 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Embodied AI Reliable: A Community Agenda from Testing to Formal Verification
Jun 02, 2026Embodied AI systems are increasingly deployed in open-world environments, yet ensuring their reliability remains a fundamental challenge. Drawing on discussions from the AAAI'26 Bridge Program on "Making Embodied AI Reliable with Testing and Formal Verification", this article argues that reliability in embodied AI is inherently a lifecycle assurance problem arising from uncertainty, human interaction, and emergent behaviors across tightly coupled system components. We identify three complementary directions toward reliable embodied AI: (1) trustworthy scenario-based testing supported by validated specifications and meaningful coverage metrics, (2) compositional verification enabled by structured symbolic representations of system behavior and environmental context, and (3) runtime assurance mechanisms capable of adapting to uncertainty and distribution shifts during deployment. Rather than treating these approaches independently, we advocate integrated assurance workflows that connect testing, verification, and runtime adaptation through shared neuro-symbolic representations and continuous feedback across the system lifecycle. Such integration provides a foundation for building trustworthy embodied AI systems that can operate safely and reliably in complex real-world environments.
From Particles to Perils: SVGD-Based Hazardous Scenario Generation for Autonomous Driving Systems Testing
Apr 20, 2026Simulation-based testing of autonomous driving systems (ADS) must uncover realistic and diverse failures in dense, heterogeneous traffic. However, existing search-based seeding methods (e.g., genetic algorithms) struggle in high-dimensional spaces, often collapsing to limited modes and missing many failure scenarios. We present PtoP, a framework that combines adaptive random seed generation with Stein Variational Gradient Descent (SVGD) to produce diverse, failure-inducing initial conditions. SVGD balances attraction toward high-risk regions and repulsion among particles, yielding risk-seeking yet well-distributed seeds across multiple failure modes. PtoP is plug-and-play and enhances existing online testing methods (e.g., reinforcement learning--based testers) by providing principled seeds. Evaluation in CARLA on two industry-grade ADS (Apollo, Autoware) and a native end-to-end system shows that PtoP improves safety violation rate (up to 27.68%), scenario diversity (9.6%), and map coverage (16.78%) over baselines.
Visual Marker Search for Autonomous Drone Landing in Diverse Urban Environments
Jan 16, 2026Marker-based landing is widely used in drone delivery and return-to-base systems for its simplicity and reliability. However, most approaches assume idealized landing site visibility and sensor performance, limiting robustness in complex urban settings. We present a simulation-based evaluation suite on the AirSim platform with systematically varied urban layouts, lighting, and weather to replicate realistic operational diversity. Using onboard camera sensors (RGB for marker detection and depth for obstacle avoidance), we benchmark two heuristic coverage patterns and a reinforcement learning-based agent, analyzing how exploration strategy and scene complexity affect success rate, path efficiency, and robustness. Results underscore the need to evaluate marker-based autonomous landing under diverse, sensor-relevant conditions to guide the development of reliable aerial navigation systems.
Experiences from Benchmarking Vision-Language-Action Models for Robotic Manipulation
Nov 14, 2025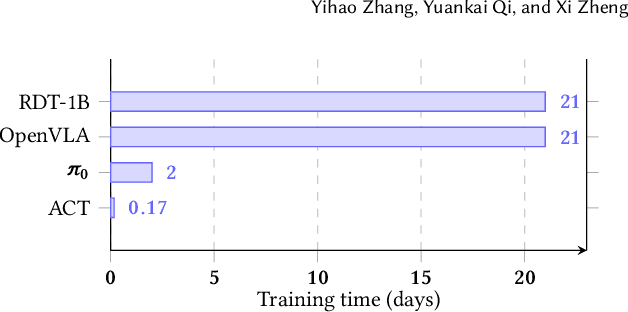


