 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Conformal Prediction with Adversarial Semi-bandit Feedback via Regret Minimization
Apr 20, 2026Uncertainty quantification is crucial in safety-critical systems, where decisions must be made under uncertainty. In particular, we consider the problem of online uncertainty quantification, where data points arrive sequentially. Online conformal prediction is a principled online uncertainty quantification method that dynamically constructs a prediction set at each time step. While existing methods for online conformal prediction provide long-run coverage guarantees without any distributional assumptions, they typically assume a full feedback setting in which the true label is always observed. In this paper, we propose a novel learning method for online conformal prediction with partial feedback from an adaptive adversary-a more challenging setup where the true label is revealed only when it lies inside the constructed prediction set. Specifically, we formulate online conformal prediction as an adversarial bandit problem by treating each candidate prediction set as an arm. Building on an existing algorithm for adversarial bandits, our method achieves a long-run coverage guarantee by explicitly establishing its connection to the regret of the learner. Finally, we empirically demonstrate the effectiveness of our method in both independent and identically distributed (i.i.d.) and non-i.i.d. settings, showing that it successfully controls the miscoverage rate while maintaining a reasonable size of the prediction set.
Transductive Generalization via Optimal Transport and Its Application to Graph Node Classification
Mar 10, 2026Many existing transductive bounds rely on classical complexity measures that are computationally intractable and often misaligned with empirical behavior. In this work, we establish new representation-based generalization bounds in a distribution-free transductive setting, where learned representations are dependent, and test features are accessible during training. We derive global and class-wise bounds via optimal transport, expressed in terms of Wasserstein distances between encoded feature distributions. We demonstrate that our bounds are efficiently computable and strongly correlate with empirical generalization in graph node classification, improving upon classical complexity measures. Additionally, our analysis reveals how the GNN aggregation process transforms the representation distributions, inducing a trade-off between intra-class concentration and inter-class separation. This yields depth-dependent characterizations that capture the non-monotonic relationship between depth and generalization error observed in practice. The code is available at https://github.com/ml-postech/Transductive-OT-Gen-Bound.
ATLANTIS: AI-driven Threat Localization, Analysis, and Triage Intelligence System
Sep 18, 2025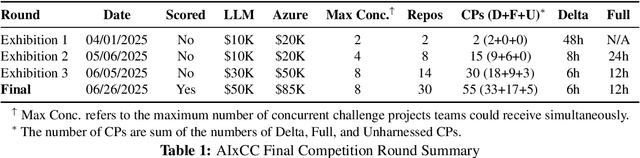
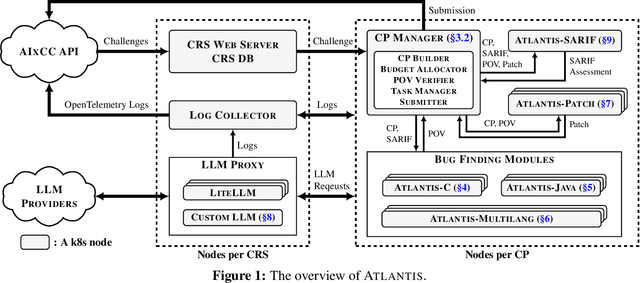
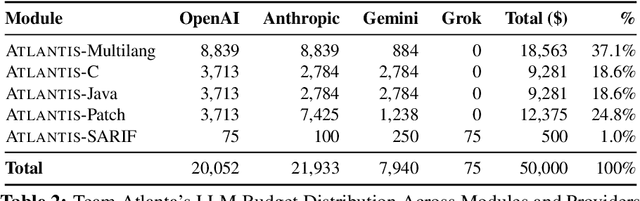
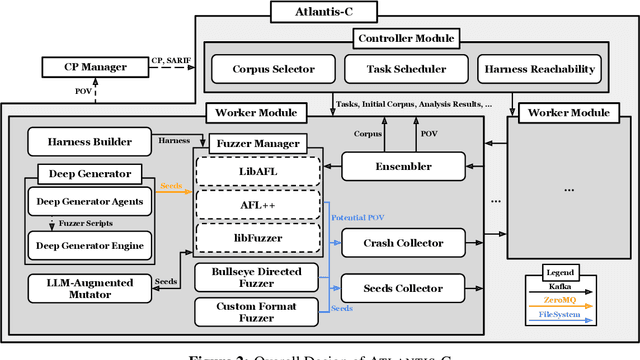
We present ATLANTIS, the cyber reasoning system developed by Team Atlanta that won 1st place in the Final Competition of DARPA's AI Cyber Challenge (AIxCC) at DEF CON 33 (August 2025). AIxCC (2023-2025) challenged teams to build autonomous cyber reasoning systems capable of discovering and patching vulnerabilities at the speed and scale of modern software. ATLANTIS integrates large language models (LLMs) with program analysis -- combining symbolic execution, directed fuzzing, and static analysis -- to address limitations in automated vulnerability discovery and program repair. Developed by researchers at Georgia Institute of Technology, Samsung Research, KAIST, and POSTECH, the system addresses core challenges: scaling across diverse codebases from C to Java, achieving high precision while maintaining broad coverage, and producing semantically correct patches that preserve intended behavior. We detail the design philosophy, architectural decisions, and implementation strategies behind ATLANTIS, share lessons learned from pushing the boundaries of automated security when program analysis meets modern AI, and release artifacts to support reproducibility and future research.
