 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Problem Solving: UOJ-Bench for Evaluating Code Generation, Hacking, and Repair in Competitive Programming
Jun 11, 2026Despite strong performance in competitive programming, the role of Large Language Models (LLMs) in supporting human learning in the same setting remains largely unexplored. In this work, we introduce UOJ-Bench, a benchmark designed to evaluate not only the problem-solving ability of LLMs, but also their ability to identify errors in human-written code -- a crucial educational activity traditionally supported by running test cases over online judge systems. UOJ-Bench consists of three distinct tasks: code generation, code hacking, and code repair, all constructed from real-world code submissions on the Universal Online Judge (UOJ) and evaluated through UOJ's native judging infrastructure. Our results show that under one-shot evaluation, even the strongest models fail to identify errors in more than 50% of a set of submissions that have been found to be incorrect by UOJ users. While test-time scaling improves success rates to above 90%, the substantial computational costs incurred from model inference limit its practicality for large-scale deployment. Despite these limitations, we find that the best-performing models under test-time scaling can uncover errors in over 5% of full-score submissions across roughly 30 problems, suggesting that frontier LLMs can already provide complementary signals beyond standard judging systems.
SlopCodeBench: Benchmarking How Coding Agents Degrade Over Long-Horizon Iterative Tasks
Mar 25, 2026Software development is iterative, yet agentic coding benchmarks overwhelmingly evaluate single-shot solutions against complete specifications. Code can pass the test suite but become progressively harder to extend. Recent iterative benchmarks attempt to close this gap, but constrain the agent's design decisions too tightly to faithfully measure how code quality shapes future extensions. We introduce SlopCodeBench, a language-agnostic benchmark comprising 20 problems and 93 checkpoints, in which agents repeatedly extend their own prior solutions under evolving specifications that force architectural decisions without prescribing internal structure. We track two trajectory-level quality signals: verbosity, the fraction of redundant or duplicated code, and structural erosion, the share of complexity mass concentrated in high-complexity functions. No agent solves any problem end-to-end across 11 models; the highest checkpoint solve rate is 17.2%. Quality degrades steadily: erosion rises in 80% of trajectories and verbosity in 89.8%. Against 48 open-source Python repositories, agent code is 2.2x more verbose and markedly more eroded. Tracking 20 of those repositories over time shows that human code stays flat, while agent code deteriorates with each iteration. A prompt-intervention study shows that initial quality can be improved, but it does not halt degradation. These results demonstrate that pass-rate benchmarks systematically undermeasure extension robustness, and that current agents lack the design discipline iterative software development demands.
Vibe Code Bench: Evaluating AI Models on End-to-End Web Application Development
Mar 04, 2026Code generation has emerged as one of AI's highest-impact use cases, yet existing benchmarks measure isolated tasks rather than the complete "zero-to-one" process of building a working application from scratch. We introduce Vibe Code Bench, a benchmark of 100 web application specifications (50 public validation, 50 held-out test) with 964 browser-based workflows comprising 10,131 substeps, evaluated against deployed applications by an autonomous browser agent. Across 16 frontier models, the best achieves only 58.0% accuracy on the test split, revealing that reliable end-to-end application development remains a frontier challenge. We identify self-testing during generation as a strong performance predictor (Pearson r=0.72), and show through a completed human alignment study that evaluator selection materially affects outcomes (31.8-93.6% pairwise step-level agreement). Our contributions include (1) a novel benchmark dataset and browser-based evaluation pipeline for end-to-end web application development, (2) a comprehensive evaluation of 16 frontier models with cost, latency, and error analysis, and (3) an evaluator alignment protocol with both cross-model and human annotation results.
Completion $ eq$ Collaboration: Scaling Collaborative Effort with Agents
Oct 30, 2025Current evaluations of agents remain centered around one-shot task completion, failing to account for the inherently iterative and collaborative nature of many real-world problems, where human goals are often underspecified and evolve. We argue for a shift from building and assessing task completion agents to developing collaborative agents, assessed not only by the quality of their final outputs but by how well they engage with and enhance human effort throughout the problem-solving process. To support this shift, we introduce collaborative effort scaling, a framework that captures how an agent's utility grows with increasing user involvement. Through case studies and simulated evaluations, we show that state-of-the-art agents often underperform in multi-turn, real-world scenarios, revealing a missing ingredient in agent design: the ability to sustain engagement and scaffold user understanding. Collaborative effort scaling offers a lens for diagnosing agent behavior and guiding development toward more effective interactions.