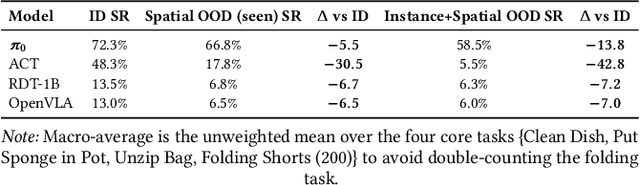
Foundation models applied in robotics, particularly \textbf{Vision--Language--Action (VLA)} models, hold great promise for achieving general-purpose manipulation. Yet, systematic real-world evaluations and cross-model comparisons remain scarce. This paper reports our \textbf{empirical experiences} from benchmarking four representative VLAs -- \textbf{ACT}, \textbf{OpenVLA--OFT}, \textbf{RDT-1B}, and \boldmath{$π_0$} -- across four manipulation tasks conducted in both simulation and on the \textbf{ALOHA Mobile} platform. We establish a \textbf{standardized evaluation framework} that measures performance along three key dimensions: (1) \textit{accuracy and efficiency} (success rate and time-to-success), (2) \textit{adaptability} across in-distribution, spatial out-of-distribution, and instance-plus-spatial out-of-distribution settings, and (3) \textit{language instruction-following accuracy}. Through this process, we observe that \boldmath{$π_0$} demonstrates superior adaptability in out-of-distribution scenarios, while \textbf{ACT} provides the highest stability in-distribution. Further analysis highlights differences in computational demands, data-scaling behavior, and recurring failure modes such as near-miss grasps, premature releases, and long-horizon state drift. These findings reveal practical trade-offs among VLA model architectures in balancing precision, generalization, and deployment cost, offering actionable insights for selecting and deploying VLAs in real-world robotic manipulation tasks.
A Step-by-Step Guide to Creating a Robust Autonomous Drone Testing Pipeline
Jun 13, 2025



Autonomous drones are rapidly reshaping industries ranging from aerial delivery and infrastructure inspection to environmental monitoring and disaster response. Ensuring the safety, reliability, and efficiency of these systems is paramount as they transition from research prototypes to mission-critical platforms. This paper presents a step-by-step guide to establishing a robust autonomous drone testing pipeline, covering each critical stage: Software-in-the-Loop (SIL) Simulation Testing, Hardware-in-the-Loop (HIL) Testing, Controlled Real-World Testing, and In-Field Testing. Using practical examples, including the marker-based autonomous landing system, we demonstrate how to systematically verify drone system behaviors, identify integration issues, and optimize performance. Furthermore, we highlight emerging trends shaping the future of drone testing, including the integration of Neurosymbolic and LLMs, creating co-simulation environments, and Digital Twin-enabled simulation-based testing techniques. By following this pipeline, developers and researchers can achieve comprehensive validation, minimize deployment risks, and prepare autonomous drones for safe and reliable real-world operations.
Towards Robust Autonomous Landing Systems: Iterative Solutions and Key Lessons Learned
May 18, 2025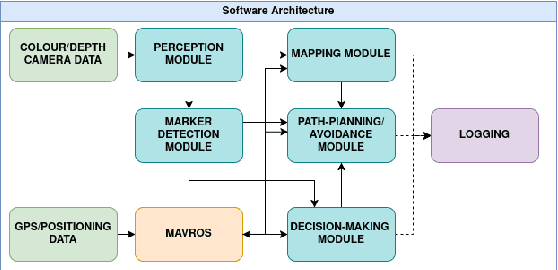
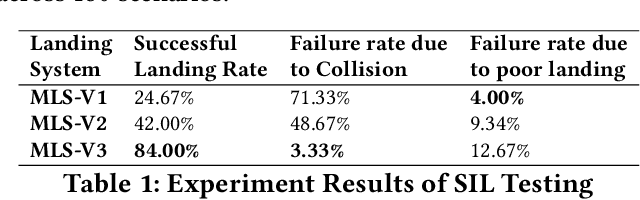
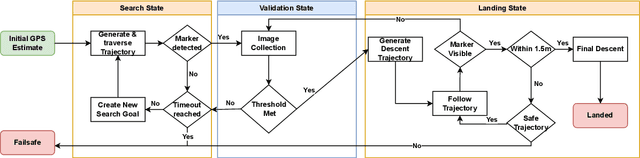

Uncrewed Aerial Vehicles (UAVs) have become a focal point of research, with both established companies and startups investing heavily in their development. This paper presents our iterative process in developing a robust autonomous marker-based landing system, highlighting the key challenges encountered and the solutions implemented. It reviews existing systems for autonomous landing processes, and through this aims to contribute to the community by sharing insights and challenges faced during development and testing.
NeuroStrata: Harnessing Neurosymbolic Paradigms for Improved Design, Testability, and Verifiability of Autonomous CPS
Feb 17, 2025


