 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeGen-LLM: Enhancing Safety Generalization in Task Planning for Robotic Systems
Feb 27, 2026Safety-critical task planning in robotic systems remains challenging: classical planners suffer from poor scalability, Reinforcement Learning (RL)-based methods generalize poorly, and base Large Language Models (LLMs) cannot guarantee safety. To address this gap, we propose safety-generalizable large language models, named SafeGen-LLM. SafeGen-LLM can not only enhance the safety satisfaction of task plans but also generalize well to novel safety properties in various domains. We first construct a multi-domain Planning Domain Definition Language 3 (PDDL3) benchmark with explicit safety constraints. Then, we introduce a two-stage post-training framework: Supervised Fine-Tuning (SFT) on a constraint-compliant planning dataset to learn planning syntax and semantics, and Group Relative Policy Optimization (GRPO) guided by fine-grained reward machines derived from formal verification to enforce safety alignment and by curriculum learning to better handle complex tasks. Extensive experiments show that SafeGen-LLM achieves strong safety generalization and outperforms frontier proprietary baselines across multi-domain planning tasks and multiple input formats (e.g., PDDLs and natural language).
Safety Monitoring for Learning-Enabled Cyber-Physical Systems in Out-of-Distribution Scenarios
Apr 18, 2025The safety of learning-enabled cyber-physical systems is compromised by the well-known vulnerabilities of deep neural networks to out-of-distribution (OOD) inputs. Existing literature has sought to monitor the safety of such systems by detecting OOD data. However, such approaches have limited utility, as the presence of an OOD input does not necessarily imply the violation of a desired safety property. We instead propose to directly monitor safety in a manner that is itself robust to OOD data. To this end, we predict violations of signal temporal logic safety specifications based on predicted future trajectories. Our safety monitor additionally uses a novel combination of adaptive conformal prediction and incremental learning. The former obtains probabilistic prediction guarantees even on OOD data, and the latter prevents overly conservative predictions. We evaluate the efficacy of the proposed approach in two case studies on safety monitoring: 1) predicting collisions of an F1Tenth car with static obstacles, and 2) predicting collisions of a race car with multiple dynamic obstacles. We find that adaptive conformal prediction obtains theoretical guarantees where other uncertainty quantification methods fail to do so. Additionally, combining adaptive conformal prediction and incremental learning for safety monitoring achieves high recall and timeliness while reducing loss in precision. We achieve these results even in OOD settings and outperform alternative methods.
AR-Pro: Counterfactual Explanations for Anomaly Repair with Formal Properties
Oct 31, 2024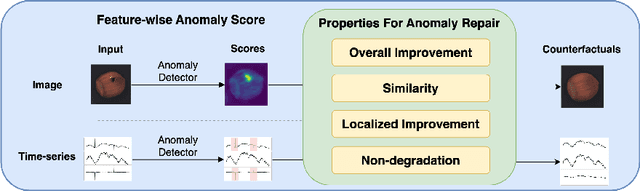
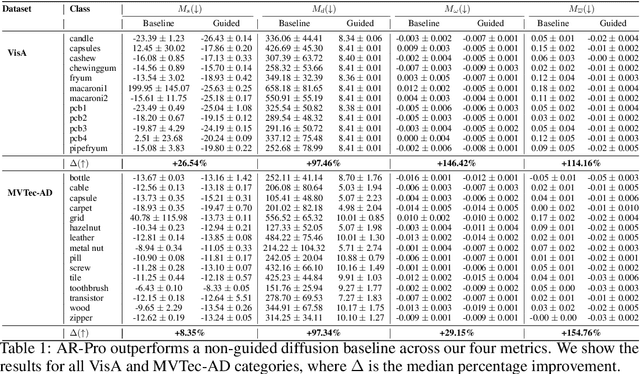
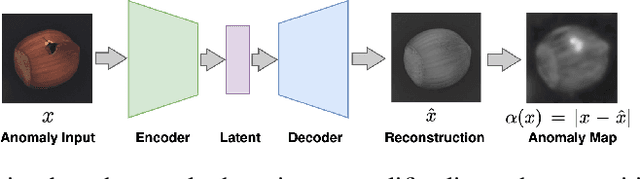
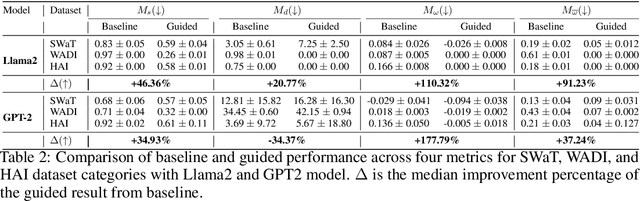
Anomaly detection is widely used for identifying critical errors and suspicious behaviors, but current methods lack interpretability. We leverage common properties of existing methods and recent advances in generative models to introduce counterfactual explanations for anomaly detection. Given an input, we generate its counterfactual as a diffusion-based repair that shows what a non-anomalous version should have looked like. A key advantage of this approach is that it enables a domain-independent formal specification of explainability desiderata, offering a unified framework for generating and evaluating explanations. We demonstrate the effectiveness of our anomaly explainability framework, AR-Pro, on vision (MVTec, VisA) and time-series (SWaT, WADI, HAI) anomaly datasets. The code used for the experiments is accessible at: https://github.com/xjiae/arpro.
