 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
REGENT: A Retrieval-Augmented Generalist Agent That Can Act In-Context in New Environments
Dec 06, 2024Building generalist agents that can rapidly adapt to new environments is a key challenge for deploying AI in the digital and real worlds. Is scaling current agent architectures the most effective way to build generalist agents? We propose a novel approach to pre-train relatively small policies on relatively small datasets and adapt them to unseen environments via in-context learning, without any finetuning. Our key idea is that retrieval offers a powerful bias for fast adaptation. Indeed, we demonstrate that even a simple retrieval-based 1-nearest neighbor agent offers a surprisingly strong baseline for today's state-of-the-art generalist agents. From this starting point, we construct a semi-parametric agent, REGENT, that trains a transformer-based policy on sequences of queries and retrieved neighbors. REGENT can generalize to unseen robotics and game-playing environments via retrieval augmentation and in-context learning, achieving this with up to 3x fewer parameters and up to an order-of-magnitude fewer pre-training datapoints, significantly outperforming today's state-of-the-art generalist agents. Website: https://kaustubhsridhar.github.io/regent-research
Automating Weak Label Generation for Data Programming with Clinicians in the Loop
Jul 10, 2024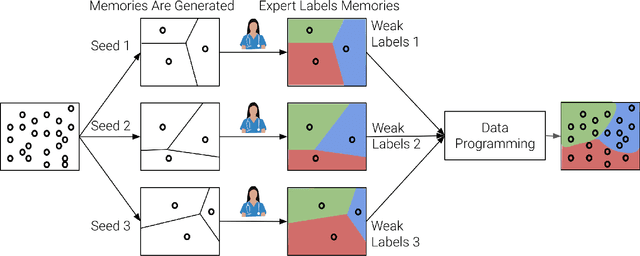
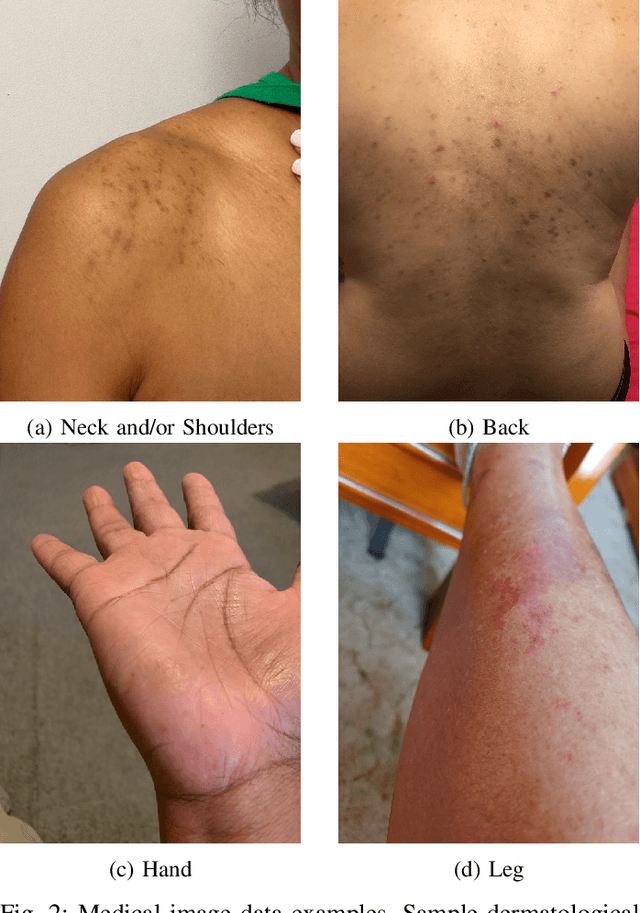
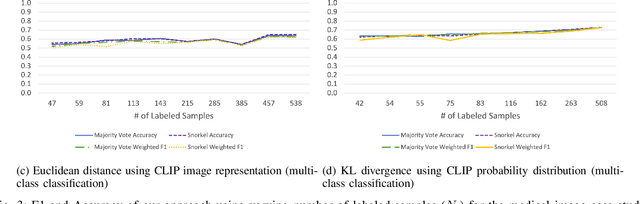
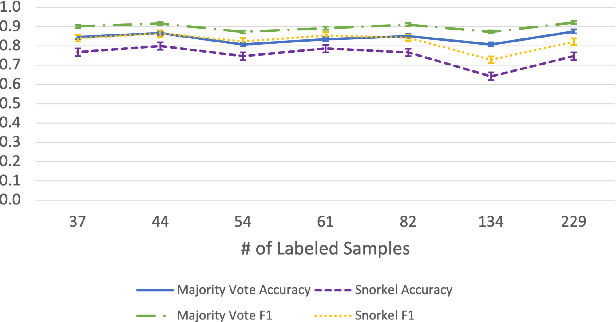
Large Deep Neural Networks (DNNs) are often data hungry and need high-quality labeled data in copious amounts for learning to converge. This is a challenge in the field of medicine since high quality labeled data is often scarce. Data programming has been the ray of hope in this regard, since it allows us to label unlabeled data using multiple weak labeling functions. Such functions are often supplied by a domain expert. Data-programming can combine multiple weak labeling functions and suggest labels better than simple majority voting over the different functions. However, it is not straightforward to express such weak labeling functions, especially in high-dimensional settings such as images and time-series data. What we propose in this paper is a way to bypass this issue, using distance functions. In high-dimensional spaces, it is easier to find meaningful distance metrics which can generalize across different labeling tasks. We propose an algorithm that queries an expert for labels of a few representative samples of the dataset. These samples are carefully chosen by the algorithm to capture the distribution of the dataset. The labels assigned by the expert on the representative subset induce a labeling on the full dataset, thereby generating weak labels to be used in the data programming pipeline. In our medical time series case