 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Place Feedback: A New Paradigm for Guiding LLMs in Multi-Turn Reasoning
Oct 01, 2025Large language models (LLMs) are increasingly studied in the context of multi-turn reasoning, where models iteratively refine their outputs based on user-provided feedback. Such settings are crucial for tasks that require complex reasoning, yet existing feedback paradigms often rely on issuing new messages. LLMs struggle to integrate these reliably, leading to inconsistent improvements. In this work, we introduce in-place feedback, a novel interaction paradigm in which users directly edit an LLM's previous response, and the model conditions on this modified response to generate its revision. Empirical evaluations on diverse reasoning-intensive benchmarks reveal that in-place feedback achieves better performance than conventional multi-turn feedback while using $79.1\%$ fewer tokens. Complementary analyses on controlled environments further demonstrate that in-place feedback resolves a core limitation of multi-turn feedback: models often fail to apply feedback precisely to erroneous parts of the response, leaving errors uncorrected and sometimes introducing new mistakes into previously correct content. These findings suggest that in-place feedback offers a more natural and effective mechanism for guiding LLMs in reasoning-intensive tasks.
CoPL: Collaborative Preference Learning for Personalizing LLMs
Mar 03, 2025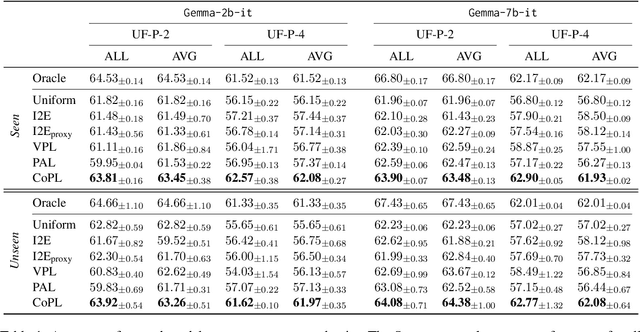


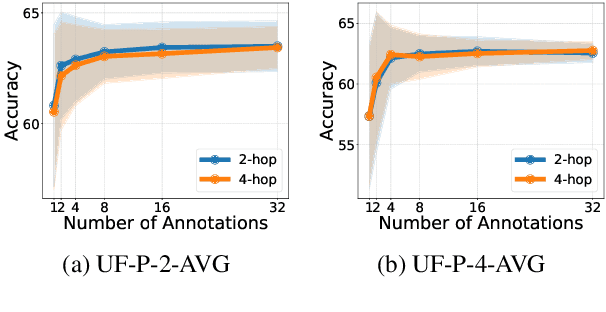
Personalizing large language models (LLMs) is important for aligning outputs with diverse user preferences, yet existing methods struggle with flexibility and generalization. We propose CoPL (Collaborative Preference Learning), a graph-based collaborative filtering framework that models user-response relationships to enhance preference estimation, particularly in sparse annotation settings. By integrating a mixture of LoRA experts, CoPL efficiently fine-tunes LLMs while dynamically balancing shared and user-specific preferences. Additionally, an optimization-free adaptation strategy enables generalization to unseen users without fine-tuning. Experiments on UltraFeedback-P demonstrate that CoPL outperforms existing personalized reward models, effectively capturing both common and controversial preferences, making it a scalable solution for personalized LLM alignment.
Holistic Unlearning Benchmark: A Multi-Faceted Evaluation for Text-to-Image Diffusion Model Unlearning
Oct 08, 2024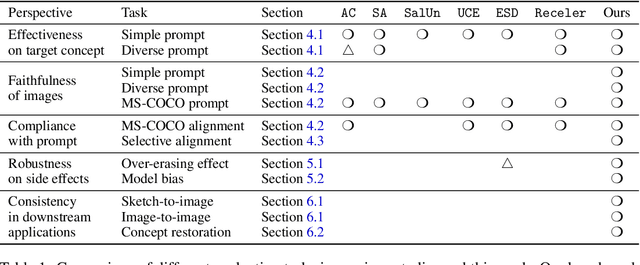

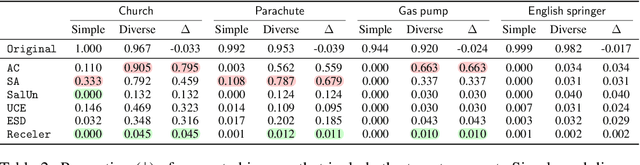
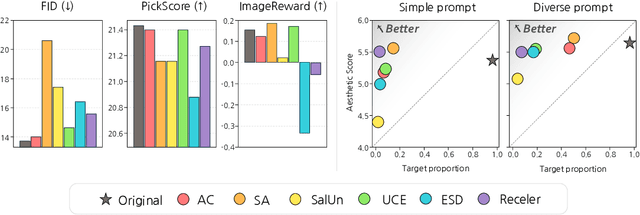
As text-to-image diffusion models become advanced enough for commercial applications, there is also increasing concern about their potential for malicious and harmful use. Model unlearning has been proposed to mitigate the concerns by removing undesired and potentially harmful information from the pre-trained model. So far, the success of unlearning is mainly measured by whether the unlearned model can generate a target concept while maintaining image quality. However, unlearning is typically tested under limited scenarios, and the side effects of unlearning have barely been studied in the current literature. In this work, we thoroughly analyze unlearning under various scenarios with five key aspects. Our investigation reveals that every method has side effects or limitations, especially in more complex and realistic situations. By releasing our comprehensive evaluation framework with the source codes and artifacts, we hope to inspire further research in this area, leading to more reliable and effective unlearning methods.
Robust Evaluation of Diffusion-Based Adversarial Purification
Mar 16, 2023We question the current evaluation practice on diffusion-based purification methods. Diffusion-based purification methods aim to remove adversarial effects from an input data point at test time. The approach gains increasing attention as an alternative to adversarial training due to the disentangling between training and testing. Well-known white-box attacks are often employed to measure the robustness of the purification. However, it is unknown whether these attacks are the most effective for the diffusion-based purification since the attacks are often tailored for adversarial training. We analyze the current practices and provide a new guideline for measuring the robustness of purification methods against adversarial attacks. Based on our analysis, we further propose a new purification strategy showing competitive results against the state-of-the-art adversarial training approaches.