key ingredients for both our method and METRA.
Language-Guided World Models: A Model-Based Approach to AI Control
Jan 24, 2024



Installing probabilistic world models into artificial agents opens an efficient channel for humans to communicate with and control these agents. In addition to updating agent policies, humans can modify their internal world models in order to influence their decisions. The challenge, however, is that currently existing world models are difficult for humans to adapt because they lack a natural communication interface. Aimed at addressing this shortcoming, we develop Language-Guided World Models (LWMs), which can capture environment dynamics by reading language descriptions. These models enhance agent communication efficiency, allowing humans to simultaneously alter their behavior on multiple tasks with concise language feedback. They also enable agents to self-learn from texts originally written to instruct humans. To facilitate the development of LWMs, we design a challenging benchmark based on the game of MESSENGER (Hanjie et al., 2021), requiring compositional generalization to new language descriptions and environment dynamics. Our experiments reveal that the current state-of-the-art Transformer architecture performs poorly on this benchmark, motivating us to design a more robust architecture. To showcase the practicality of our proposed LWMs, we simulate a scenario where these models augment the interpretability and safety of an agent by enabling it to generate and discuss plans with a human before execution. By effectively incorporating language feedback on the plan, the models boost the agent performance in the real environment by up to three times without collecting any interactive experiences in this environment.
Scaling Laws for Imitation Learning in NetHack
Jul 18, 2023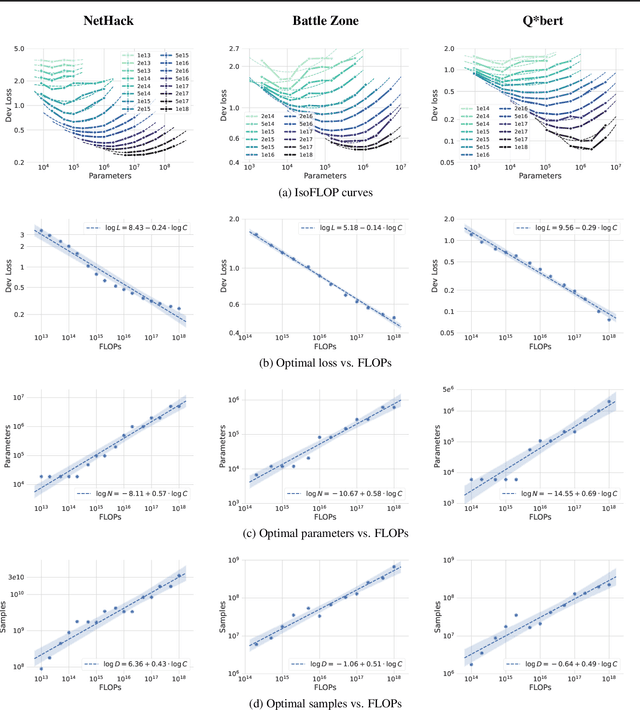

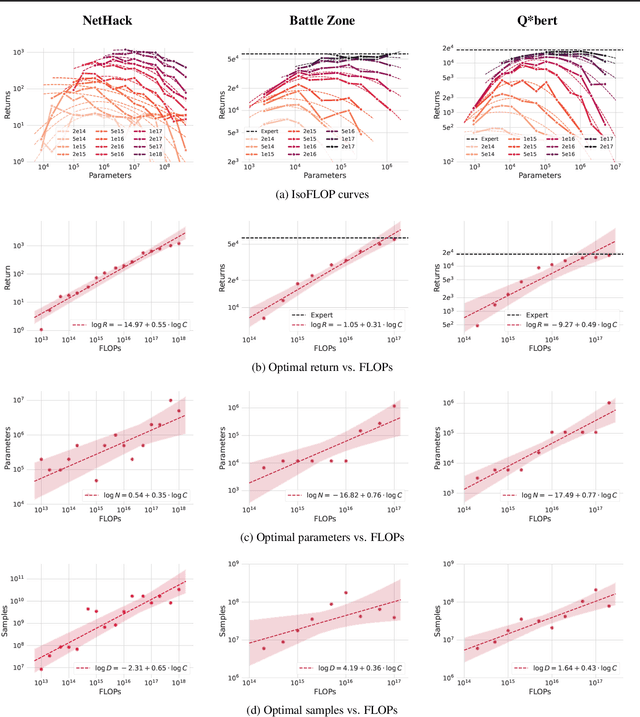
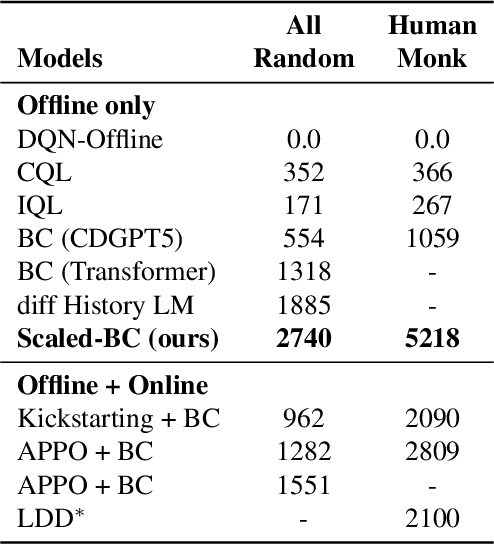
Imitation Learning (IL) is one of the most widely used methods in machine learning. Yet, while powerful, many works find it is often not able to fully recover the underlying expert behavior. However, none of these works deeply investigate the role of scaling up the model and data size. Inspired by recent work in Natural Language Processing (NLP) where "scaling up" has resulted in increasingly more capable LLMs, we investigate whether carefully scaling up model and data size can bring similar