 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-ERM: Sample-Efficient Program Learning via LLM-Guided Search
Oct 16, 2025We seek algorithms for program learning that are both sample-efficient and computationally feasible. Classical results show that targets admitting short program descriptions (e.g., with short ``python code'') can be learned with a ``small'' number of examples (scaling with the size of the code) via length-first program enumeration, but the search is exponential in description length. Consequently, Gradient-based training avoids this cost yet can require exponentially many samples on certain short-program families. To address this gap, we introduce LLM-ERM, a propose-and-verify framework that replaces exhaustive enumeration with an LLM-guided search over candidate programs while retaining ERM-style selection on held-out data. Specifically, we draw $k$ candidates with a pretrained reasoning-augmented LLM, compile and check each on the data, and return the best verified hypothesis, with no feedback, adaptivity, or gradients. Theoretically, we show that coordinate-wise online mini-batch SGD requires many samples to learn certain short programs. {\em Empirically, LLM-ERM solves tasks such as parity variants, pattern matching, and primality testing with as few as 200 samples, while SGD-trained transformers overfit even with 100,000 samples}. These results indicate that language-guided program synthesis recovers much of the statistical efficiency of finite-class ERM while remaining computationally tractable, offering a practical route to learning succinct hypotheses beyond the reach of gradient-based training.
A Taxonomy of Transcendence
Aug 25, 2025Although language models are trained to mimic humans, the resulting systems display capabilities beyond the scope of any one person. To understand this phenomenon, we use a controlled setting to identify properties of the training data that lead a model to transcend the performance of its data sources. We build on previous work to outline three modes of transcendence, which we call skill denoising, skill selection, and skill generalization. We then introduce a knowledge graph-based setting in which simulated experts generate data based on their individual expertise. We highlight several aspects of data diversity that help to enable the model's transcendent capabilities. Additionally, our data generation setting offers a controlled testbed that we hope is valuable for future research in the area.
Decomposing Elements of Problem Solving: What "Math" Does RL Teach?
May 28, 2025Mathematical reasoning tasks have become prominent benchmarks for assessing the reasoning capabilities of LLMs, especially with reinforcement learning (RL) methods such as GRPO showing significant performance gains. However, accuracy metrics alone do not support fine-grained assessment of capabilities and fail to reveal which problem-solving skills have been internalized. To better understand these capabilities, we propose to decompose problem solving into fundamental capabilities: Plan (mapping questions to sequences of steps), Execute (correctly performing solution steps), and Verify (identifying the correctness of a solution). Empirically, we find that GRPO mainly enhances the execution skill-improving execution robustness on problems the model already knows how to solve-a phenomenon we call temperature distillation. More importantly, we show that RL-trained models struggle with fundamentally new problems, hitting a 'coverage wall' due to insufficient planning skills. To explore RL's impact more deeply, we construct a minimal, synthetic solution-tree navigation task as an analogy for mathematical problem-solving. This controlled setup replicates our empirical findings, confirming RL primarily boosts execution robustness. Importantly, in this setting, we identify conditions under which RL can potentially overcome the coverage wall through improved exploration and generalization to new solution paths. Our findings provide insights into the role of RL in enhancing LLM reasoning, expose key limitations, and suggest a path toward overcoming these barriers. Code is available at https://github.com/cfpark00/RL-Wall.