Automating Weak Label Generation for Data Programming with Clinicians in the Loop
Jul 10, 2024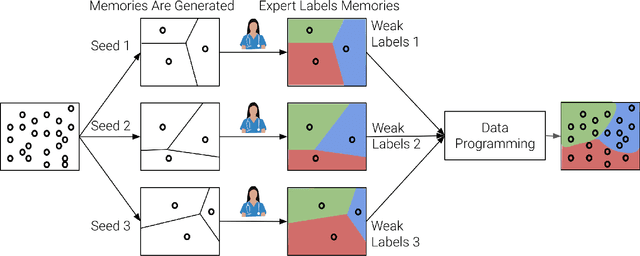
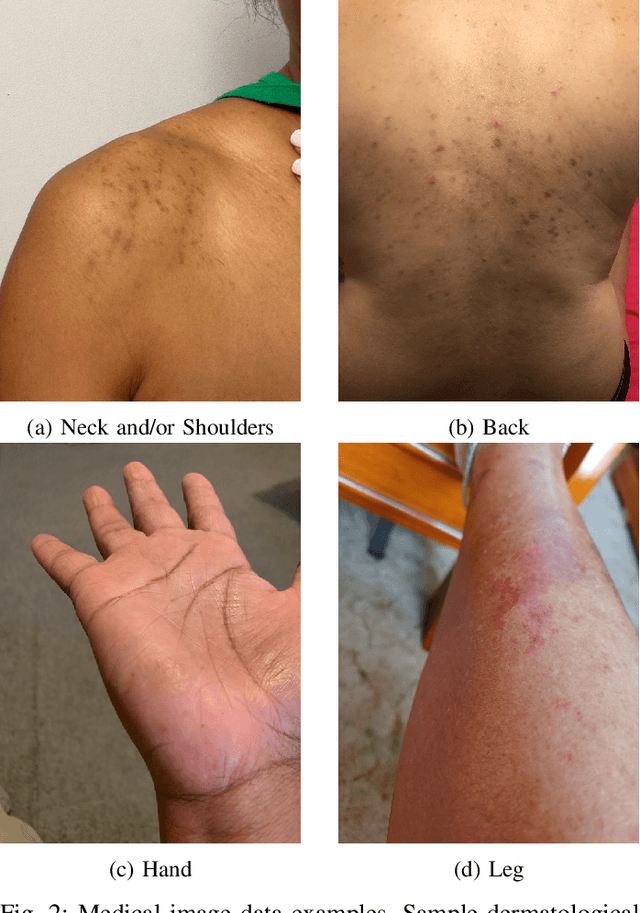
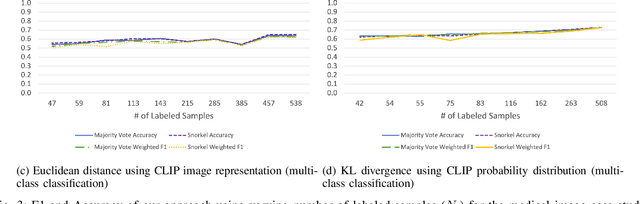
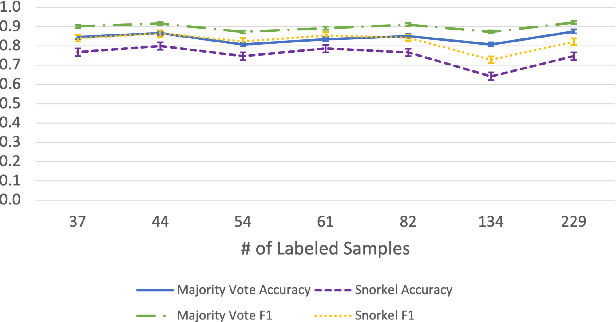
Large Deep Neural Networks (DNNs) are often data hungry and need high-quality labeled data in copious amounts for learning to converge. This is a challenge in the field of medicine since high quality labeled data is often scarce. Data programming has been the ray of hope in this regard, since it allows us to label unlabeled data using multiple weak labeling functions. Such functions are often supplied by a domain expert. Data-programming can combine multiple weak labeling functions and suggest labels better than simple majority voting over the different functions. However, it is not straightforward to express such weak labeling functions, especially in high-dimensional settings such as images and time-series data. What we propose in this paper is a way to bypass this issue, using distance functions. In high-dimensional spaces, it is easier to find meaningful distance metrics which can generalize across different labeling tasks. We propose an algorithm that queries an expert for labels of a few representative samples of the dataset. These samples are carefully chosen by the algorithm to capture the distribution of the dataset. The labels assigned by the expert on the representative subset induce a labeling on the full dataset, thereby generating weak labels to be used in the data programming pipeline. In our medical time series case study, labeling a subset of 50 to 130 out of 3,265 samples showed 17-28% improvement in accuracy and 13-28% improvement in F1 over the baseline using clinician-defined labeling functions. In our medical image case study, labeling a subset of about 50 to 120 images from 6,293 unlabeled medical images using our approach showed significant improvement over the baseline method, Snuba, with an increase of approximately 5-15% in accuracy and 12-19% in F1 score.
Testing learning-enabled cyber-physical systems with Large-Language Models: A Formal Approach
Nov 13, 2023The integration of machine learning (ML) into cyber-physical systems (CPS) offers significant benefits, including enhanced efficiency, predictive capabilities, real-time responsiveness, and the enabling of autonomous operations. This convergence has accelerated the development and deployment of a range of real-world applications, such as autonomous vehicles, delivery drones, service robots, and telemedicine procedures. However, the software development life cycle (SDLC) for AI-infused CPS diverges significantly from traditional approaches, featuring data and learning as two critical components. Existing verification and validation techniques are often inadequate for these new paradigms. In this study, we pinpoint the main challenges in ensuring formal safety for learningenabled CPS.We begin by examining testing as the most pragmatic method for verification and validation, summarizing the current state-of-the-art methodologies. Recognizing the limitations in current testing approaches to provide formal safety guarantees, we propose a roadmap to transition from foundational probabilistic testing to a more rigorous approach capable of delivering formal assurance.
