 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetaining by Doing: The Role of On-Policy Data in Mitigating Forgetting
Oct 21, 2025
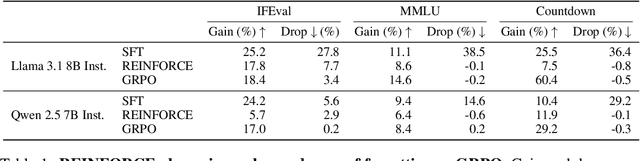
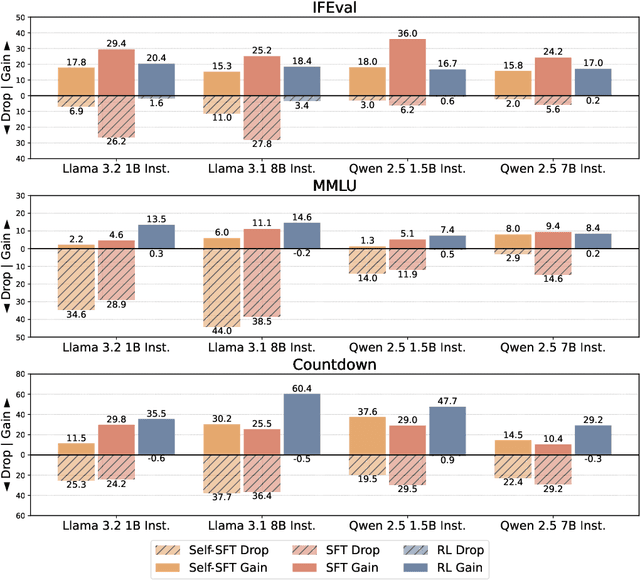
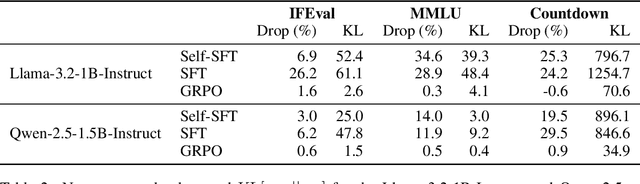
Adapting language models (LMs) to new tasks via post-training carries the risk of degrading existing capabilities -- a phenomenon classically known as catastrophic forgetting. In this paper, toward identifying guidelines for mitigating this phenomenon, we systematically compare the forgetting patterns of two widely adopted post-training methods: supervised fine-tuning (SFT) and reinforcement learning (RL). Our experiments reveal a consistent trend across LM families (Llama, Qwen) and tasks (instruction following, general knowledge, and arithmetic reasoning): RL leads to less forgetting than SFT while achieving comparable or higher target task performance. To investigate the cause for this difference, we consider a simplified setting in which the LM is modeled as a mixture of two distributions, one corresponding to prior knowledge and the other to the target task. We identify that the mode-seeking nature of RL, which stems from its use of on-policy data, enables keeping prior knowledge intact when learning the target task. We then verify this insight by demonstrating that the use on-policy data underlies the robustness of RL to forgetting in practical settings, as opposed to other algorithmic choices such as the KL regularization or advantage estimation. Lastly, as a practical implication, our results highlight the potential of mitigating forgetting using approximately on-policy data, which can be substantially more efficient to obtain than fully on-policy data.
$τ^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
Jun 09, 2025Existing benchmarks for conversational AI agents simulate single-control environments, where only the AI agent can use tools to interact with the world, while the user remains a passive information provider. This differs from real-world scenarios like technical support, where users need to actively participate in modifying the state of the (shared) world. In order to address this gap, we introduce $\tau^2$-bench, with four key contributions: 1) A novel Telecom dual-control domain modeled as a Dec-POMDP, where both agent and user make use of tools to act in a shared, dynamic environment that tests both agent coordination and communication, 2) A compositional task generator that programmatically creates diverse, verifiable tasks from atomic components, ensuring domain coverage and controlled complexity, 3) A reliable user simulator tightly coupled with the environment, whose behavior is constrained by tools and observable states, improving simulation fidelity, 4) Fine-grained analysis of agent performance through multiple ablations including separating errors arising from reasoning vs communication/coordination. In particular, our experiments show significant performance drops when agents shift from no-user to dual-control, highlighting the challenges of guiding users. Overall, $\tau^2$-bench provides a controlled testbed for agents that must both reason effectively and guide user actions.