Let Me Think! A Long Chain-of-Thought Can Be Worth Exponentially Many Short Ones
May 27, 2025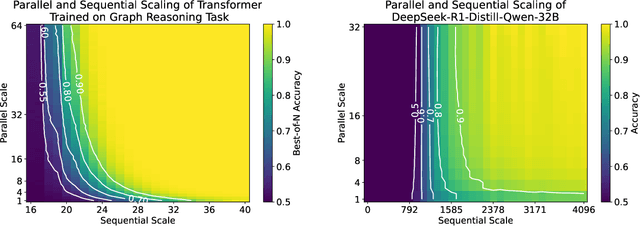

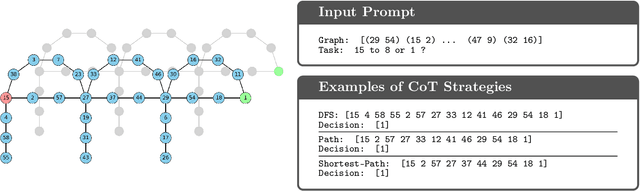
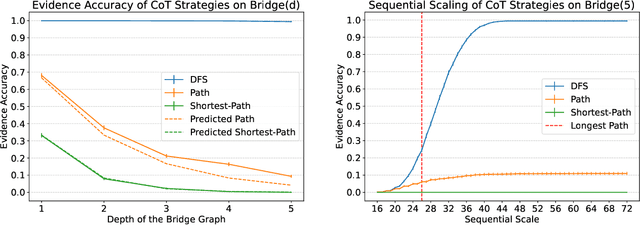
Inference-time computation has emerged as a promising scaling axis for improving large language model reasoning. However, despite yielding impressive performance, the optimal allocation of inference-time computation remains poorly understood. A central question is whether to prioritize sequential scaling (e.g., longer chains of thought) or parallel scaling (e.g., majority voting across multiple short chains of thought). In this work, we seek to illuminate the landscape of test-time scaling by demonstrating the existence of reasoning settings where sequential scaling offers an exponential advantage over parallel scaling. These settings are based on graph connectivity problems in challenging distributions of graphs. We validate our theoretical findings with comprehensive experiments across a range of language models, including models trained from scratch for graph connectivity with different chain of thought strategies as well as large reasoning models.
The Power of Random Features and the Limits of Distribution-Free Gradient Descent
May 15, 2025We study the relationship between gradient-based optimization of parametric models (e.g., neural networks) and optimization of linear combinations of random features. Our main result shows that if a parametric model can be learned using mini-batch stochastic gradient descent (bSGD) without making assumptions about the data distribution, then with high probability, the target function can also be approximated using a polynomial-sized combination of random features. The size of this combination depends on the number of gradient steps and numerical precision used in the bSGD process. This finding reveals fundamental limitations of distribution-free learning in neural networks trained by gradient descent, highlighting why making assumptions about data distributions is often crucial in practice. Along the way, we also introduce a new theoretical framework called average probabilistic dimension complexity (adc), which extends the probabilistic dimension complexity developed by Kamath et al. (2020). We prove that adc has a polynomial relationship with statistical query dimension, and use this relationship to demonstrate an infinite separation between adc and standard dimension complexity.
Echo Chamber: RL Post-training Amplifies Behaviors Learned in Pretraining
Apr 10, 2025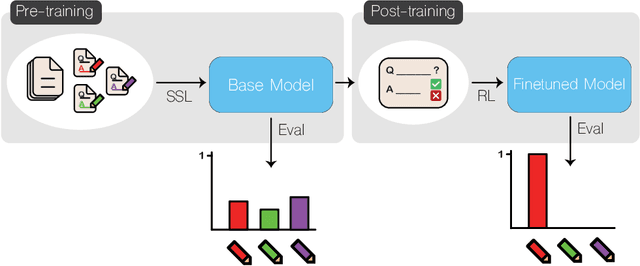
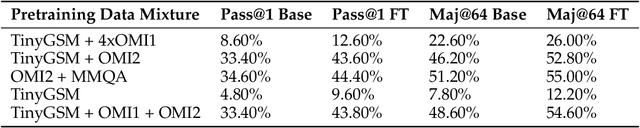
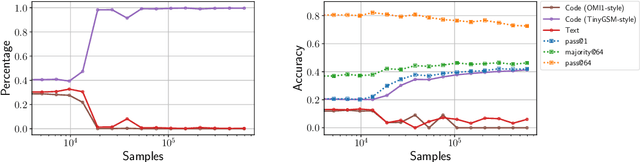
Reinforcement learning (RL)-based fine-tuning has become a crucial step in post-training language models for advanced mathematical reasoning and coding. Following the success of frontier reasoning models, recent work has demonstrated that RL fine-tuning consistently improves performance, even in smaller-scale models; however, the underlying mechanisms driving these improvements are not well-understood. Understanding the effects of RL fine-tuning requires disentangling its interaction with pretraining data composition, hyperparameters, and model scale, but such problems are exacerbated by the lack of transparency regarding the training data used in many existing models. In this work, we present a systematic end-to-end study of RL fine-tuning for mathematical reasoning by training models entirely from scratch on different mixtures of fully open datasets. We investigate the effects of various RL fine-tuning algorithms (PPO, GRPO, and Expert Iteration) across models of different scales. Our study reveals that RL algorithms consistently converge towards a dominant output distribution, amplifying patterns in the pretraining data. We also find that models of different scales trained on the same data mixture will converge to distinct output distributions, suggesting that there are scale-dependent biases in model generalization. Moreover, we find that RL post-training on simpler questions can lead to performance gains on harder ones, indicating that certain reasoning capabilities generalize across tasks. Our findings show that small-scale proxies in controlled settings can elicit interesting insights regarding the role of RL in shaping language model behavior.
