 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment-level Tree Search for Long Meeting Document Summarization
Jun 07, 2026Meeting documents are challenging to summarize due to their length and complex conversational structure. Existing approaches typically adopt multi-stage pipelines that extract information prior to summarization; however, these approaches often suffer from cumulative error propagation without intermediate validation, a limitation further amplified by short and low-quality reference summaries. We propose segment-level summarization via Monte Carlo Tree Search (S3), a training-free framework that constructs a final summary by composing segment-level summary candidates. S3 partitions a long document into segments and generates multiple summary candidates per segment, forming nodes of a search tree. The best-scoring combination is selected via self-reward-guided tree search and refined into the final output. Despite using a 7B model, S3 achieves performance comparable to larger 72B models while producing length-appropriate summaries.
Understanding LLM Behavior in Multi-Target Cross-Lingual Summarization
May 31, 2026Multi-target cross-lingual text summarization (MTXLS), which summarizes a source document into multiple target languages, is increasingly important as users consume content in diverse languages, but remains underexplored. To address this gap, we introduce multi-target cross-lingual element-aware (MEA), a new MTXLS benchmark covering 24 target languages. We benchmark end-to-end and pipeline approaches across various LLMs and show that MTXLS performance still substantially lags behind English monolingual summarization. To better understand MTXLS in LLMs, we propose a layer-wise analysis framework for investigating how LLMs internally perform MTXLS. Our analyses suggest that translation and summarization behaviors emerge jointly within later layers rather than as distinctly decomposed stages. Most task-relevant processing occurs within these layers, and errors also tend to arise at similar depths. Motivated by these findings, we introduce an inference-time activation steering method that leverages hidden representations from English summarization to guide MTXLS generation. Experiments show that our method consistently improves MTXLS quality across target languages.
GAIA-v2-LILT: Multilingual Adaptation of Agent Benchmark beyond Translation
Apr 27, 2026Agent benchmarks remain largely English-centric, while their multilingual versions are often built with machine translation (MT) and limited post-editing. We argue that, for agentic tasks, this minimal workflow can easily break benchmark validity through query-answer misalignment or culturally off-target context. We propose a refined workflow for adapting English benchmarks into multiple languages with explicit functional alignment, cultural alignment, and difficulty calibration using both automated checks and human review. Using this workflow, we introduce GAIA-v2-LILT, a re-audited multilingual extension of GAIA covering five non-English languages. In experiments, our workflow improves agent success rates by up to 32.7% over minimally translated versions, bringing the closest audited setting to within 3.1% of English performance while substantial gaps remain in many other cases. This indicates that a substantial share of the multilingual performance gap is benchmark-induced measurement error, motivating task-level alignment when adapting English benchmarks across languages. The data is available as part of the MAPS package at https://huggingface.co/datasets/Fujitsu-FRE/MAPS/viewer/GAIA-v2-LILT. We also release the code used in our experiments at https://github.com/lilt/gaia-v2-lilt.
Solar Open Technical Report
Jan 11, 2026We introduce Solar Open, a 102B-parameter bilingual Mixture-of-Experts language model for underserved languages. Solar Open demonstrates a systematic methodology for building competitive LLMs by addressing three interconnected challenges. First, to train effectively despite data scarcity for underserved languages, we synthesize 4.5T tokens of high-quality, domain-specific, and RL-oriented data. Second, we coordinate this data through a progressive curriculum jointly optimizing composition, quality thresholds, and domain coverage across 20 trillion tokens. Third, to enable reasoning capabilities through scalable RL, we apply our proposed framework SnapPO for efficient optimization. Across benchmarks in English and Korean, Solar Open achieves competitive performance, demonstrating the effectiveness of this methodology for underserved language AI development.
DeRAGEC: Denoising Named Entity Candidates with Synthetic Rationale for ASR Error Correction
Jun 09, 2025
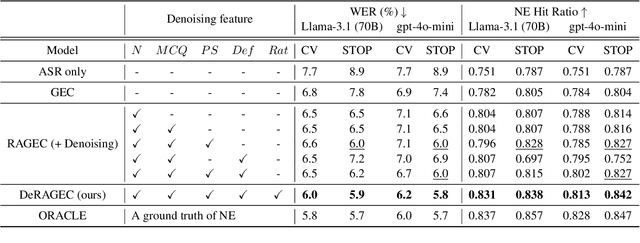