Autonomous cyber-physical systems (CPSs) leverage AI for perception, planning, and control but face trust and safety certification challenges due to inherent uncertainties. The neurosymbolic paradigm replaces stochastic layers with interpretable symbolic AI, enabling determinism. While promising, challenges like multisensor fusion, adaptability, and verification remain. This paper introduces NeuroStrata, a neurosymbolic framework to enhance the testing and verification of autonomous CPS. We outline its key components, present early results, and detail future plans.
MARL-OT: Multi-Agent Reinforcement Learning Guided Online Fuzzing to Detect Safety Violation in Autonomous Driving Systems
Jan 24, 2025



Autonomous Driving Systems (ADSs) are safety-critical, as real-world safety violations can result in significant losses. Rigorous testing is essential before deployment, with simulation testing playing a key role. However, ADSs are typically complex, consisting of multiple modules such as perception and planning, or well-trained end-to-end autonomous driving systems. Offline methods, such as the Genetic Algorithm (GA), can only generate predefined trajectories for dynamics, which struggle to cause safety violations for ADSs rapidly and efficiently in different scenarios due to their evolutionary nature. Online methods, such as single-agent reinforcement learning (RL), can quickly adjust the dynamics' trajectory online to adapt to different scenarios, but they struggle to capture complex corner cases of ADS arising from the intricate interplay among multiple vehicles. Multi-agent reinforcement learning (MARL) has a strong ability in cooperative tasks. On the other hand, it faces its own challenges, particularly with convergence. This paper introduces MARL-OT, a scalable framework that leverages MARL to detect safety violations of ADS resulting from surrounding vehicles' cooperation. MARL-OT employs MARL for high-level guidance, triggering various dangerous scenarios for the rule-based online fuzzer to explore potential safety violations of ADS, thereby generating dynamic, realistic safety violation scenarios. Our approach improves the detected safety violation rate by up to 136.2% compared to the state-of-the-art (SOTA) testing technique.
Towards Data Valuation via Asymmetric Data Shapley
Nov 01, 2024As data emerges as a vital driver of technological and economic advancements, a key challenge is accurately quantifying its value in algorithmic decision-making. The Shapley value, a well-established concept from cooperative game theory, has been widely adopted to assess the contribution of individual data sources in supervised machine learning. However, its symmetry axiom assumes all players in the cooperative game are homogeneous, which overlooks the complex structures and dependencies present in real-world datasets. To address this limitation, we extend the traditional data Shapley framework to asymmetric data Shapley, making it flexible enough to incorporate inherent structures within the datasets for structure-aware data valuation. We also introduce an efficient $k$-nearest neighbor-based algorithm for its exact computation. We demonstrate the practical applicability of our framework across various machine learning tasks and data market contexts. The code is available at: https://github.com/xzheng01/Asymmetric-Data-Shapley.
Probing the Robustness of Vision-Language Pretrained Models: A Multimodal Adversarial Attack Approach
Aug 24, 2024



Vision-language pretraining (VLP) with transformers has demonstrated exceptional performance across numerous multimodal tasks. However, the adversarial robustness of these models has not been thoroughly investigated. Existing multimodal attack methods have largely overlooked cross-modal interactions between visual and textual modalities, particularly in the context of cross-attention mechanisms. In this paper, we study the adversarial vulnerability of recent VLP transformers and design a novel Joint Multimodal Transformer Feature Attack (JMTFA) that concurrently introduces adversarial perturbations in both visual and textual modalities under white-box settings. JMTFA strategically targets attention relevance scores to disrupt important features within each modality, generating adversarial samples by fusing perturbations and leading to erroneous model predictions. Experimental results indicate that the proposed approach achieves high attack success rates on vision-language understanding and reasoning downstream tasks compared to existing baselines. Notably, our findings reveal that the textual modality significantly influences the complex fusion processes within VLP transformers. Moreover, we observe no apparent relationship between model size and adversarial robustness under our proposed attacks. These insights emphasize a new dimension of adversarial robustness and underscore potential risks in the reliable deployment of multimodal AI systems.