improvements in the imitation learning setting. To demonstrate our findings, we focus on the game of NetHack, a challenging environment featuring procedural generation, stochasticity, long-term dependencies, and partial observability. We find IL loss and mean return scale smoothly with the compute budget and are strongly correlated, resulting in power laws for training compute-optimal IL agents with respect to model size and number of samples. We forecast and train several NetHack agents with IL and find they outperform prior state-of-the-art by at least 2x in all settings. Our work both demonstrates the scaling behavior of imitation learning in a challenging domain, as well as the viability of scaling up current approaches for increasingly capable agents in NetHack, a game that remains elusively hard for current AI systems.
Multi-Stage Episodic Control for Strategic Exploration in Text Games
Jan 11, 2022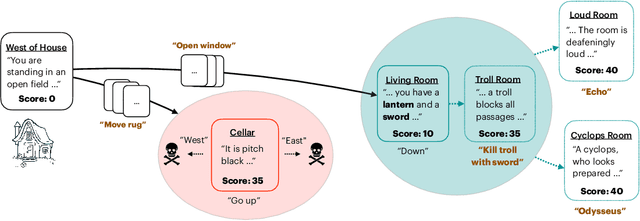
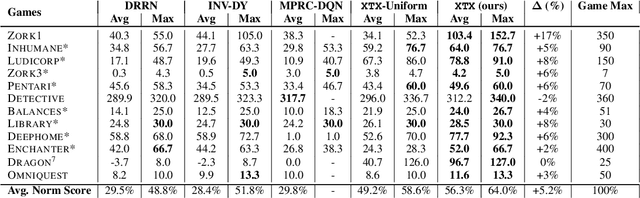

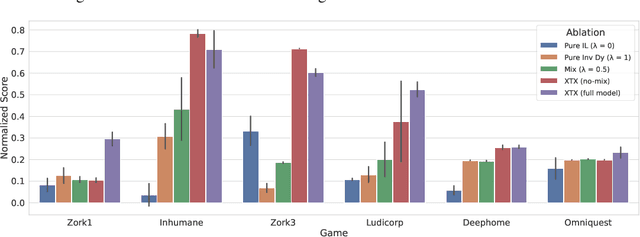
Text adventure games present unique challenges to reinforcement learning methods due to their combinatorially large action spaces and sparse rewards. The interplay of these two factors is particularly demanding because large action spaces require extensive exploration, while sparse rewards provide limited feedback. This work proposes to tackle the explore-vs-exploit dilemma using a multi-stage approach that explicitly disentangles these two strategies within each episode. Our algorithm, called eXploit-Then-eXplore (XTX), begins each episode using an exploitation policy that imitates a set of promising trajectories from the past, and then switches over to an exploration policy aimed at discovering novel actions that lead to unseen state spaces. This policy decomposition allows us to combine global decisions about which parts of the game space to return to with curiosity-based local exploration in that space, motivated by how a human may approach these games. Our method significantly outperforms prior approaches by 27% and 11% average normalized score over 12 games from the Jericho benchmark (Hausknecht et al., 2020) in both deterministic and stochastic settings, respectively. On the game of Zork1, in particular, XTX obtains a score of 103, more than a 2x improvement over prior methods, and pushes past several known bottlenecks in the game that have plagued previous state-of-the-art methods.