State-Inference-Based Prompting for Natural Language Trading with Game NPCs
Jul 09, 2025Large Language Models enable dynamic game interactions but struggle with rule-governed trading systems. Current implementations suffer from rule violations, such as item hallucinations and calculation errors, that erode player trust. Here, State-Inference-Based Prompting (SIBP) enables reliable trading through autonomous dialogue state inference and context-specific rule adherence. The approach decomposes trading into six states within a unified prompt framework, implementing context-aware item referencing and placeholder-based price calculations. Evaluation across 100 trading dialogues demonstrates >97% state compliance, >95% referencing accuracy, and 99.7% calculation precision. SIBP maintains computational efficiency while outperforming baseline approaches, establishing a practical foundation for trustworthy NPC interactions in commercial games.
Unlearn to Relearn Backdoors: Deferred Backdoor Functionality Attacks on Deep Learning Models
Nov 25, 2024



Deep learning models are vulnerable to backdoor attacks, where adversaries inject malicious functionality during training that activates on trigger inputs at inference time. Extensive research has focused on developing stealthy backdoor attacks to evade detection and defense mechanisms. However, these approaches still have limitations that leave the door open for detection and mitigation due to their inherent design to cause malicious behavior in the presence of a trigger. To address this limitation, we introduce Deferred Activated Backdoor Functionality (DABF), a new paradigm in backdoor attacks. Unlike conventional attacks, DABF initially conceals its backdoor, producing benign outputs even when triggered. This stealthy behavior allows DABF to bypass multiple detection and defense methods, remaining undetected during initial inspections. The backdoor functionality is strategically activated only after the model undergoes subsequent updates, such as retraining on benign data. DABF attacks exploit the common practice in the life cycle of machine learning models to perform model updates and fine-tuning after initial deployment. To implement DABF attacks, we approach the problem by making the unlearning of the backdoor fragile, allowing it to be easily cancelled and subsequently reactivate the backdoor functionality. To achieve this, we propose a novel two-stage training scheme, called DeferBad. Our extensive experiments across various fine-tuning scenarios, backdoor attack types, datasets, and model architectures demonstrate the effectiveness and stealthiness of DeferBad.
Retrieval-Augmented Generation with Estimation of Source Reliability
Oct 30, 2024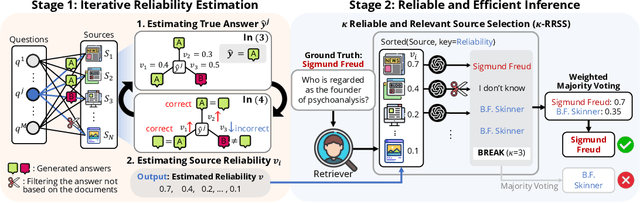
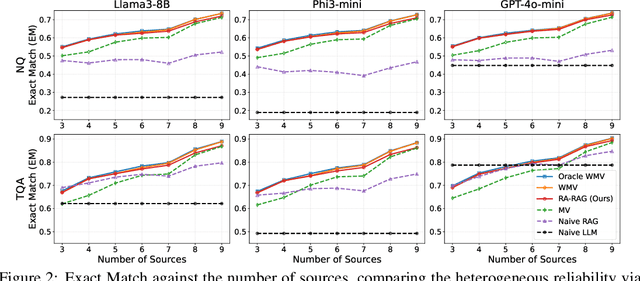

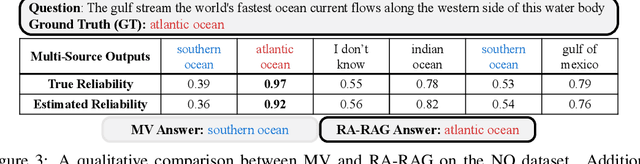
Retrieval-augmented generation (RAG) addresses key limitations of large language models (LLMs), such as hallucinations and outdated knowledge, by incorporating external databases. These databases typically consult multiple sources to encompass up-to-date and various information. However, standard RAG methods often overlook the heterogeneous source reliability in the multi-source database and retrieve documents solely based on relevance, making them prone to propagating misinformation. To address this, we propose Reliability-Aware RAG (RA-RAG) which estimates the reliability of multiple sources and incorporates this information into both retrieval and aggregation processes. Specifically, it iteratively estimates source reliability and true answers for a set of queries with no labelling. Then, it selectively retrieves relevant documents from a few of reliable sources and aggregates them using weighted majority voting, where the selective retrieval ensures scalability while not compromising the performance. We also introduce a benchmark designed to reflect real-world scenarios with heterogeneous source reliability and demonstrate the effectiveness of RA-RAG compared to a set of baselines.
