 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOS-ISP: Pipeline Optimization at the Sequence Level for Task-aware ISP
Apr 08, 2026Recent work has explored optimizing image signal processing (ISP) pipelines for various tasks by composing predefined modules and adapting them to task-specific objectives. However, jointly optimizing module sequences and parameters remains challenging. Existing approaches rely on neural architecture search (NAS) or step-wise reinforcement learning (RL), but NAS suffers from a training-inference mismatch, while step-wise RL leads to unstable training and high computational overhead due to stage-wise decision-making. We propose POS-ISP, a sequence-level RL framework that formulates modular ISP optimization as a global sequence prediction problem. Our method predicts the entire module sequence and its parameters in a single forward pass and optimizes the pipeline using a terminal task reward, eliminating the need for intermediate supervision and redundant executions. Experiments across multiple downstream tasks show that POS-ISP improves task performance while reducing computational cost, highlighting sequence-level optimization as a stable and efficient paradigm for task-aware ISP. The project page is available at https://w1jyun.github.io/POS-ISP
Visual Prompt Discovery via Semantic Exploration
Mar 17, 2026LVLMs encounter significant challenges in image understanding and visual reasoning, leading to critical perception failures. Visual prompts, which incorporate image manipulation code, have shown promising potential in mitigating these issues. While emerged as a promising direction, previous methods for visual prompt generation have focused on tool selection rather than diagnosing and mitigating the root causes of LVLM perception failures. Because of the opacity and unpredictability of LVLMs, optimal visual prompts must be discovered through empirical experiments, which have relied on manual human trial-and-error. We propose an automated semantic exploration framework for discovering task-wise visual prompts. Our approach enables diverse yet efficient exploration through agent-driven experiments, minimizing human intervention and avoiding the inefficiency of per-sample generation. We introduce a semantic exploration algorithm named SEVEX, which addresses two major challenges of visual prompt exploration: (1) the distraction caused by lengthy, low-level code and (2) the vast, unstructured search space of visual prompts. Specifically, our method leverages an abstract idea space as a search space, a novelty-guided selection algorithm, and a semantic feedback-driven ideation process to efficiently explore diverse visual prompts based on empirical results. We evaluate SEVEX on the BlindTest and BLINK benchmarks, which are designed to assess LVLM perception. Experimental results demonstrate that SEVEX significantly outperforms baseline methods in task accuracy, inference efficiency, exploration efficiency, and exploration stability. Notably, our framework discovers sophisticated and counter-intuitive visual strategies that go beyond conventional tool usage, offering a new paradigm for enhancing LVLM perception through automated, task-wise visual prompts.
ChimeraLoRA: Multi-Head LoRA-Guided Synthetic Datasets
Feb 23, 2026Beyond general recognition tasks, specialized domains including privacy-constrained medical applications and fine-grained settings often encounter data scarcity, especially for tail classes. To obtain less biased and more reliable models under such scarcity, practitioners leverage diffusion models to supplement underrepresented regions of real data. Specifically, recent studies fine-tune pretrained diffusion models with LoRA on few-shot real sets to synthesize additional images. While an image-wise LoRA trained on a single image captures fine-grained details yet offers limited diversity, a class-wise LoRA trained over all shots produces diverse images as it encodes class priors yet tends to overlook fine details. To combine both benefits, we separate the adapter into a class-shared LoRA~$A$ for class priors and per-image LoRAs~$\mathcal{B}$ for image-specific characteristics. To expose coherent class semantics in the shared LoRA~$A$, we propose a semantic boosting by preserving class bounding boxes during training. For generation, we compose $A$ with a mixture of $\mathcal{B}$ using coefficients drawn from a Dirichlet distribution. Across diverse datasets, our synthesized images are both diverse and detail-rich while closely aligning with the few-shot real distribution, yielding robust gains in downstream classification accuracy.
Rising Multi-Armed Bandits with Known Horizons
Feb 13, 2026The Rising Multi-Armed Bandit (RMAB) framework models environments where expected rewards of arms increase with plays, which models practical scenarios where performance of each option improves with the repeated usage, such as in robotics and hyperparameter tuning. For instance, in hyperparameter tuning, the validation accuracy of a model configuration (arm) typically increases with each training epoch. A defining characteristic of RMAB is em horizon-dependent optimality: unlike standard settings, the optimal strategy here shifts dramatically depending on the available budget $T$. This implies that knowledge of $T$ yields significantly greater utility in RMAB, empowering the learner to align its decision-making with this shifting optimality. However, the horizon-aware setting remains underexplored. To address this, we propose a novel CUmulative Reward Estimation UCB (CURE-UCB) that explicitly integrates the horizon. We provide a rigorous analysis establishing a new regret upper bound and prove that our method strictly outperforms horizon-agnostic strategies in structured environments like ``linear-then-flat'' instances. Extensive experiments demonstrate its significant superiority over baselines.
