 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecCodeBench-V2 Technical Report
Feb 17, 2026We introduce SecCodeBench-V2, a publicly released benchmark for evaluating Large Language Model (LLM) copilots' capabilities of generating secure code. SecCodeBench-V2 comprises 98 generation and fix scenarios derived from Alibaba Group's industrial productions, where the underlying security issues span 22 common CWE (Common Weakness Enumeration) categories across five programming languages: Java, C, Python, Go, and Node.js. SecCodeBench-V2 adopts a function-level task formulation: each scenario provides a complete project scaffold and requires the model to implement or patch a designated target function under fixed interfaces and dependencies. For each scenario, SecCodeBench-V2 provides executable proof-of-concept (PoC) test cases for both functional validation and security verification. All test cases are authored and double-reviewed by security experts, ensuring high fidelity, broad coverage, and reliable ground truth. Beyond the benchmark itself, we build a unified evaluation pipeline that assesses models primarily via dynamic execution. For most scenarios, we compile and run model-generated artifacts in isolated environments and execute PoC test cases to validate both functional correctness and security properties. For scenarios where security issues cannot be adjudicated with deterministic test cases, we additionally employ an LLM-as-a-judge oracle. To summarize performance across heterogeneous scenarios and difficulty levels, we design a Pass@K-based scoring protocol with principled aggregation over scenarios and severity, enabling holistic and comparable evaluation across models. Overall, SecCodeBench-V2 provides a rigorous and reproducible foundation for assessing the security posture of AI coding assistants, with results and artifacts released at https://alibaba.github.io/sec-code-bench. The benchmark is publicly available at https://github.com/alibaba/sec-code-bench.
Beyond Crash: Hijacking Your Autonomous Vehicle for Fun and Profit
Feb 06, 2026Autonomous Vehicles (AVs), especially vision-based AVs, are rapidly being deployed without human operators. As AVs operate in safety-critical environments, understanding their robustness in an adversarial environment is an important research problem. Prior physical adversarial attacks on vision-based autonomous vehicles predominantly target immediate safety failures (e.g., a crash, a traffic-rule violation, or a transient lane departure) by inducing a short-lived perception or control error. This paper shows a qualitatively different risk: a long-horizon route integrity compromise, where an attacker gradually steers a victim AV away from its intended route and into an attacker-chosen destination while the victim continues to drive "normally." This will not pose a danger to the victim vehicle itself, but also to potential passengers sitting inside the vehicle. In this paper, we design and implement the first adversarial framework, called JackZebra, that performs route-level hijacking of a vision-based end-to-end driving stack using a physically plausible attacker vehicle with a reconfigurable display mounted on the rear. The central challenge is temporal persistence: adversarial influence must remain effective in changing viewpoints, lighting, weather, traffic, and the victim's continual replanning -- without triggering conspicuous failures. Our key insight is to treat route hijacking as a closed-loop control problem and to convert adversarial patches into steering primitives that can be selected online via an interactive adjustment loop. Our adversarial patches are also carefully designed against worst-case background and sensor variations so that the adversarial impacts on the victim. Our evaluation shows that JackZebra can successfully hijack victim vehicles to deviate from original routes and stop at adversarial destinations with a high success rate.
TriAlignXA: An Explainable Trilemma Alignment Framework for Trustworthy Agri-product Grading
Oct 02, 2025