study, labeling a subset of 50 to 130 out of 3,265 samples showed 17-28% improvement in accuracy and 13-28% improvement in F1 over the baseline using clinician-defined labeling functions. In our medical image case study, labeling a subset of about 50 to 120 images from 6,293 unlabeled medical images using our approach showed significant improvement over the baseline method, Snuba, with an increase of approximately 5-15% in accuracy and 12-19% in F1 score.
Memory-Consistent Neural Networks for Imitation Learning
Oct 09, 2023Imitation learning considerably simplifies policy synthesis compared to alternative approaches by exploiting access to expert demonstrations. For such imitation policies, errors away from the training samples are particularly critical. Even rare slip-ups in the policy action outputs can compound quickly over time, since they lead to unfamiliar future states where the policy is still more likely to err, eventually causing task failures. We revisit simple supervised ``behavior cloning'' for conveniently training the policy from nothing more than pre-recorded demonstrations, but carefully design the model class to counter the compounding error phenomenon. Our ``memory-consistent neural network'' (MCNN) outputs are hard-constrained to stay within clearly specified permissible regions anchored to prototypical ``memory'' training samples. We provide a guaranteed upper bound for the sub-optimality gap induced by MCNN policies. Using MCNNs on 9 imitation learning tasks, with MLP, Transformer, and Diffusion backbones, spanning dexterous robotic manipulation and driving, proprioceptive inputs and visual inputs, and varying sizes and types of demonstration data, we find large and consistent gains in performance, validating that MCNNs are better-suited than vanilla deep neural networks for imitation learning applications. Website: https://sites.google.com/view/mcnn-imitation
Guaranteed Conformance of Neurosymbolic Models to Natural Constraints
Dec 09, 2022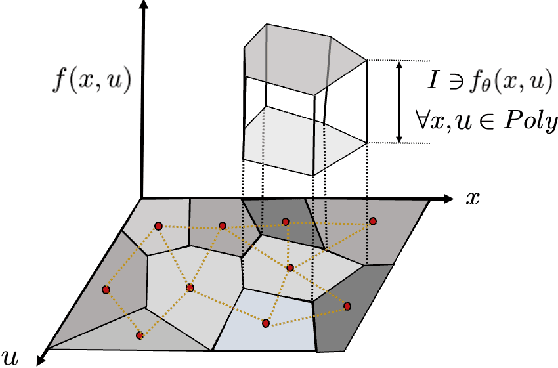
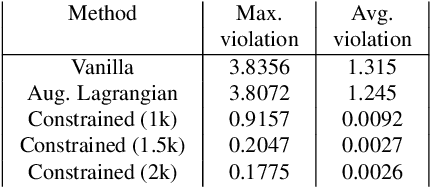
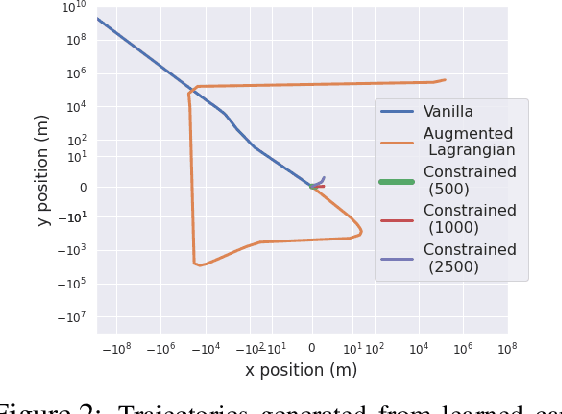
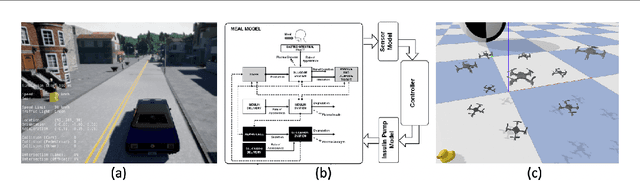
Deep neural networks have emerged as the workhorse for a large section of robotics and control applications, especially as models for dynamical systems. Such data-driven models are in turn used for designing and verifying autonomous systems. This is particularly useful in modeling medical systems where data can be leveraged to individualize treatment. In safety-critical applications, it is important that the data-driven model is conformant to established knowledge from the natural sciences. Such knowledge is often available or can often be distilled into a (possibly black-box) model $M$. For instance, the unicycle model for an F1 racing car. In this light, we consider the following problem - given a model $M$ and state transition dataset, we wish to best approximate the system model while