Holistic Unlearning Benchmark: A Multi-Faceted Evaluation for Text-to-Image Diffusion Model Unlearning
Oct 08, 2024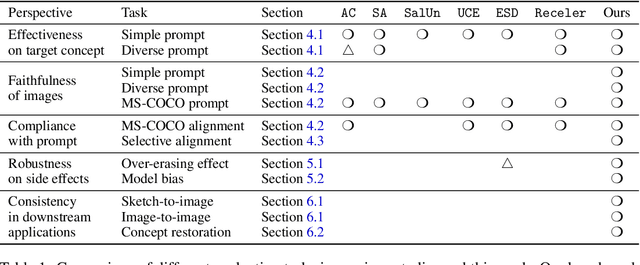

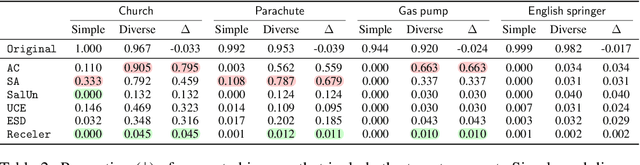
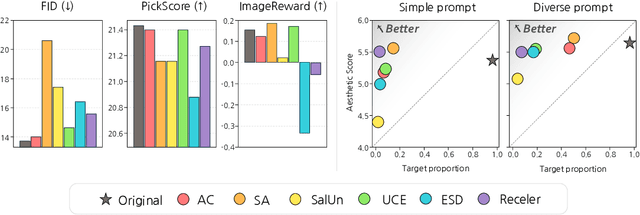
As text-to-image diffusion models become advanced enough for commercial applications, there is also increasing concern about their potential for malicious and harmful use. Model unlearning has been proposed to mitigate the concerns by removing undesired and potentially harmful information from the pre-trained model. So far, the success of unlearning is mainly measured by whether the unlearned model can generate a target concept while maintaining image quality. However, unlearning is typically tested under limited scenarios, and the side effects of unlearning have barely been studied in the current literature. In this work, we thoroughly analyze unlearning under various scenarios with five key aspects. Our investigation reveals that every method has side effects or limitations, especially in more complex and realistic situations. By releasing our comprehensive evaluation framework with the source codes and artifacts, we hope to inspire further research in this area, leading to more reliable and effective unlearning methods.
Uncertainty Quantification for Neurosymbolic Programs via Compositional Conformal Prediction
May 24, 2024Machine learning has become an effective tool for automatically annotating unstructured data (e.g., images) with structured labels (e.g., object detections). As a result, a new programming paradigm called neurosymbolic programming has emerged where users write queries against these predicted annotations. However, due to the intrinsic fallibility of machine learning models, these programs currently lack any notion of correctness. In many domains, users may want some kind of conservative guarantee that the results of their queries contain all possibly relevant instances. Conformal prediction has emerged as a promising strategy for quantifying uncertainty in machine learning by modifying models to predict sets of labels instead of individual labels; it provides a probabilistic guarantee that the prediction set contains the true label with high probability. We propose a novel framework for adapting conformal prediction to neurosymbolic programs; our strategy is to represent prediction sets as abstract values in some abstract domain, and then to use abstract interpretation to propagate prediction sets through the program. Our strategy satisfies three key desiderata: (i) correctness (i.e., the program outputs a prediction set that contains the true output with high probability), (ii) compositionality (i.e., we can quantify uncertainty separately for different modules and then compose them together), and (iii) structured values (i.e., we can provide uncertainty quantification for structured values such as lists). When the full program is available ahead-of-time, we propose an optimization that incorporates conformal prediction at intermediate program points to reduce imprecision in abstract interpretation. We evaluate our approach on programs that take MNIST and MS-COCO images as input, demonstrating that it produces reasonably sized prediction sets while satisfying a coverage guarantee.