Making Models Unmergeable via Scaling-Sensitive Loss Landscape
Jan 29, 2026The rise of model hubs has made it easier to access reusable model components, making model merging a practical tool for combining capabilities. Yet, this modularity also creates a \emph{governance gap}: downstream users can recompose released weights into unauthorized mixtures that bypass safety alignment or licensing terms. Because existing defenses are largely post-hoc and architecture-specific, they provide inconsistent protection across diverse architectures and release formats in practice. To close this gap, we propose \textsc{Trap}$^{2}$, an architecture-agnostic protection framework that encodes protection into the update during fine-tuning, regardless of whether they are released as adapters or full models. Instead of relying on architecture-dependent approaches, \textsc{Trap}$^{2}$ uses weight re-scaling as a simple proxy for the merging process. It keeps released weights effective in standalone use, but degrades them under re-scaling that often arises in merging, undermining unauthorized merging.
Edge-Aware Image Manipulation via Diffusion Models with a Novel Structure-Preservation Loss
Jan 23, 2026Recent advances in image editing leverage latent diffusion models (LDMs) for versatile, text-prompt-driven edits across diverse tasks. Yet, maintaining pixel-level edge structures-crucial for tasks such as photorealistic style transfer or image tone adjustment-remains as a challenge for latent-diffusion-based editing. To overcome this limitation, we propose a novel Structure Preservation Loss (SPL) that leverages local linear models to quantify structural differences between input and edited images. Our training-free approach integrates SPL directly into the diffusion model's generative process to ensure structural fidelity. This core mechanism is complemented by a post-processing step to mitigate LDM decoding distortions, a masking strategy for precise edit localization, and a color preservation loss to preserve hues in unedited areas. Experiments confirm SPL enhances structural fidelity, delivering state-of-the-art performance in latent-diffusion-based image editing. Our code will be publicly released at https://github.com/gongms00/SPL.
VIRO: Robust and Efficient Neuro-Symbolic Reasoning with Verification for Referring Expression Comprehension
Jan 19, 2026Referring Expression Comprehension (REC) aims to localize the image region corresponding to a natural-language query. Recent neuro-symbolic REC approaches leverage large language models (LLMs) and vision-language models (VLMs) to perform compositional reasoning, decomposing queries 4 structured programs and executing them step-by-step. While such approaches achieve interpretable reasoning and strong zero-shot generalization, they assume that intermediate reasoning steps are accurate. However, this assumption causes cascading errors: false detections and invalid relations propagate through the reasoning chain, yielding high-confidence false positives even when no target is present in the image. To address this limitation, we introduce Verification-Integrated Reasoning Operators (VIRO), a neuro-symbolic framework that embeds lightweight operator-level verifiers within reasoning steps. Each operator executes and validates its output, such as object existence or spatial relationship, thereby allowing the system to robustly handle no-target cases when verification conditions are not met. Our framework achieves state-of-the-art performance, reaching 61.1% balanced accuracy across target-present and no-target settings, and demonstrates generalization to real-world egocentric data. Furthermore, VIRO shows superior computational efficiency in terms of throughput, high reliability with a program failure rate of less than 0.3%, and scalability through decoupled program generation from execution.
