 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuRE:Generative Query REwriter for Legal Passage Retrieval
May 19, 2025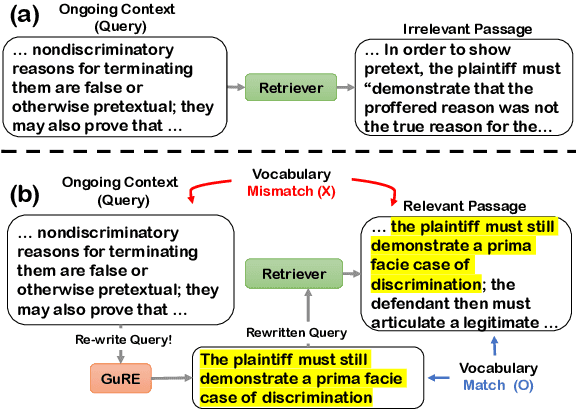
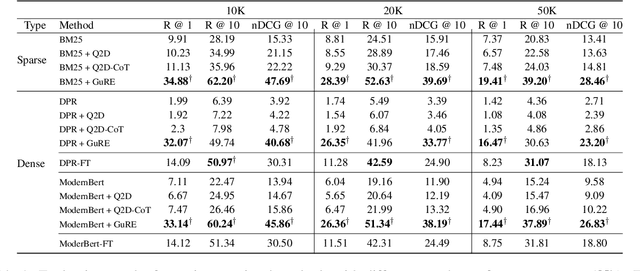
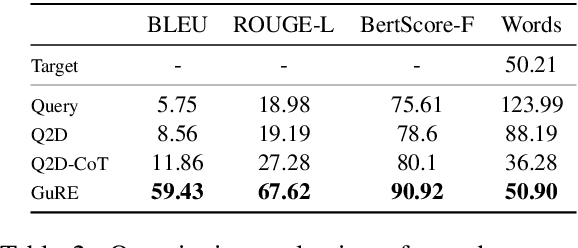

Legal Passage Retrieval (LPR) systems are crucial as they help practitioners save time when drafting legal arguments. However, it remains an underexplored avenue. One primary reason is the significant vocabulary mismatch between the query and the target passage. To address this, we propose a simple yet effective method, the Generative query REwriter (GuRE). We leverage the generative capabilities of Large Language Models (LLMs) by training the LLM for query rewriting. "Rewritten queries" help retrievers to retrieve target passages by mitigating vocabulary mismatch. Experimental results show that GuRE significantly improves performance in a retriever-agnostic manner, outperforming all baseline methods. Further analysis reveals that different training objectives lead to distinct retrieval behaviors, making GuRE more suitable than direct retriever fine-tuning for real-world applications. Codes are avaiable at github.com/daehuikim/GuRE.
Closer through commonality: Enhancing hypergraph contrastive learning with shared groups
Feb 12, 2025Hypergraphs provide a superior modeling framework for representing complex multidimensional relationships in the context of real-world interactions that often occur in groups, overcoming the limitations of traditional homogeneous graphs. However, there have been few studies on hypergraphbased contrastive learning, and existing graph-based contrastive learning methods have not been able to fully exploit the highorder correlation information in hypergraphs. Here, we propose a Hypergraph Fine-grained contrastive learning (HyFi) method designed to exploit the complex high-dimensional information inherent in hypergraphs. While avoiding traditional graph augmentation methods that corrupt the hypergraph topology, the proposed method provides a simple and efficient learning augmentation function by adding noise to node features. Furthermore, we expands beyond the traditional dichotomous relationship between positive and negative samples in contrastive learning by introducing a new relationship of weak positives. It demonstrates the importance of fine-graining positive samples in contrastive learning. Therefore, HyFi is able to produce highquality embeddings, and outperforms both supervised and unsupervised baselines in average rank on node classification across 10 datasets. Our approach effectively exploits high-dimensional hypergraph information, shows significant improvement over existing graph-based contrastive learning methods, and is efficient in terms of training speed and GPU memory cost. The source code is available at https://github.com/Noverse0/HyFi.git.
Guide-to-Explain for Controllable Summarization
Nov 19, 2024



Recently, large language models (LLMs) have demonstrated remarkable performance in abstractive summarization tasks. However, controllable summarization with LLMs remains underexplored, limiting their ability to generate summaries that align with specific user preferences. In this paper, we first investigate the capability of LLMs to control diverse attributes, revealing that they encounter greater challenges with numerical attributes, such as length and extractiveness, compared to linguistic attributes. To address this challenge, we propose a guide-to-explain framework (GTE) for controllable summarization. Our GTE framework enables the model to identify misaligned attributes in the initial draft and guides it in explaining errors in the previous output. Based on this reflection, the model generates a well-adjusted summary. As a result, by allowing the model to reflect on its misalignment, we generate summaries that satisfy the desired attributes in surprisingly fewer iterations than other iterative methods solely using LLMs.
Ontology-Free General-Domain Knowledge Graph-to-Text Generation Dataset Synthesis using Large Language Model
Sep 11, 2024