Distributionally Robust Statistical Verification with Imprecise Neural Networks
Aug 30, 2023



A particularly challenging problem in AI safety is providing guarantees on the behavior of high-dimensional autonomous systems. Verification approaches centered around reachability analysis fail to scale, and purely statistical approaches are constrained by the distributional assumptions about the sampling process. Instead, we pose a distributionally robust version of the statistical verification problem for black-box systems, where our performance guarantees hold over a large family of distributions. This paper proposes a novel approach based on a combination of active learning, uncertainty quantification, and neural network verification. A central piece of our approach is an ensemble technique called Imprecise Neural Networks, which provides the uncertainty to guide active learning. The active learning uses an exhaustive neural-network verification tool Sherlock to collect samples. An evaluation on multiple physical simulators in the openAI gym Mujoco environments with reinforcement-learned controllers demonstrates that our approach can provide useful and scalable guarantees for high-dimensional systems.
Causal Repair of Learning-enabled Cyber-physical Systems
Apr 26, 2023Models of actual causality leverage domain knowledge to generate convincing diagnoses of events that caused an outcome. It is promising to apply these models to diagnose and repair run-time property violations in cyber-physical systems (CPS) with learning-enabled components (LEC). However, given the high diversity and complexity of LECs, it is challenging to encode domain knowledge (e.g., the CPS dynamics) in a scalable actual causality model that could generate useful repair suggestions. In this paper, we focus causal diagnosis on the input/output behaviors of LECs. Specifically, we aim to identify which subset of I/O behaviors of the LEC is an actual cause for a property violation. An important by-product is a counterfactual version of the LEC that repairs the run-time property by fixing the identified problematic behaviors. Based on this insights, we design a two-step diagnostic pipeline: (1) construct and Halpern-Pearl causality model that reflects the dependency of property outcome on the component's I/O behaviors, and (2) perform a search for an actual cause and corresponding repair on the model. We prove that our pipeline has the following guarantee: if an actual cause is found, the system is guaranteed to be repaired; otherwise, we have high probabilistic confidence that the LEC under analysis did not cause the property violation. We demonstrate that our approach successfully repairs learned controllers on a standard OpenAI Gym benchmark.