Improving Generative Behavior Cloning via Self-Guidance and Adaptive Chunking
Oct 14, 2025Generative Behavior Cloning (GBC) is a simple yet effective framework for robot learning, particularly in multi-task settings. Recent GBC methods often employ diffusion policies with open-loop (OL) control, where actions are generated via a diffusion process and executed in multi-step chunks without replanning. While this approach has demonstrated strong success rates and generalization, its inherent stochasticity can result in erroneous action sampling, occasionally leading to unexpected task failures. Moreover, OL control suffers from delayed responses, which can degrade performance in noisy or dynamic environments. To address these limitations, we propose two novel techniques to enhance the consistency and reactivity of diffusion policies: (1) self-guidance, which improves action fidelity by leveraging past observations and implicitly promoting future-aware behavior; and (2) adaptive chunking, which selectively updates action sequences when the benefits of reactivity outweigh the need for temporal consistency. Extensive experiments show that our approach substantially improves GBC performance across a wide range of simulated and real-world robotic manipulation tasks. Our code is available at https://github.com/junhyukso/SGAC
Delving into Instance-Dependent Label Noise in Graph Data: A Comprehensive Study and Benchmark
Jun 14, 2025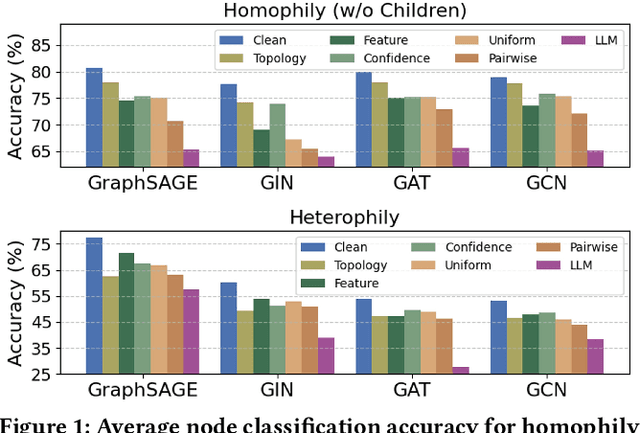
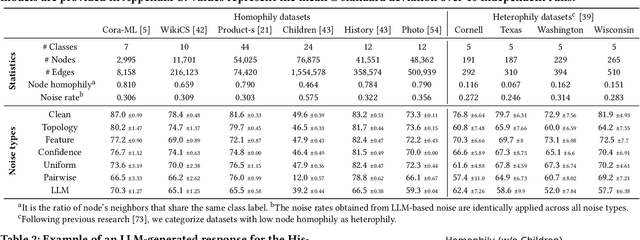
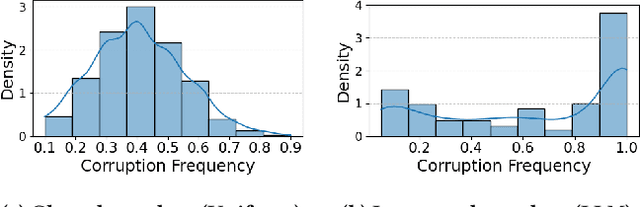
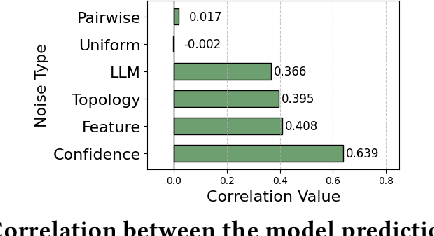
Graph Neural Networks (GNNs) have achieved state-of-the-art performance in node classification tasks but struggle with label noise in real-world data. Existing studies on graph learning with label noise commonly rely on class-dependent label noise, overlooking the complexities of instance-dependent noise and falling short of capturing real-world corruption patterns. We introduce BeGIN (Benchmarking for Graphs with Instance-dependent Noise), a new benchmark that provides realistic graph datasets with various noise types and comprehensively evaluates noise-handling strategies across GNN architectures, noisy label detection, and noise-robust learning. To simulate instance-dependent corruptions, BeGIN introduces algorithmic methods and LLM-based simulations. Our experiments reveal the challenges of instance-dependent noise, particularly LLM-based corruption, and underscore the importance of node-specific parameterization to enhance GNN robustness. By comprehensively evaluating noise-handling strategies, BeGIN provides insights into their effectiveness, efficiency, and key performance factors. We expect that BeGIN will serve as a valuable resource for advancing research on label noise in graphs and fostering the development of robust GNN training methods. The code is available at https://github.com/kimsu55/BeGIN.
* 17 pages
DeRAGEC: Denoising Named Entity Candidates with Synthetic Rationale for ASR Error Correction
Jun 09, 2025
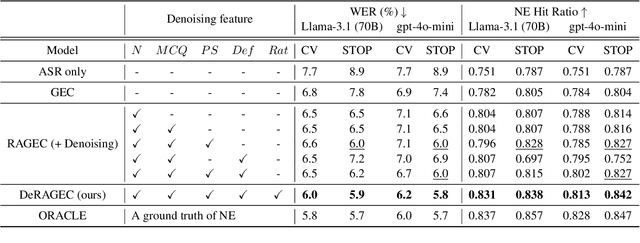

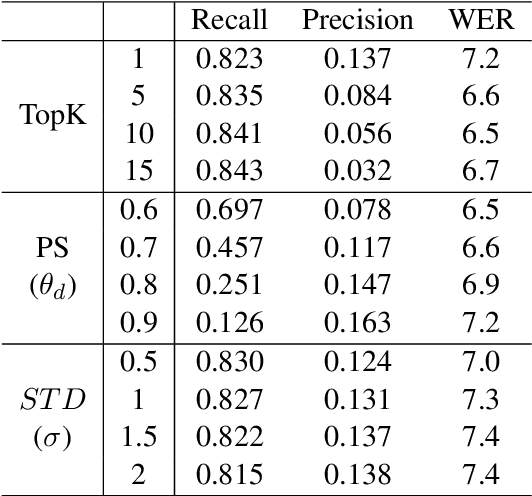
We present DeRAGEC, a method for improving Named Entity (NE) correction in Automatic Speech Recognition (ASR) systems. By extending the Retrieval-Augmented Generative Error Correction (RAGEC) framework, DeRAGEC employs synthetic denoising rationales to filter out noisy NE candidates before correction. By leveraging phonetic similarity and augmented definitions, it refines noisy retrieved NEs using in-context learning, requiring no additional training. Experimental results on CommonVoice and STOP datasets show significant improvements in Word Error Rate (WER) and NE hit ratio, outperforming baseline ASR and RAGEC methods. Specifically, we achieved a 28% relative reduction in WER compared to ASR without postprocessing. Our source code is publicly available at: https://github.com/solee0022/deragec