The 'trust deficit' in online fruit and vegetable e-commerce stems from the inability of digital transactions to provide direct sensory perception of product quality. This paper constructs a 'Trust Pyramid' model through 'dual-source verification' of consumer trust. Experiments confirm that quality is the cornerstone of trust. The study reveals an 'impossible triangle' in agricultural product grading, comprising biological characteristics, timeliness, and economic viability, highlighting the limitations of traditional absolute grading standards. To quantitatively assess this trade-off, we propose the 'Triangular Trust Index' (TTI). We redefine the role of algorithms from 'decision-makers' to 'providers of transparent decision-making bases', designing the explainable AI framework--TriAlignXA. This framework supports trustworthy online transactions within agricultural constraints through multi-objective optimization. Its core relies on three engines: the Bio-Adaptive Engine for granular quality description; the Timeliness Optimization Engine for processing efficiency; and the Economic Optimization Engine for cost control. Additionally, the "Pre-Mapping Mechanism" encodes process data into QR codes, transparently conveying quality information. Experiments on grading tasks demonstrate significantly higher accuracy than baseline models. Empirical evidence and theoretical analysis verify the framework's balancing capability in addressing the "impossible triangle". This research provides comprehensive support--from theory to practice--for building a trustworthy online produce ecosystem, establishing a critical pathway from algorithmic decision-making to consumer trust.
TurnaboutLLM: A Deductive Reasoning Benchmark from Detective Games
May 21, 2025



This paper introduces TurnaboutLLM, a novel framework and dataset for evaluating the deductive reasoning abilities of Large Language Models (LLMs) by leveraging the interactive gameplay of detective games Ace Attorney and Danganronpa. The framework tasks LLMs with identifying contradictions between testimonies and evidences within long narrative contexts, a challenging task due to the large answer space and diverse reasoning types presented by its questions. We evaluate twelve state-of-the-art LLMs on the dataset, hinting at limitations of popular strategies for enhancing deductive reasoning such as extensive thinking and Chain-of-Thought prompting. The results also suggest varying effects of context size, the number of reasoning step and answer space size on model performance. Overall, TurnaboutLLM presents a substantial challenge for LLMs' deductive reasoning abilities in complex, narrative-rich environments.
Challenges and Paths Towards AI for Software Engineering
Mar 28, 2025AI for software engineering has made remarkable progress recently, becoming a notable success within generative AI. Despite this, there are still many challenges that need to be addressed before automated software engineering reaches its full potential. It should be possible to reach high levels of automation where humans can focus on the critical decisions of what to build and how to balance difficult tradeoffs while most routine development effort is automated away. Reaching this level of automation will require substantial research and engineering efforts across academia and industry. In this paper, we aim to discuss progress towards this in a threefold manner. First, we provide a structured taxonomy of concrete tasks in AI for software engineering, emphasizing the many other tasks in software engineering beyond code generation and completion. Second, we outline several key bottlenecks that limit current approaches. Finally, we provide an opinionated list of promising research directions toward making progress on these bottlenecks, hoping to inspire future research in this rapidly maturing field.
Lobster: A GPU-Accelerated Framework for Neurosymbolic Programming
Mar 27, 2025Neurosymbolic programs combine deep learning with symbolic reasoning to achieve better data efficiency, interpretability, and generalizability compared to standalone deep learning approaches. However, existing neurosymbolic learning frameworks implement an uneasy marriage between a highly scalable, GPU-accelerated neural component with a slower symbolic component that runs on CPUs. We propose Lobster, a unified framework for harnessing GPUs in an end-to-end manner for neurosymbolic learning. Lobster maps a general neurosymbolic language based on Datalog to the GPU programming paradigm. This mapping is implemented via compilation to a new intermediate language called APM. The extra abstraction provided by APM allows Lobster to be both flexible, supporting discrete, probabilistic, and differentiable modes of reasoning on GPU hardware with a library of provenance semirings, and performant, implementing new optimization passes. We demonstrate that Lobster programs can solve interesting problems spanning the domains of natural language processing, image processing, program reasoning, bioinformatics, and planning. On a suite of 8 applications, Lobster achieves an average speedup of 5.3x over Scallop, a state-of-the-art neurosymbolic framework, and enables scaling of neurosymbolic solutions to previously infeasible tasks.
NeuroStrata: Harnessing Neurosymbolic Paradigms for Improved Design, Testability, and Verifiability of Autonomous CPS
Feb 17, 2025