being bounded distance away from $M$. We propose a method to guarantee this conformance. Our first step is to distill the dataset into few representative samples called memories, using the idea of a growing neural gas. Next, using these memories we partition the state space into disjoint subsets and compute bounds that should be respected by the neural network, when the input is drawn from a particular subset. This serves as a symbolic wrapper for guaranteed conformance. We argue theoretically that this only leads to bounded increase in approximation error; which can be controlled by increasing the number of memories. We experimentally show that on three case studies (Car Model, Drones, and Artificial Pancreas), our constrained neurosymbolic models conform to specified $M$ models (each encoding various constraints) with order-of-magnitude improvements compared to the augmented Lagrangian and vanilla training methods.
Predict-and-Critic: Accelerated End-to-End Predictive Control for Cloud Computing through Reinforcement Learning
Dec 02, 2022Cloud computing holds the promise of reduced costs through economies of scale. To realize this promise, cloud computing vendors typically solve sequential resource allocation problems, where customer workloads are packed on shared hardware. Virtual machines (VM) form the foundation of modern cloud computing as they help logically abstract user compute from shared physical infrastructure. Traditionally, VM packing problems are solved by predicting demand, followed by a Model Predictive Control (MPC) optimization over a future horizon. We introduce an approximate formulation of an industrial VM packing problem as an MILP with soft-constraints parameterized by the predictions. Recently, predict-and-optimize (PnO) was proposed for end-to-end training of prediction models by back-propagating the cost of decisions through the optimization problem. But, PnO is unable to scale to the large prediction horizons prevalent in cloud computing. To tackle this issue, we propose the Predict-and-Critic (PnC) framework that outperforms PnO with just a two-step horizon by leveraging reinforcement learning. PnC jointly trains a prediction model and a terminal Q function that approximates cost-to-go over a long horizon, by back-propagating the cost of decisions through the optimization problem \emph{and from the future}. The terminal Q function allows us to solve a much smaller two-step horizon optimization problem than the multi-step horizon necessary in PnO. We evaluate PnO and the PnC framework on two datasets, three workloads, and with disturbances not modeled in the optimization problem. We find that PnC significantly improves decision quality over PnO, even when the optimization problem is not a perfect representation of reality. We also find that hardening the soft constraints of the MILP and back-propagating through the constraints improves decision quality for both PnO and PnC.