MedBN: Robust Test-Time Adaptation against Malicious Test Samples
Mar 28, 2024

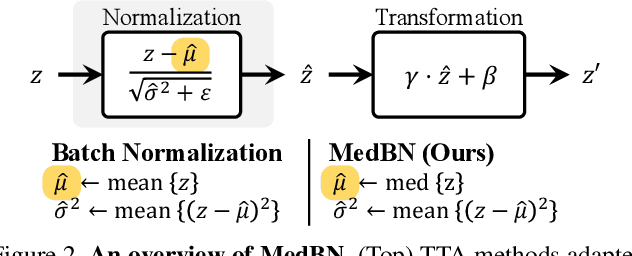

Test-time adaptation (TTA) has emerged as a promising solution to address performance decay due to unforeseen distribution shifts between training and test data. While recent TTA methods excel in adapting to test data variations, such adaptability exposes a model to vulnerability against malicious examples, an aspect that has received limited attention. Previous studies have uncovered security vulnerabilities within TTA even when a small proportion of the test batch is maliciously manipulated. In response to the emerging threat, we propose median batch normalization (MedBN), leveraging the robustness of the median for statistics estimation within the batch normalization layer during test-time inference. Our method is algorithm-agnostic, thus allowing seamless integration with existing TTA frameworks. Our experimental results on benchmark datasets, including CIFAR10-C, CIFAR100-C and ImageNet-C, consistently demonstrate that MedBN outperforms existing approaches in maintaining robust performance across different attack scenarios, encompassing both instant and cumulative attacks. Through extensive experiments, we show that our approach sustains the performance even in the absence of attacks, achieving a practical balance between robustness and performance.
PAC Prediction Sets Under Label Shift
Oct 19, 2023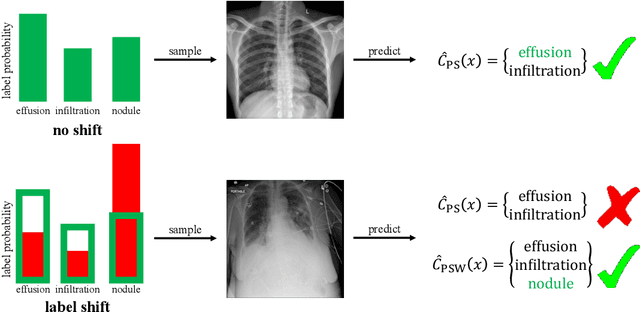
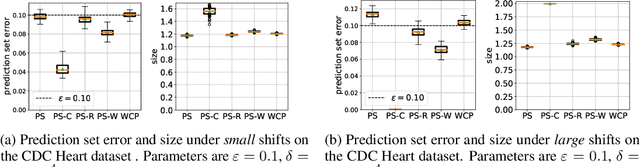
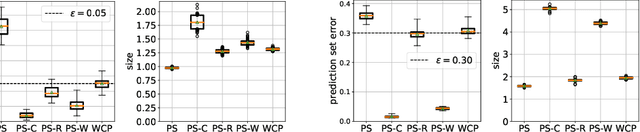
Prediction sets capture uncertainty by predicting sets of labels rather than individual labels, enabling downstream decisions to conservatively account for all plausible outcomes. Conformal inference algorithms construct prediction sets guaranteed to contain the true label with high probability. These guarantees fail to hold in the face of distribution shift, which is precisely when reliable uncertainty quantification can be most useful. We propose a novel algorithm for constructing prediction sets with PAC guarantees in the label shift setting. This method estimates the predicted probabilities of the classes in a target domain, as well as the confusion matrix, then propagates uncertainty in these estimates through a Gaussian elimination algorithm to compute confidence intervals for importance weights. Finally, it uses these intervals to construct prediction sets. We evaluate our approach on five datasets: the CIFAR-10, ChestX-Ray and Entity-13 image datasets, the tabular CDC Heart dataset, and the AGNews text dataset. Our algorithm satisfies the PAC guarantee while producing smaller, more informative, prediction sets compared to several baselines.