Investigating Advanced Reasoning of Large Language Models via Black-Box Interaction
Aug 26, 2025Existing tasks fall short in evaluating reasoning ability of Large Language Models (LLMs) in an interactive, unknown environment. This deficiency leads to the isolated assessment of deductive, inductive, and abductive reasoning, neglecting the integrated reasoning process that is indispensable for humans discovery of real world. We introduce a novel evaluation paradigm, \textit{black-box interaction}, to tackle this challenge. A black-box is defined by a hidden function that maps a specific set of inputs to outputs. LLMs are required to unravel the hidden function behind the black-box by interacting with it in given exploration turns, and reasoning over observed input-output pairs. Leveraging this idea, we build the \textsc{Oracle} benchmark which comprises 6 types of black-box task and 96 black-boxes. 19 modern LLMs are benchmarked. o3 ranks first in 5 of the 6 tasks, achieving over 70\% accuracy on most easy black-boxes. But it still struggles with some hard black-box tasks, where its average performance drops below 40\%. Further analysis indicates a universal difficulty among LLMs: They lack the high-level planning capability to develop efficient and adaptive exploration strategies for hypothesis refinement.
Solving Inequality Proofs with Large Language Models
Jun 09, 2025Inequality proving, crucial across diverse scientific and mathematical fields, tests advanced reasoning skills such as discovering tight bounds and strategic theorem application. This makes it a distinct, demanding frontier for large language models (LLMs), offering insights beyond general mathematical problem-solving. Progress in this area is hampered by existing datasets that are often scarce, synthetic, or rigidly formal. We address this by proposing an informal yet verifiable task formulation, recasting inequality proving into two automatically checkable subtasks: bound estimation and relation prediction. Building on this, we release IneqMath, an expert-curated dataset of Olympiad-level inequalities, including a test set and training corpus enriched with step-wise solutions and theorem annotations. We also develop a novel LLM-as-judge evaluation framework, combining a final-answer judge with four step-wise judges designed to detect common reasoning flaws. A systematic evaluation of 29 leading LLMs on IneqMath reveals a surprising reality: even top models like o1 achieve less than 10% overall accuracy under step-wise scrutiny; this is a drop of up to 65.5% from their accuracy considering only final answer equivalence. This discrepancy exposes fragile deductive chains and a critical gap for current LLMs between merely finding an answer and constructing a rigorous proof. Scaling model size and increasing test-time computation yield limited gains in overall proof correctness. Instead, our findings highlight promising research directions such as theorem-guided reasoning and self-refinement. Code and data are available at https://ineqmath.github.io/.
Challenges and Paths Towards AI for Software Engineering
Mar 28, 2025AI for software engineering has made remarkable progress recently, becoming a notable success within generative AI. Despite this, there are still many challenges that need to be addressed before automated software engineering reaches its full potential. It should be possible to reach high levels of automation where humans can focus on the critical decisions of what to build and how to balance difficult tradeoffs while most routine development effort is automated away. Reaching this level of automation will require substantial research and engineering efforts across academia and industry. In this paper, we aim to discuss progress towards this in a threefold manner. First, we provide a structured taxonomy of concrete tasks in AI for software engineering, emphasizing the many other tasks in software engineering beyond code generation and completion. Second, we outline several key bottlenecks that limit current approaches. Finally, we provide an opinionated list of promising research directions toward making progress on these bottlenecks, hoping to inspire future research in this rapidly maturing field.
Mixture of Parrots: Experts improve memorization more than reasoning
Oct 24, 2024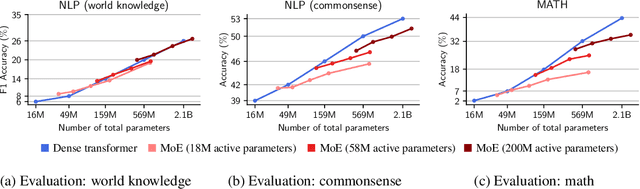
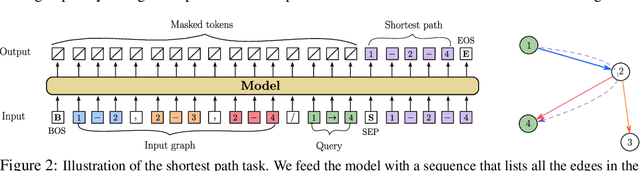
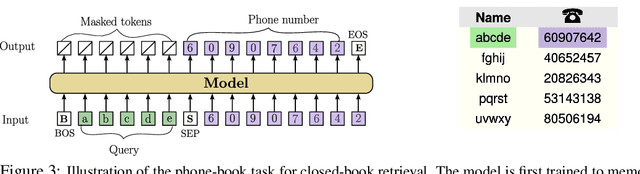
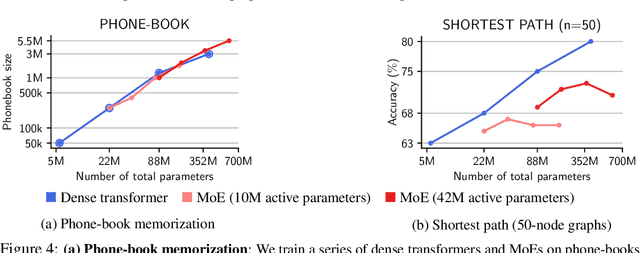
The Mixture-of-Experts (MoE) architecture enables a significant increase in the total number of model parameters with minimal computational overhead. However, it is not clear what performance tradeoffs, if any, exist between MoEs and standard dense transformers. In this paper, we show that as we increase the number of experts (while fixing the number of active parameters), the memorization performance consistently increases while the reasoning capabilities saturate. We begin by analyzing the theoretical limitations of MoEs at reasoning. We prove that there exist graph problems that cannot be solved by any number of experts of a certain width; however, the same task can be easily solved by a dense model with a slightly larger width. On the other hand, we find that on memory-intensive tasks, MoEs can effectively leverage a small number of active parameters with a large number of experts to memorize the data. We empirically validate these findings on synthetic graph problems and memory-intensive closed book retrieval tasks. Lastly, we pre-train a series of MoEs and dense transformers and evaluate them on commonly used benchmarks in math and natural language. We find that increasing the number of experts helps solve knowledge-intensive tasks, but fails to yield the same benefits for reasoning tasks.