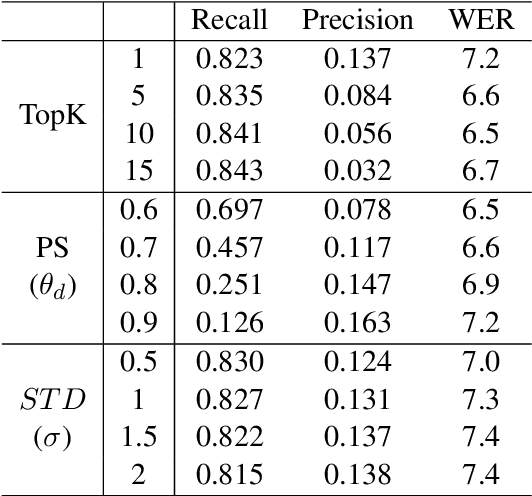
We present DeRAGEC, a method for improving Named Entity (NE) correction in Automatic Speech Recognition (ASR) systems. By extending the Retrieval-Augmented Generative Error Correction (RAGEC) framework, DeRAGEC employs synthetic denoising rationales to filter out noisy NE candidates before correction. By leveraging phonetic similarity and augmented definitions, it refines noisy retrieved NEs using in-context learning, requiring no additional training. Experimental results on CommonVoice and STOP datasets show significant improvements in Word Error Rate (WER) and NE hit ratio, outperforming baseline ASR and RAGEC methods. Specifically, we achieved a 28% relative reduction in WER compared to ASR without postprocessing. Our source code is publicly available at: https://github.com/solee0022/deragec
MiLQ: Benchmarking IR Models for Bilingual Web Search with Mixed Language Queries
May 22, 2025
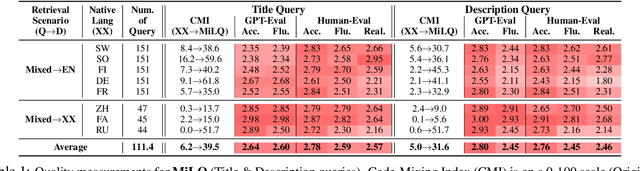

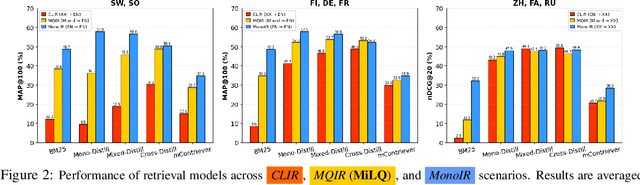
Despite bilingual speakers frequently using mixed-language queries in web searches, Information Retrieval (IR) research on them remains scarce. To address this, we introduce MiLQ,Mixed-Language Query test set, the first public benchmark of mixed-language queries, confirmed as realistic and highly preferred. Experiments show that multilingual IR models perform moderately on MiLQ and inconsistently across native, English, and mixed-language queries, also suggesting code-switched training data's potential for robust IR models handling such queries. Meanwhile, intentional English mixing in queries proves an effective strategy for bilinguals searching English documents, which our analysis attributes to enhanced token matching compared to native queries.
Revisiting Early Detection of Sexual Predators via Turn-level Optimization
Mar 09, 2025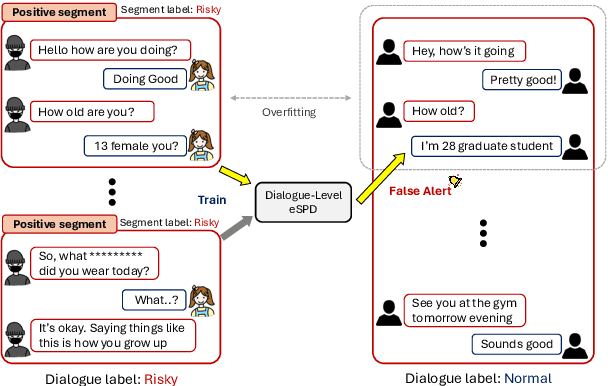