Contextual Experience Replay for Self-Improvement of Language Agents
Jun 07, 2025
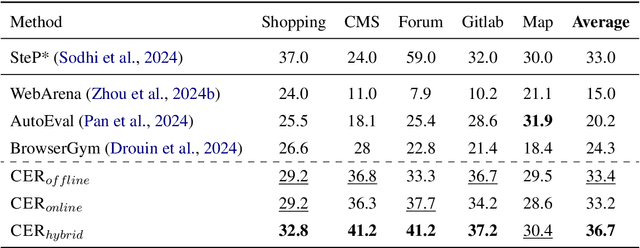


Large language model (LLM) agents have been applied to sequential decision-making tasks such as web navigation, but without any environment-specific experiences, they often fail in these complex tasks. Moreover, current LLM agents are not designed to continually learn from past experiences during inference time, which could be crucial for them to gain these environment-specific experiences. To address this, we propose Contextual Experience Replay (CER), a training-free framework to enable efficient self-improvement for language agents in their context window. Specifically, CER accumulates and synthesizes past experiences into a dynamic memory buffer. These experiences encompass environment dynamics and common decision-making patterns, allowing the agents to retrieve and augment themselves with relevant knowledge in new tasks, enhancing their adaptability in complex environments. We evaluate CER on the challenging WebArena and VisualWebArena benchmarks. On VisualWebArena, CER achieves a competitive performance of 31.9%. On WebArena, CER also gets a competitive average success rate of 36.7%, relatively improving the success rate of the GPT-4o agent baseline by 51.0%. We also conduct a comprehensive analysis on it to prove its efficiency, validity and understand it better.
When Models Know More Than They Can Explain: Quantifying Knowledge Transfer in Human-AI Collaboration
Jun 05, 2025Recent advancements in AI reasoning have driven substantial improvements across diverse tasks. A critical open question is whether these improvements also yields better knowledge transfer: the ability of models to communicate reasoning in ways humans can understand, apply, and learn from. To investigate this, we introduce Knowledge Integration and Transfer Evaluation (KITE), a conceptual and experimental framework for Human-AI knowledge transfer capabilities and conduct the first large-scale human study (N=118) explicitly designed to measure it. In our two-phase setup, humans first ideate with an AI on problem-solving strategies, then independently implement solutions, isolating model explanations' influence on human understanding. Our findings reveal that although model benchmark performance correlates with collaborative outcomes, this relationship is notably inconsistent, featuring significant outliers, indicating that knowledge transfer requires dedicated optimization. Our analysis identifies behavioral and strategic factors mediating successful knowledge transfer. We release our code, dataset, and evaluation framework to support future work on communicatively aligned models.
IMPersona: Evaluating Individual Level LM Impersonation
Apr 08, 2025As language models achieve increasingly human-like capabilities in conversational text generation, a critical question emerges: to what extent can these systems simulate the characteristics of specific individuals? To evaluate this, we introduce IMPersona, a framework for evaluating LMs at impersonating specific individuals' writing style and personal knowledge. Using supervised fine-tuning and a hierarchical memory-inspired retrieval system, we demonstrate that even modestly sized open-source models, such as Llama-3.1-8B-Instruct, can achieve impersonation abilities at concerning levels. In blind conversation experiments, participants (mis)identified our fine-tuned models with memory integration as human in 44.44% of interactions, compared to just 25.00% for the best prompting-based approach. We analyze these results to propose detection methods and defense strategies against such impersonation attempts. Our findings raise important questions about both the potential applications and risks of personalized language models, particularly regarding privacy, security, and the ethical deployment of such technologies in real-world contexts.