CODiT: Conformal Out-of-Distribution Detection in Time-Series Data
Jul 24, 2022

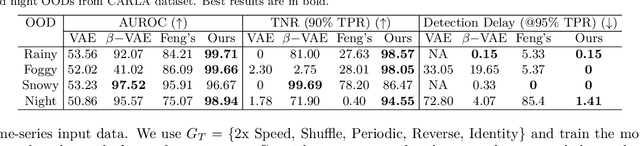
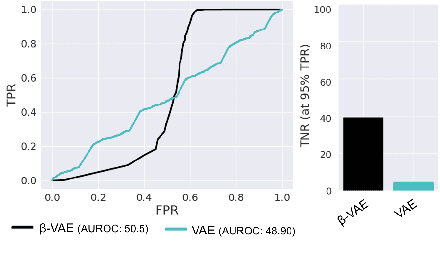
Machine learning models are prone to making incorrect predictions on inputs that are far from the training distribution. This hinders their deployment in safety-critical applications such as autonomous vehicles and healthcare. The detection of a shift from the training distribution of individual datapoints has gained attention. A number of techniques have been proposed for such out-of-distribution (OOD) detection. But in many applications, the inputs to a machine learning model form a temporal sequence. Existing techniques for OOD detection in time-series data either do not exploit temporal relationships in the sequence or do not provide any guarantees on detection. We propose using deviation from the in-distribution temporal equivariance as the non-conformity measure in conformal anomaly detection framework for OOD detection in time-series data.Computing independent predictions from multiple conformal detectors based on the proposed measure and combining these predictions by Fisher's method leads to the proposed detector CODiT with guarantees on false detection in time-series data. We illustrate the efficacy of CODiT by achieving state-of-the-art results on computer vision datasets in autonomous driving. We also show that CODiT can be used for OOD detection in non-vision datasets by performing experiments on the physiological GAIT sensory dataset. Code, data, and trained models are available at https://github.com/kaustubhsridhar/time-series-OOD.
Towards Alternative Techniques for Improving Adversarial Robustness: Analysis of Adversarial Training at a Spectrum of Perturbations
Jun 13, 2022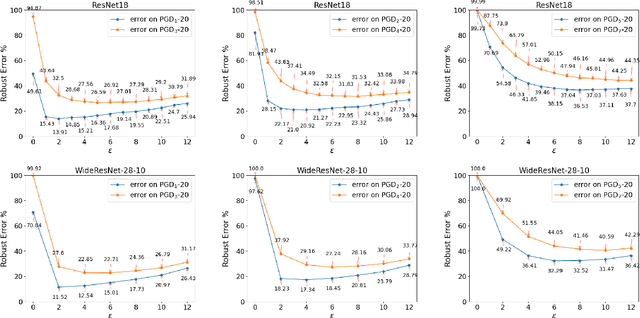
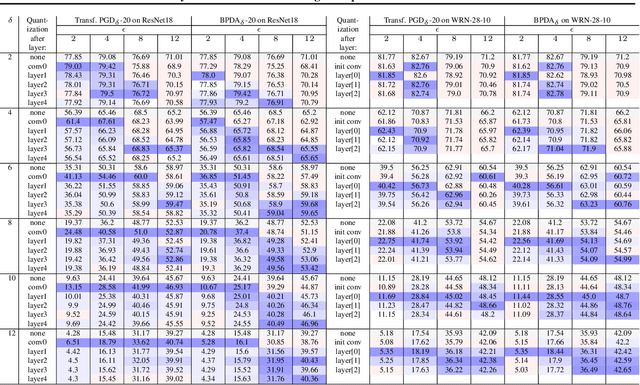
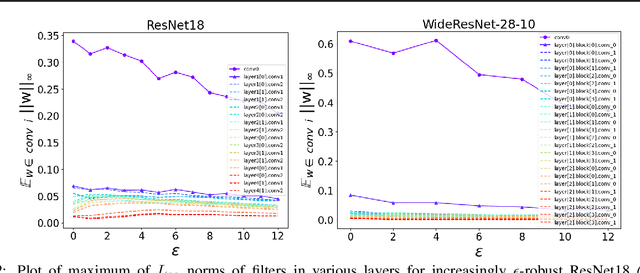
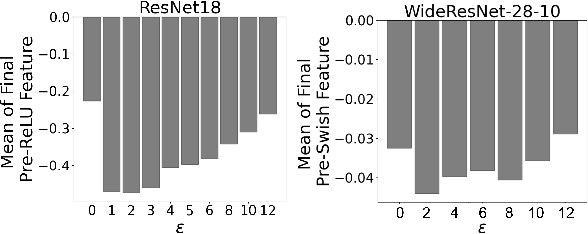