Gradient-based Analysis of NLP Models is Manipulable
Oct 12, 2020

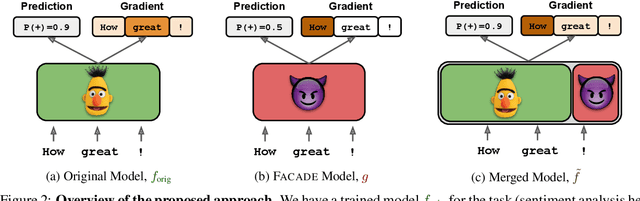
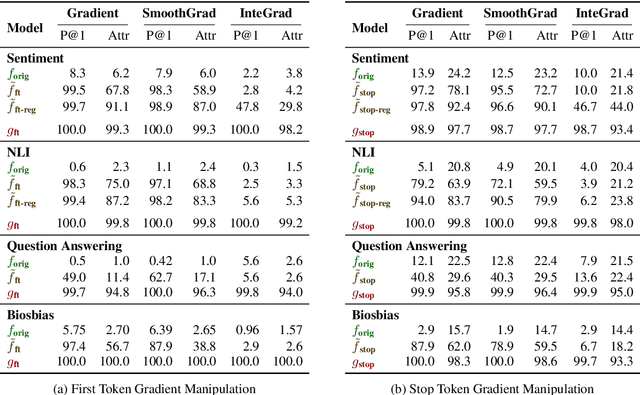
Gradient-based analysis methods, such as saliency map visualizations and adversarial input perturbations, have found widespread use in interpreting neural NLP models due to their simplicity, flexibility, and most importantly, their faithfulness. In this paper, however, we demonstrate that the gradients of a model are easily manipulable, and thus bring into question the reliability of gradient-based analyses. In particular, we merge the layers of a target model with a Facade that overwhelms the gradients without affecting the predictions. This Facade can be trained to have gradients that are misleading and irrelevant to the task, such as focusing only on the stop words in the input. On a variety of NLP tasks (text classification, NLI, and QA), we show that our method can manipulate numerous gradient-based analysis techniques: saliency maps, input reduction, and adversarial perturbations all identify unimportant or targeted tokens as being highly important. The code and a tutorial of this paper is available at http://ucinlp.github.io/facade.
Differentially Private Language Models Benefit from Public Pre-training
Sep 13, 2020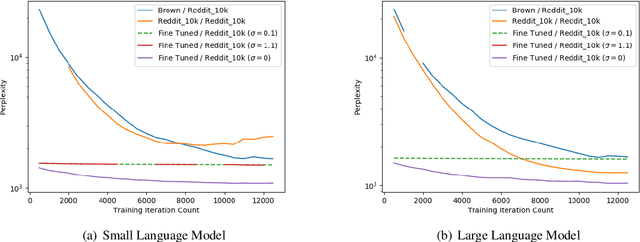


Language modeling is a keystone task in natural language processing. When training a language model on sensitive information, differential privacy (DP) allows us to quantify the degree to which our private data is protected. However, training algorithms which enforce differential privacy often lead to degradation in model quality. We study the feasibility of learning a language model which is simultaneously high-quality and privacy preserving by tuning a public base model on a private corpus. We find that DP fine-tuning boosts the performance of language models in the private domain, making the training of such models possible.