ShieldGemma 2: Robust and Tractable Image Content Moderation
Apr 01, 2025We introduce ShieldGemma 2, a 4B parameter image content moderation model built on Gemma 3. This model provides robust safety risk predictions across the following key harm categories: Sexually Explicit, Violence \& Gore, and Dangerous Content for synthetic images (e.g. output of any image generation model) and natural images (e.g. any image input to a Vision-Language Model). We evaluated on both internal and external benchmarks to demonstrate state-of-the-art performance compared to LlavaGuard \citep{helff2024llavaguard}, GPT-4o mini \citep{hurst2024gpt}, and the base Gemma 3 model \citep{gemma_2025} based on our policies. Additionally, we present a novel adversarial data generation pipeline which enables a controlled, diverse, and robust image generation. ShieldGemma 2 provides an open image moderation tool to advance multimodal safety and responsible AI development.
LoRA Soups: Merging LoRAs for Practical Skill Composition Tasks
Oct 16, 2024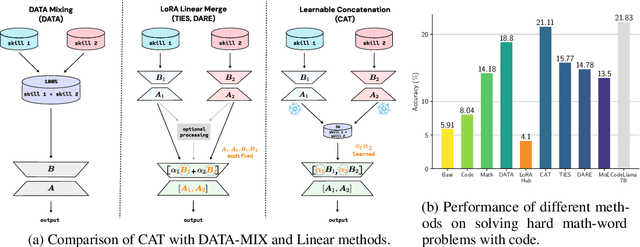



Low-Rank Adaptation (LoRA) is a popular technique for parameter-efficient fine-tuning of Large Language Models (LLMs). We study how different LoRA modules can be merged to achieve skill composition -- testing the performance of the merged model on a target task that involves combining multiple skills, each skill coming from a single LoRA. This setup is favorable when it is difficult to obtain training data for the target task and when it can be decomposed into multiple skills. First, we identify practically occurring use-cases that can be studied under the realm of skill composition, e.g. solving hard math-word problems with code, creating a bot to answer questions on proprietary manuals or about domain-specialized corpora. Our main contribution is to show that concatenation of LoRAs (CAT), which optimally averages LoRAs that were individually trained on different skills, outperforms existing model- and data- merging techniques; for instance on math-word problems, CAT beats these methods by an average of 43% and 12% respectively. Thus, this paper advocates model merging as an efficient way to solve compositional tasks and underscores CAT as a simple, compute-friendly and effective procedure. To our knowledge, this is the first work demonstrating the superiority of model merging over data mixing for binary skill composition tasks.
An Annotated Dataset of Errors in Premodern Greek and Baselines for Detecting Them
Oct 14, 2024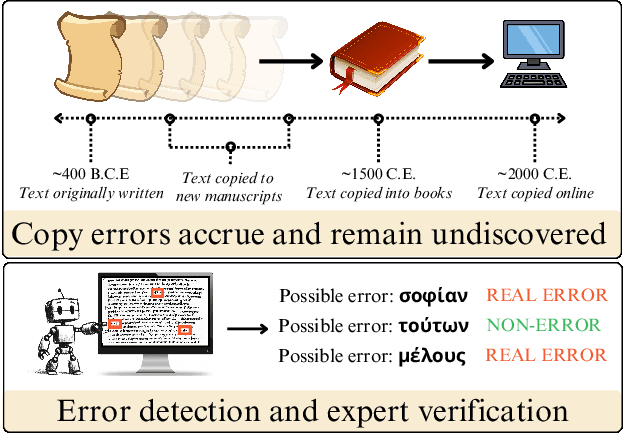
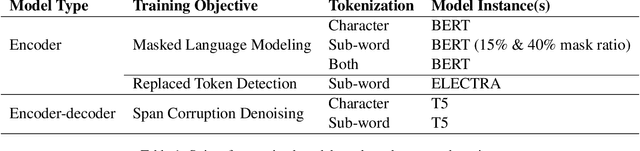
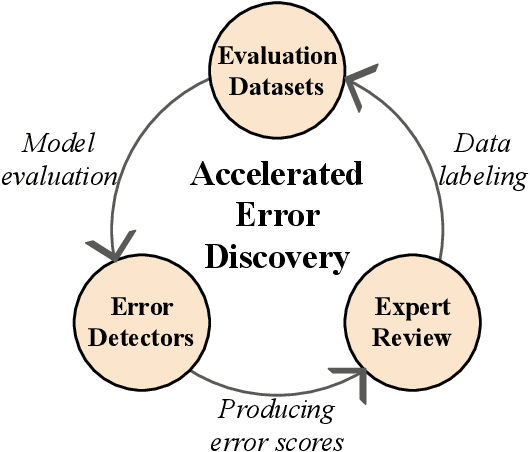
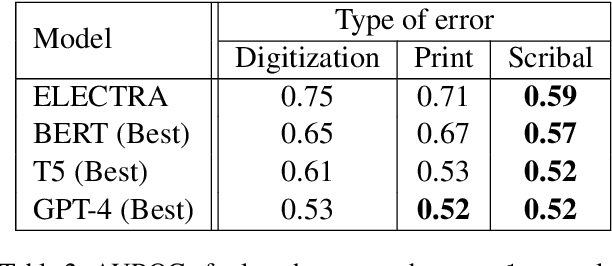
As premodern texts are passed down over centuries, errors inevitably accrue. These errors can be challenging to identify, as some have survived undetected for so long precisely because they are so elusive. While prior work has evaluated error detection methods on artificially-generated errors, we introduce the first dataset of real errors in premodern Greek, enabling the evaluation of error detection methods on errors that genuinely accumulated at some stage in the centuries-long copying