Adversarial training (AT) and its variants have spearheaded progress in improving neural network robustness to adversarial perturbations and common corruptions in the last few years. Algorithm design of AT and its variants are focused on training models at a specified perturbation strength $\epsilon$ and only using the feedback from the performance of that $\epsilon$-robust model to improve the algorithm. In this work, we focus on models, trained on a spectrum of $\epsilon$ values. We analyze three perspectives: model performance, intermediate feature precision and convolution filter sensitivity. In each, we identify alternative improvements to AT that otherwise wouldn't have been apparent at a single $\epsilon$. Specifically, we find that for a PGD attack at some strength $\delta$, there is an AT model at some slightly larger strength $\epsilon$, but no greater, that generalizes best to it. Hence, we propose overdesigning for robustness where we suggest training models at an $\epsilon$ just above $\delta$. Second, we observe (across various $\epsilon$ values) that robustness is highly sensitive to the precision of intermediate features and particularly those after the first and second layer. Thus, we propose adding a simple quantization to defenses that improves accuracy on seen and unseen adaptive attacks. Third, we analyze convolution filters of each layer of models at increasing $\epsilon$ and notice that those of the first and second layer may be solely responsible for amplifying input perturbations. We present our findings and demonstrate our techniques through experiments with ResNet and WideResNet models on the CIFAR-10 and CIFAR-10-C datasets.
Exploring with Sticky Mittens: Reinforcement Learning with Expert Interventions via Option Templates
Feb 25, 2022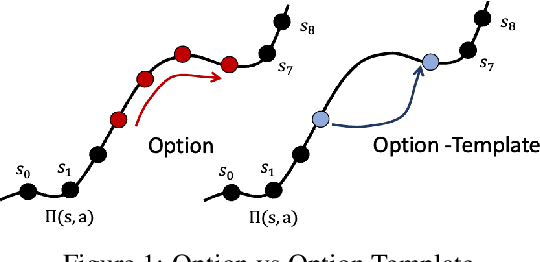
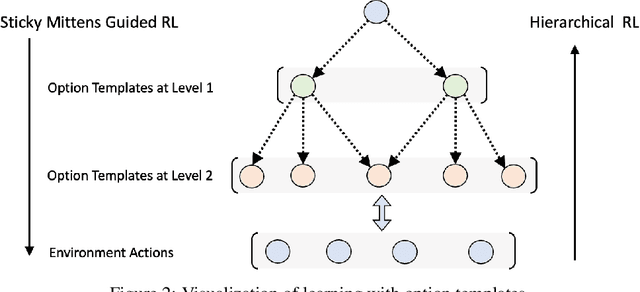
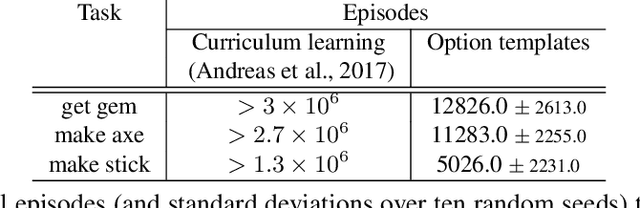