To Backtrack or Not to Backtrack: When Sequential Search Limits Model Reasoning
Apr 09, 2025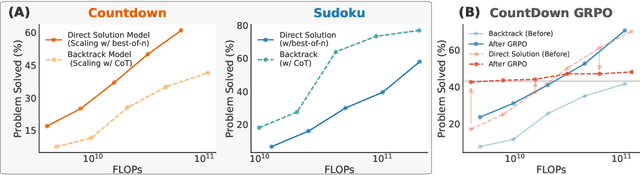

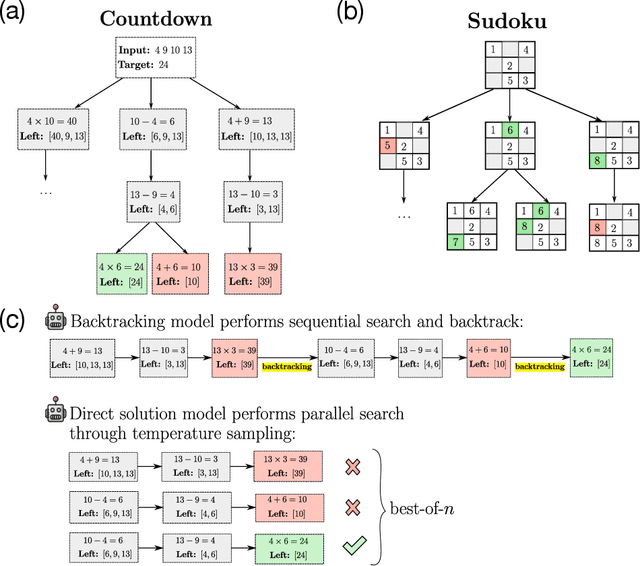
Recent advancements in large language models have significantly improved their reasoning abilities, particularly through techniques involving search and backtracking. Backtracking naturally scales test-time compute by enabling sequential, linearized exploration via long chain-of-thought (CoT) generation. However, this is not the only strategy for scaling test-time compute: parallel sampling with best-of-n selection provides an alternative that generates diverse solutions simultaneously. Despite the growing adoption of sequential search, its advantages over parallel sampling--especially under a fixed compute budget remain poorly understood. In this paper, we systematically compare these two approaches on two challenging reasoning tasks: CountDown and Sudoku. Surprisingly, we find that sequential search underperforms parallel sampling on CountDown but outperforms it on Sudoku, suggesting that backtracking is not universally beneficial. We identify two factors that can cause backtracking to degrade performance: (1) training on fixed search traces can lock models into suboptimal strategies, and (2) explicit CoT supervision can discourage "implicit" (non-verbalized) reasoning. Extending our analysis to reinforcement learning (RL), we show that models with backtracking capabilities benefit significantly from RL fine-tuning, while models without backtracking see limited, mixed gains. Together, these findings challenge the assumption that backtracking universally enhances LLM reasoning, instead revealing a complex interaction between task structure, training data, model scale, and learning paradigm.