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
Jun 26, 2024



Automated software engineering has been greatly empowered by the recent advances in Large Language Models (LLMs) for programming. While current benchmarks have shown that LLMs can perform various software engineering tasks like human developers, the majority of their evaluations are limited to short and self-contained algorithmic tasks. Solving challenging and practical programming tasks requires the capability of utilizing diverse function calls as tools to efficiently implement functionalities like data analysis and web development. In addition, using multiple tools to solve a task needs compositional reasoning by accurately understanding complex instructions. Fulfilling both of these characteristics can pose a great challenge for LLMs. To assess how well LLMs can solve challenging and practical programming tasks, we introduce Bench, a benchmark that challenges LLMs to invoke multiple function calls as tools from 139 libraries and 7 domains for 1,140 fine-grained programming tasks. To evaluate LLMs rigorously, each programming task encompasses 5.6 test cases with an average branch coverage of 99%. In addition, we propose a natural-language-oriented variant of Bench, Benchi, that automatically transforms the original docstrings into short instructions only with essential information. Our extensive evaluation of 60 LLMs shows that LLMs are not yet capable of following complex instructions to use function calls precisely, with scores up to 60%, significantly lower than the human performance of 97%. The results underscore the need for further advancements in this area.
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Mar 12, 2024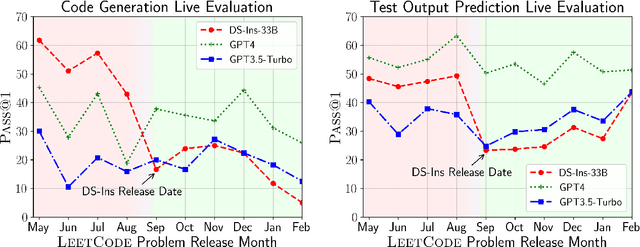


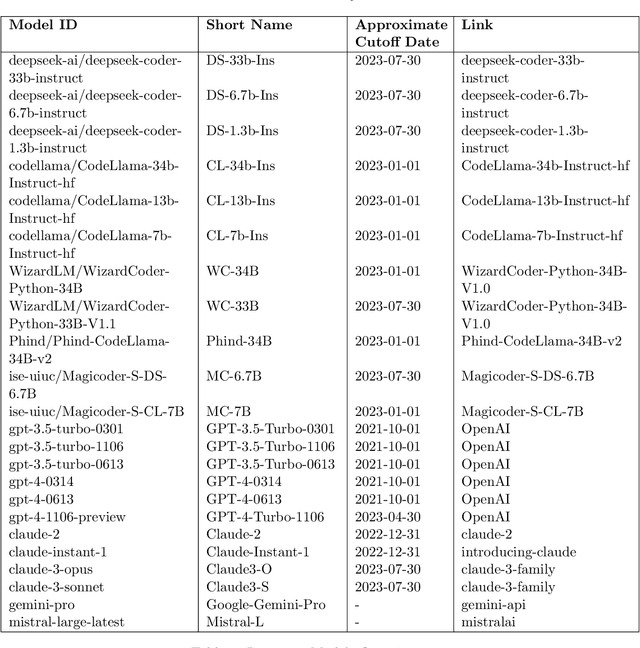
Large Language Models (LLMs) applied to code-related applications have emerged as a prominent field, attracting significant interest from both academia and industry. However, as new and improved LLMs are developed, existing evaluation benchmarks (e.g., HumanEval, MBPP) are no longer sufficient for assessing their capabilities. In this work, we propose LiveCodeBench, a comprehensive and contamination-free evaluation of LLMs for code, which continuously collects new problems over time from contests across three competition platforms, namely LeetCode, AtCoder, and CodeForces. Notably, our benchmark also focuses on a broader range of code related capabilities, such as self-repair, code execution, and test output prediction, beyond just code generation. Currently, LiveCodeBench hosts four hundred high-quality coding problems that were published between May 2023 and February 2024. We have evaluated 9 base LLMs and 20 instruction-tuned LLMs on LiveCodeBench. We present empirical findings on contamination, holistic performance comparisons, potential overfitting in existing benchmarks as well as individual model comparisons. We will release all prompts and model completions for further community analysis, along with a general toolkit for adding new scenarios and model