Fulfilling Formal Specifications ASAP by Model-free Reinforcement Learning
Apr 25, 2023
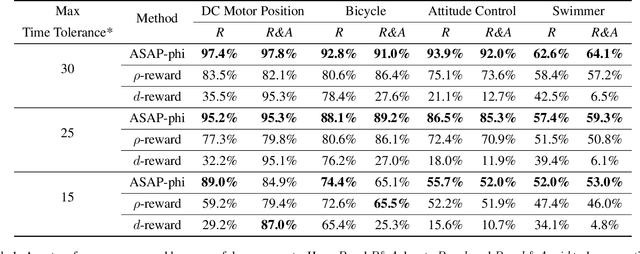
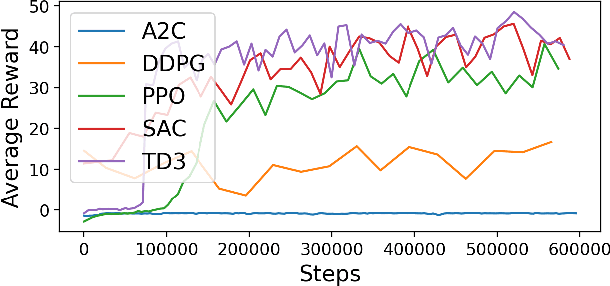
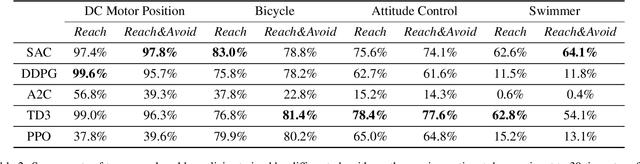
We propose a model-free reinforcement learning solution, namely the ASAP-Phi framework, to encourage an agent to fulfill a formal specification ASAP. The framework leverages a piece-wise reward function that assigns quantitative semantic reward to traces not satisfying the specification, and a high constant reward to the remaining. Then, it trains an agent with an actor-critic-based algorithm, such as soft actor-critic (SAC), or deep deterministic policy gradient (DDPG). Moreover, we prove that ASAP-Phi produces policies that prioritize fulfilling a specification ASAP. Extensive experiments are run, including ablation studies, on state-of-the-art benchmarks. Results show that our framework succeeds in finding sufficiently fast trajectories for up to 97\% test cases and defeats baselines.
Take Me Home: Reversing Distribution Shifts using Reinforcement Learning
Feb 24, 2023



Deep neural networks have repeatedly been shown to be non-robust to the uncertainties of the real world. Even subtle adversarial attacks and naturally occurring distribution shifts wreak havoc on systems relying on deep neural networks. In response to this, current state-of-the-art techniques use data-augmentation to enrich the training distribution of the model and consequently improve robustness to natural distribution shifts. We propose an alternative approach that allows the system to recover from distribution shifts online. Specifically, our method applies a sequence of semantic-preserving transformations to bring the shifted data closer in distribution to the training set, as measured by the Wasserstein distance. We formulate the problem of sequence selection as an MDP, which we solve using reinforcement learning. To aid in our estimates of Wasserstein distance, we employ dimensionality reduction through orthonormal projection. We provide both theoretical and empirical evidence that orthonormal projection preserves characteristics of the data at the distributional level. Finally, we apply our distribution shift recovery approach to the ImageNet-C benchmark for distribution shifts, targeting shifts due to additive noise and image histogram modifications. We demonstrate an improvement in average accuracy up to 14.21% across a variety of state-of-the-art ImageNet classifiers.
Using Semantic Information for Defining and Detecting OOD Inputs
Feb 21, 2023



As machine learning models continue to achieve impressive performance across different tasks, the importance of effective anomaly detection for such models has increased as well. It is common knowledge that even well-trained models lose their ability to function effectively on out-of-distribution inputs. Thus, out-of-distribution (OOD) detection has received some attention recently. In the vast majority of cases, it uses the distribution estimated by the training dataset for OOD detection. We demonstrate that the current detectors inherit the biases in the training dataset, unfortunately. This is a serious impediment, and can potentially restrict the utility of the trained model. This can render the current OOD detectors impermeable to inputs lying outside the training distribution but with the same semantic information (e.g. training class labels). To remedy this situation, we begin by defining what should ideally be treated as an OOD, by connecting inputs with their semantic information content. We perform OOD detection on semantic information extracted from the training data of MNIST and COCO datasets and show that it not only reduces false alarms but also significantly improves the detection of OOD inputs with spurious features from the training data.