The Role of Sparsity for Length Generalization in Transformers
Feb 24, 2025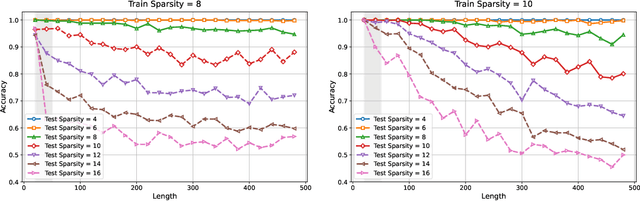

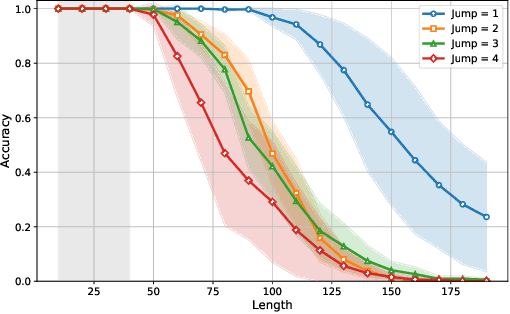
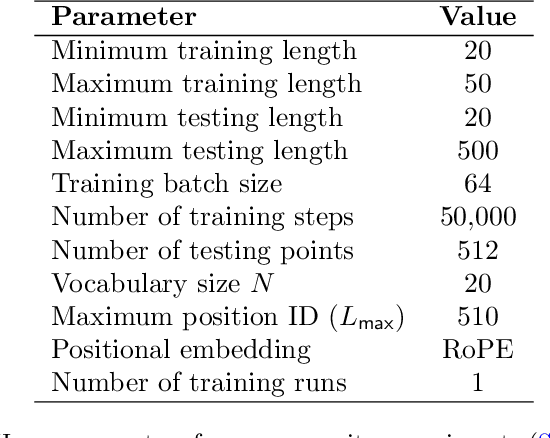
Training large language models to predict beyond their training context lengths has drawn much attention in recent years, yet the principles driving such behavior of length generalization remain underexplored. We propose a new theoretical framework to study length generalization for the next-token prediction task, as performed by decoder-only transformers. Conceptually, we show that length generalization occurs as long as each predicted token depends on a small (fixed) number of previous tokens. We formalize such tasks via a notion we call $k$-sparse planted correlation distributions, and show that an idealized model of transformers which generalize attention heads successfully length-generalize on such tasks. As a bonus, our theoretical model justifies certain techniques to modify positional embeddings which have been introduced to improve length generalization, such as position coupling. We support our theoretical results with experiments on synthetic tasks and natural language, which confirm that a key factor driving length generalization is a ``sparse'' dependency structure of each token on the previous ones. Inspired by our theory, we introduce Predictive Position Coupling, which trains the transformer to predict the position IDs used in a positional coupling approach. Predictive Position Coupling thereby allows us to broaden the array of tasks to which position coupling can successfully be applied to achieve length generalization.
Loss-to-Loss Prediction: Scaling Laws for All Datasets
Nov 19, 2024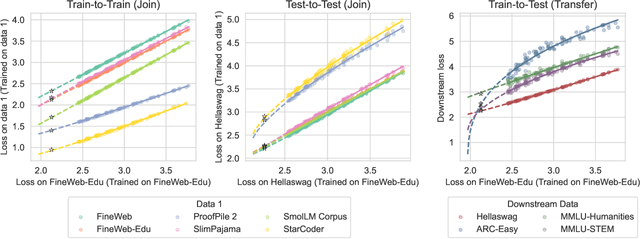
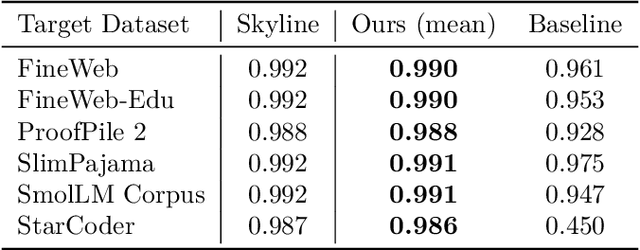
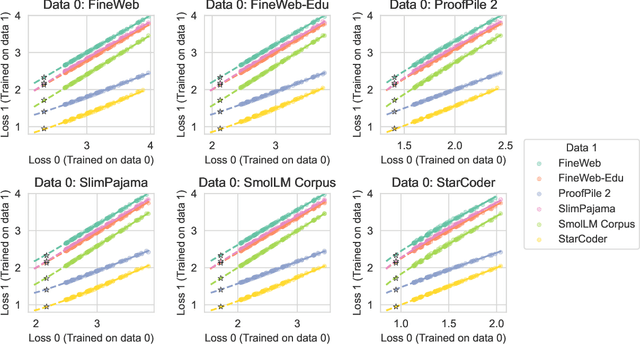

While scaling laws provide a reliable methodology for predicting train loss across compute scales for a single data distribution, less is known about how these predictions should change as we change the distribution. In this paper, we derive a strategy for predicting one loss from another and apply it to predict across different pre-training datasets and from pre-training data to downstream task data. Our predictions extrapolate well even at 20x the largest FLOP budget used to fit the curves. More precisely, we find that there are simple shifted power law relationships between (1) the train losses of two models trained on two separate datasets when the models are paired by training compute (train-to-train), (2) the train loss and the test loss on any downstream distribution for a single model (train-to-test), and (3) the test losses of two models trained on two separate train datasets (test-to-test). The results hold up for pre-training datasets that differ substantially (some are entirely code and others have no code at all) and across a variety of downstream tasks. Finally, we find that in some settings these shifted power law relationships can yield more accurate predictions than extrapolating single-dataset scaling laws.