Online grooming is a severe social threat where sexual predators gradually entrap child victims with subtle and gradual manipulation. Therefore, timely intervention for online grooming is critical for proactive protection. However, previous methods fail to determine the optimal intervention points (i.e., jump to conclusions) as they rely on chat-level risk labels by causing weak supervision of risky utterances. For timely detection, we propose speed control reinforcement learning (SCoRL) (The code and supplementary materials are available at https://github.com/jinmyeongAN/SCoRL), incorporating a practical strategy derived from luring communication theory (LCT). To capture the predator's turn-level entrapment, we use a turn-level risk label based on the LCT. Then, we design a novel speed control reward function that balances the trade-off between speed and accuracy based on turn-level risk label; thus, SCoRL can identify the optimal intervention moment. In addition, we introduce a turn-level metric for precise evaluation, identifying limitations in previously used chat-level metrics. Experimental results show that SCoRL effectively preempted online grooming, offering a more proactive and timely solution. Further analysis reveals that our method enhances performance while intuitively identifying optimal early intervention points.
DyPCL: Dynamic Phoneme-level Contrastive Learning for Dysarthric Speech Recognition
Jan 31, 2025Dysarthric speech recognition often suffers from performance degradation due to the intrinsic diversity of dysarthric severity and extrinsic disparity from normal speech. To bridge these gaps, we propose a Dynamic Phoneme-level Contrastive Learning (DyPCL) method, which leads to obtaining invariant representations across diverse speakers. We decompose the speech utterance into phoneme segments for phoneme-level contrastive learning, leveraging dynamic connectionist temporal classification alignment. Unlike prior studies focusing on utterance-level embeddings, our granular learning allows discrimination of subtle parts of speech. In addition, we introduce dynamic curriculum learning, which progressively transitions from easy negative samples to difficult-to-distinguishable negative samples based on phonetic similarity of phoneme. Our approach to training by difficulty levels alleviates the inherent variability of speakers, better identifying challenging speeches. Evaluated on the UASpeech dataset, DyPCL outperforms baseline models, achieving an average 22.10\% relative reduction in word error rate (WER) across the overall dysarthria group.
Bel Esprit: Multi-Agent Framework for Building AI Model Pipelines
Dec 19, 2024


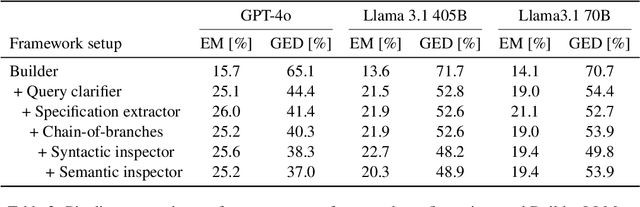
As the demand for artificial intelligence (AI) grows to address complex real-world tasks, single models are often insufficient, requiring the integration of multiple models into pipelines. This paper introduces Bel Esprit, a conversational agent designed to construct AI model pipelines based on user-defined requirements. Bel Esprit employs a multi-agent framework where subagents collaborate to clarify requirements, build, validate, and populate pipelines with appropriate models. We demonstrate the effectiveness of this framework in generating pipelines from ambiguous user queries, using both human-curated and synthetic data. A detailed error analysis highlights ongoing challenges in pipeline construction. Bel Esprit is available for a free trial at https://belesprit.aixplain.com.
Guide-to-Explain for Controllable Summarization
Nov 19, 2024



Recently, large language models (LLMs) have demonstrated remarkable performance in abstractive summarization tasks. However, controllable summarization with LLMs remains underexplored, limiting their ability to generate summaries that align with specific user preferences. In this paper, we first investigate the capability of LLMs to control diverse attributes, revealing that they encounter greater challenges with numerical attributes, such as length and extractiveness, compared to linguistic attributes. To address this challenge, we propose a guide-to-explain framework (GTE) for controllable summarization. Our GTE framework enables the model to identify misaligned attributes in the initial draft and guides it in explaining errors in the previous output. Based on this reflection, the model generates a well-adjusted summary. As a result, by allowing the model to reflect on its misalignment, we generate summaries that satisfy the desired attributes in surprisingly fewer iterations than other iterative methods solely using LLMs.