Autonomous cyber-physical systems (CPSs) leverage AI for perception, planning, and control but face trust and safety certification challenges due to inherent uncertainties. The neurosymbolic paradigm replaces stochastic layers with interpretable symbolic AI, enabling determinism. While promising, challenges like multisensor fusion, adaptability, and verification remain. This paper introduces NeuroStrata, a neurosymbolic framework to enhance the testing and verification of autonomous CPS. We outline its key components, present early results, and detail future plans.
Relational Programming with Foundation Models
Dec 19, 2024Foundation models have vast potential to enable diverse AI applications. The powerful yet incomplete nature of these models has spurred a wide range of mechanisms to augment them with capabilities such as in-context learning, information retrieval, and code interpreting. We propose Vieira, a declarative framework that unifies these mechanisms in a general solution for programming with foundation models. Vieira follows a probabilistic relational paradigm and treats foundation models as stateless functions with relational inputs and outputs. It supports neuro-symbolic applications by enabling the seamless combination of such models with logic programs, as well as complex, multi-modal applications by streamlining the composition of diverse sub-models. We implement Vieira by extending the Scallop compiler with a foreign interface that supports foundation models as plugins. We implement plugins for 12 foundation models including GPT, CLIP, and SAM. We evaluate Vieira on 9 challenging tasks that span language, vision, and structured and vector databases. Our evaluation shows that programs in Vieira are concise, can incorporate modern foundation models, and have comparable or better accuracy than competitive baselines.
Data-Efficient Learning with Neural Programs
Jun 10, 2024



Many computational tasks can be naturally expressed as a composition of a DNN followed by a program written in a traditional programming language or an API call to an LLM. We call such composites "neural programs" and focus on the problem of learning the DNN parameters when the training data consist of end-to-end input-output labels for the composite. When the program is written in a differentiable logic programming language, techniques from neurosymbolic learning are applicable, but in general, the learning for neural programs requires estimating the gradients of black-box components. We present an algorithm for learning neural programs, called ISED, that only relies on input-output samples of black-box components. For evaluation, we introduce new benchmarks that involve calls to modern LLMs such as GPT-4 and also consider benchmarks from the neurosymolic learning literature. Our evaluation shows that for the latter benchmarks, ISED has comparable performance to state-of-the-art neurosymbolic frameworks. For the former, we use adaptations of prior work on gradient approximations of black-box components as a baseline, and show that ISED achieves comparable accuracy but in a more data- and sample-efficient manner.
DISCRET: Synthesizing Faithful Explanations For Treatment Effect Estimation
Jun 02, 2024


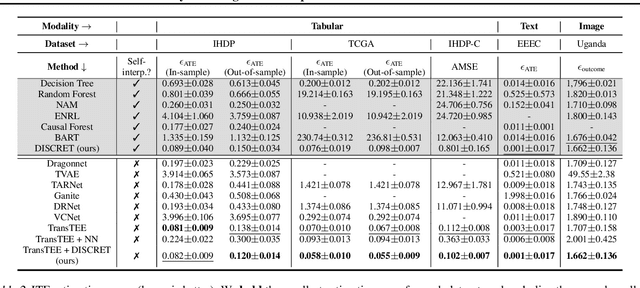
Designing faithful yet accurate AI models is challenging, particularly in the field of individual treatment effect estimation (ITE). ITE prediction models deployed in critical settings such as healthcare should ideally be (i) accurate, and (ii) provide faithful explanations. However, current solutions are inadequate: state-of-the-art black-box models do not supply explanations, post-hoc explainers for black-box models lack faithfulness guarantees, and self-interpretable models greatly compromise accuracy. To address these issues, we propose DISCRET, a self-interpretable ITE framework that synthesizes faithful, rule-based explanations for each sample. A key insight behind DISCRET is that explanations can serve dually as database queries to identify similar subgroups of samples. We provide a novel RL algorithm to efficiently synthesize these explanations from a large search space. We evaluate DISCRET on diverse tasks involving tabular, image, and text data. DISCRET outperforms the best self-interpretable models and has accuracy comparable to the best black-box models while providing faithful explanations. DISCRET is available at https://github.com/wuyinjun-1993/DISCRET-ICML2024.