Mixture of Parrots: Experts improve memorization more than reasoning
Oct 24, 2024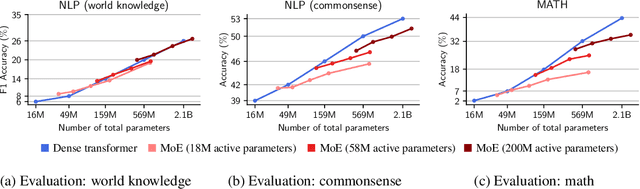
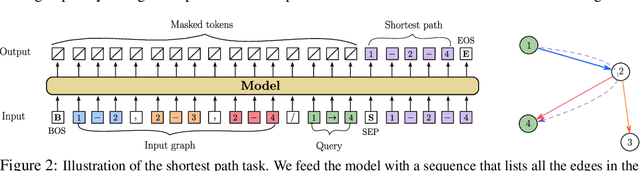
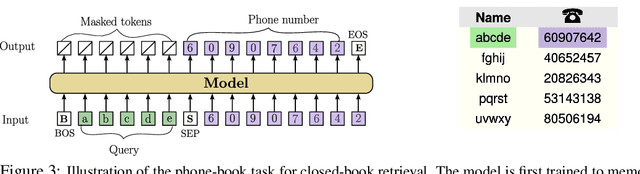
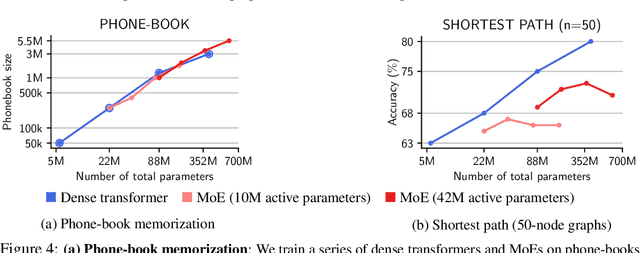
The Mixture-of-Experts (MoE) architecture enables a significant increase in the total number of model parameters with minimal computational overhead. However, it is not clear what performance tradeoffs, if any, exist between MoEs and standard dense transformers. In this paper, we show that as we increase the number of experts (while fixing the number of active parameters), the memorization performance consistently increases while the reasoning capabilities saturate. We begin by analyzing the theoretical limitations of MoEs at reasoning. We prove that there exist graph problems that cannot be solved by any number of experts of a certain width; however, the same task can be easily solved by a dense model with a slightly larger width. On the other hand, we find that on memory-intensive tasks, MoEs can effectively leverage a small number of active parameters with a large number of experts to memorize the data. We empirically validate these findings on synthetic graph problems and memory-intensive closed book retrieval tasks. Lastly, we pre-train a series of MoEs and dense transformers and evaluate them on commonly used benchmarks in math and natural language. We find that increasing the number of experts helps solve knowledge-intensive tasks, but fails to yield the same benefits for reasoning tasks.