Environments with sparse rewards and long horizons pose a significant challenge for current reinforcement learning algorithms. A key feature enabling humans to learn challenging control tasks is that they often receive expert intervention that enables them to understand the high-level structure of the task before mastering low-level control actions. We propose a framework for leveraging expert intervention to solve long-horizon reinforcement learning tasks. We consider option templates, which are specifications encoding a potential option that can be trained using reinforcement learning. We formulate expert intervention as allowing the agent to execute option templates before learning an implementation. This enables them to use an option, before committing costly resources to learning it. We evaluate our approach on three challenging reinforcement learning problems, showing that it outperforms state of-the-art approaches by an order of magnitude. Project website at https://sites.google.com/view/stickymittens
Robust Learning via Persistency of Excitation
Jun 11, 2021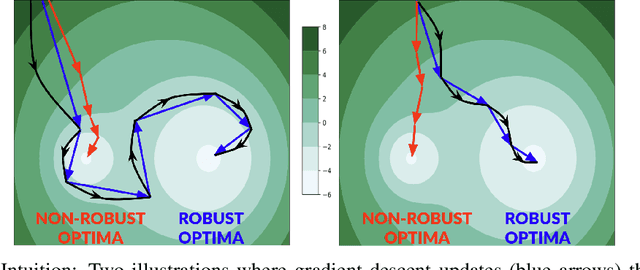
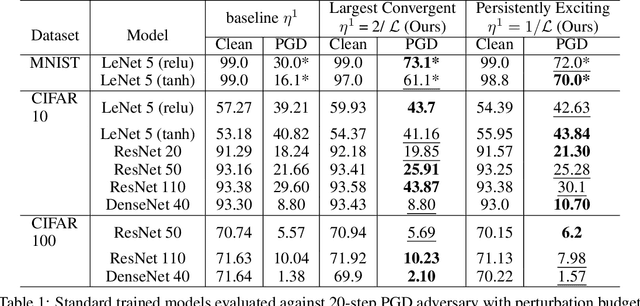
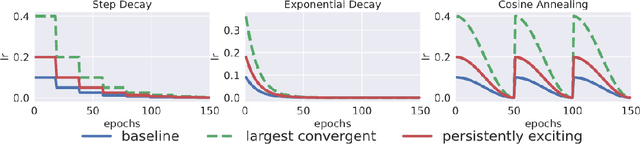
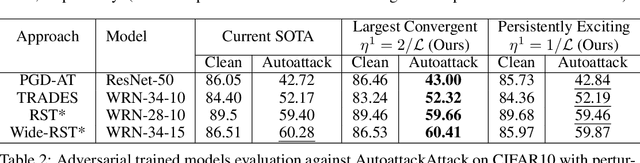
Improving adversarial robustness of neural networks remains a major challenge. Fundamentally, training a network is a parameter estimation problem. In adaptive control theory, maintaining persistency of excitation (PoE) is integral to ensuring convergence of parameter estimates in dynamical systems to their robust optima. In this work, we show that network training using gradient descent is equivalent to a dynamical system parameter estimation problem. Leveraging this relationship, we prove a sufficient condition for PoE of gradient descent is achieved when the learning rate is less than the inverse of the Lipschitz constant of the gradient of loss function. We provide an efficient technique for estimating the corresponding Lipschitz constant using extreme value theory and demonstrate that by only scaling the learning rate schedule we can increase adversarial accuracy by up to 15% points on benchmark datasets. Our approach also universally increases the adversarial accuracy by 0.1% to 0.3% points in various state-of-the-art adversarially trained models on the AutoAttack benchmark, where every small margin of improvement is significant.