Generative Modeling for Atmospheric Convection
Jul 03, 2020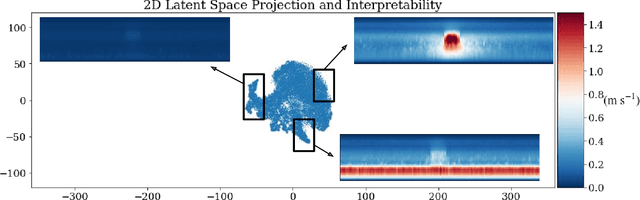
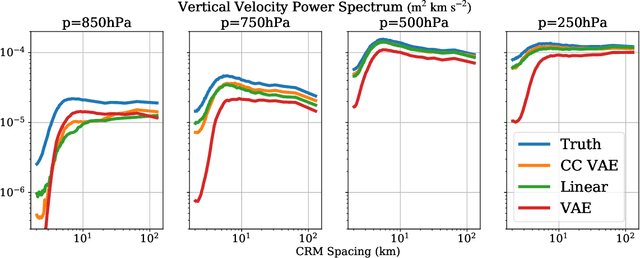
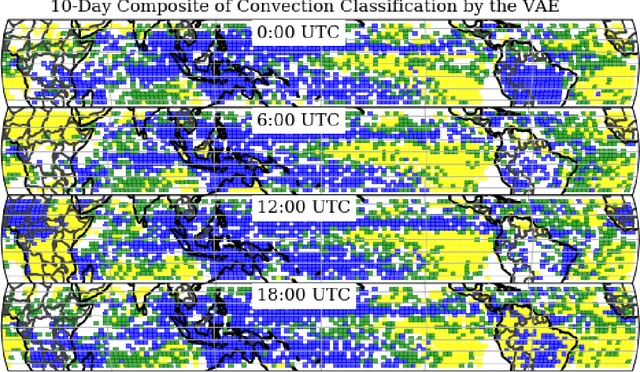
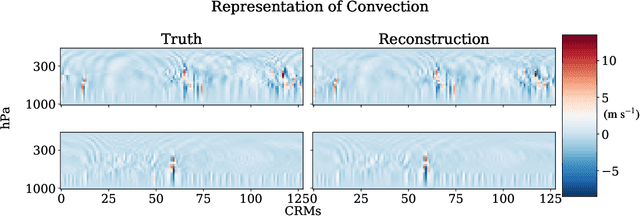
To improve climate modeling, we need a better understanding of multi-scale atmospheric dynamics--the relationship between large scale environment and small-scale storm formation, morphology and propagation--as well as superior stochastic parameterization of convective organization. We analyze raw output from ~6 million instances of explicitly simulated convection spanning all global geographic regimes of convection in the tropics, focusing on the vertical velocities extracted every 15 minutes from ~4 hundred thousands separate instances of a storm-permitting moist turbulence model embedded within a multi-scale global model of the atmosphere. Generative modeling techniques applied on high-resolution climate data for representation learning hold the potential to drive next-generation parameterization and breakthroughs in understanding of convection and storm development. To that end, we design and implement a specialized Variational Autoencoder (VAE) to perform structural replication, dimensionality reduction and clustering on these cloud-resolving vertical velocity outputs. Our VAE reproduces the structure of disparate classes of convection, successfully capturing both their magnitude and variances. This VAE thus provides a novel way to perform unsupervised grouping of convective organization in multi-scale simulations of the atmosphere in a physically sensible manner. The success of our VAE in structural emulation, learning physical meaning in convective transitions and anomalous vertical velocity field detection may help set the stage for developing generative models for stochastic parameterization that might one day replace explicit convection calculations.
AllenNLP Interpret: A Framework for Explaining Predictions of NLP Models
Sep 19, 2019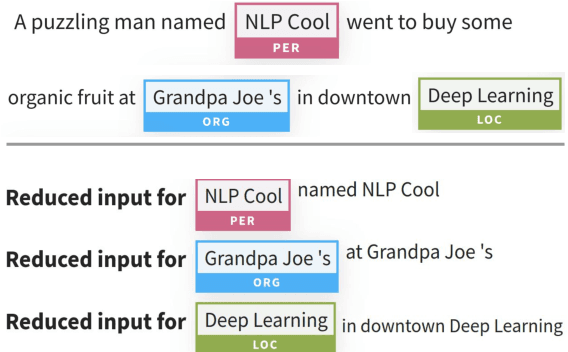

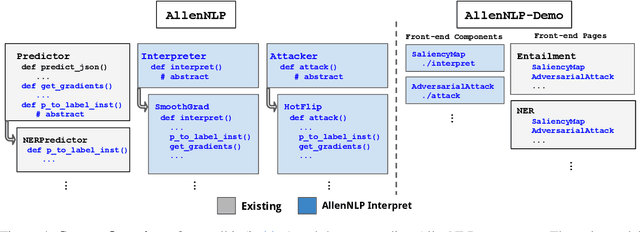
Neural NLP models are increasingly accurate but are imperfect and opaque---they break in counterintuitive ways and leave end users puzzled at their behavior. Model interpretation methods ameliorate this opacity by providing explanations for specific model predictions. Unfortunately, existing interpretation codebases make it difficult to apply these methods to new models and tasks, which hinders adoption for practitioners and burdens interpretability researchers. We introduce AllenNLP Interpret, a flexible framework for interpreting NLP models. The toolkit provides interpretation primitives (e.g., input gradients) for any AllenNLP model and task, a suite of built-in interpretation methods, and a library of front-end visualization components. We demonstrate the toolkit's flexibility and utility by implementing live demos for five interpretation methods (e.g., saliency maps and adversarial attacks) on a variety of models and tasks (e.g., masked language modeling using BERT and reading comprehension using BiDAF). These demos, alongside our code and tutorials, are available at https://allennlp.org/interpret .