process. To create this dataset, we use metrics derived from BERT conditionals to sample 1,000 words more likely to contain errors, which are then annotated and labeled by a domain expert as errors or not. We then propose and evaluate new error detection methods and find that our discriminator-based detector outperforms all other methods, improving the true positive rate for classifying real errors by 5%. We additionally observe that scribal errors are more difficult to detect than print or digitization errors. Our dataset enables the evaluation of error detection methods on real errors in premodern texts for the first time, providing a benchmark for developing more effective error detection algorithms to assist scholars in restoring premodern works.
EnIGMA: Enhanced Interactive Generative Model Agent for CTF Challenges
Sep 24, 2024



Although language model (LM) agents are demonstrating growing potential in many domains, their success in cybersecurity has been limited due to simplistic design and the lack of fundamental features for this domain. We present EnIGMA, an LM agent for autonomously solving Capture The Flag (CTF) challenges. EnIGMA introduces new Agent-Computer Interfaces (ACIs) to improve the success rate on CTF challenges. We establish the novel Interactive Agent Tool concept, which enables LM agents to run interactive command-line utilities essential for these challenges. Empirical analysis of EnIGMA on over 350 CTF challenges from three different benchmarks indicates that providing a robust set of new tools with demonstration of their usage helps the LM solve complex problems and achieves state-of-the-art results on the NYU CTF and Intercode-CTF benchmarks. Finally, we discuss insights on ACI design and agent behavior on cybersecurity tasks that highlight the need to adapt real-world tools for LM agents.
LLMs are Superior Feedback Providers: Bootstrapping Reasoning for Lie Detection with Self-Generated Feedback
Aug 25, 2024



Large Language Models (LLMs) excel at generating human-like dialogues and comprehending text. However, understanding the subtleties of complex exchanges in language remains a challenge. We propose a bootstrapping framework that leverages self-generated feedback to enhance LLM reasoning capabilities for lie detection. The framework consists of three stages: suggestion, feedback collection, and modification. In the suggestion stage, a cost-effective language model generates initial predictions based on game state and dialogue. The feedback-collection stage involves a language model providing feedback on these predictions. In the modification stage, a more advanced language model refines the initial predictions using the auto-generated feedback. We investigate the application of the proposed framework for detecting betrayal and deception in Diplomacy games, and compare it with feedback from professional human players. The LLM-generated feedback exhibits superior quality and significantly enhances the performance of the model. Our approach achieves a 39% improvement over the zero-shot baseline in lying-F1 without the need for any training data, rivaling state-of-the-art supervised learning results.