Knowledge Graph-to-Text (G2T) generation involves verbalizing structured knowledge graphs into natural language text. Recent advancements in Pretrained Language Models (PLMs) have improved G2T performance, but their effectiveness depends on datasets with precise graph-text alignment. However, the scarcity of high-quality, general-domain G2T generation datasets restricts progress in the general-domain G2T generation research. To address this issue, we introduce Wikipedia Ontology-Free Graph-text dataset (WikiOFGraph), a new large-scale G2T dataset generated using a novel method that leverages Large Language Model (LLM) and Data-QuestEval. Our new dataset, which contains 5.85M general-domain graph-text pairs, offers high graph-text consistency without relying on external ontologies. Experimental results demonstrate that PLM fine-tuned on WikiOFGraph outperforms those trained on other datasets across various evaluation metrics. Our method proves to be a scalable and effective solution for generating high-quality G2T data, significantly advancing the field of G2T generation.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
SCOB: Universal Text Understanding via Character-wise Supervised Contrastive Learning with Online Text Rendering for Bridging Domain Gap
Sep 21, 2023


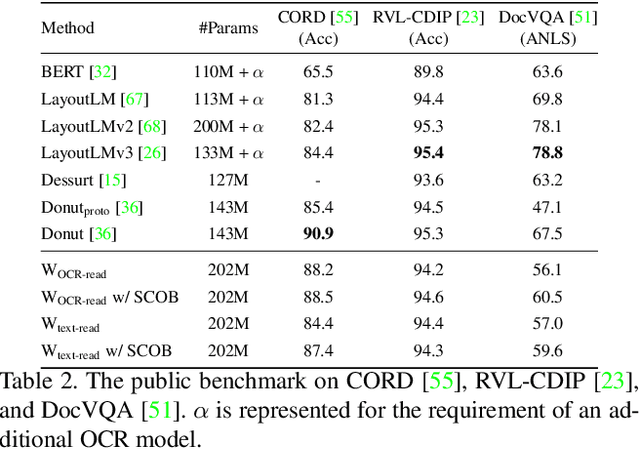
Inspired by the great success of language model (LM)-based pre-training, recent studies in visual document understanding have explored LM-based pre-training methods for modeling text within document images. Among them, pre-training that reads all text from an image has shown promise, but often exhibits instability and even fails when applied to broader domains, such as those involving both visual documents and scene text images. This is a substantial limitation for real-world scenarios, where the processing of text image inputs in diverse domains is essential. In this paper, we investigate effective pre-training tasks in the broader domains and also propose a novel pre-training method called SCOB that leverages character-wise supervised contrastive learning with online text rendering to effectively pre-train document and scene text domains by bridging the domain gap. Moreover, SCOB enables weakly supervised learning, significantly reducing annotation costs. Extensive benchmarks demonstrate that SCOB generally improves vanilla pre-training methods and achieves comparable performance to state-of-the-art methods. Our findings suggest that SCOB can be served generally and effectively for read-type pre-training methods. The code will be available at https://github.com/naver-ai/scob.
Cream: Visually-Situated Natural Language Understanding with Contrastive Reading Model and Frozen Large Language Models
May 24, 2023
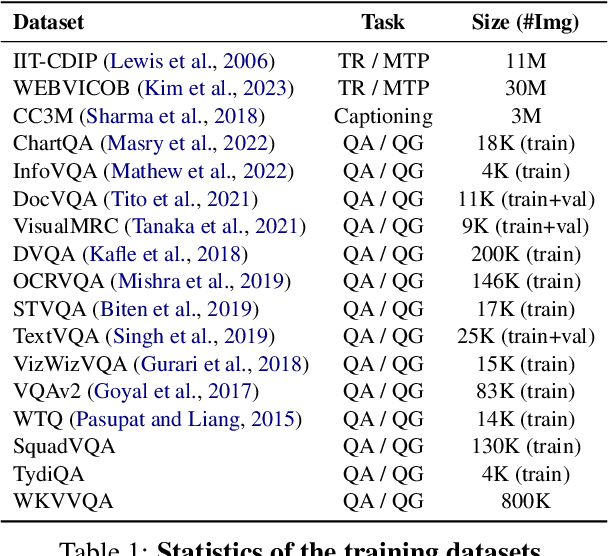
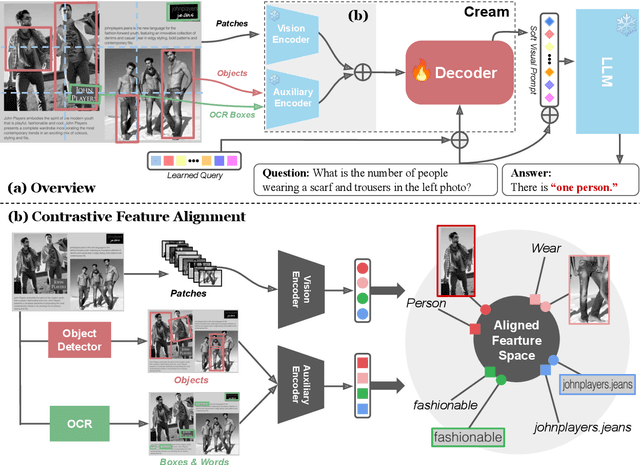

Advances in Large Language Models (LLMs) have inspired a surge of research exploring their expansion into the visual domain. While recent models exhibit promise in generating abstract captions for images and conducting natural conversations, their performance on text-rich images leaves room for improvement. In this paper, we propose the Contrastive Reading Model (Cream), a novel neural architecture designed to enhance the language-image understanding capability of LLMs by capturing intricate details typically overlooked by existing methods. Cream integrates vision and auxiliary encoders, complemented by a contrastive feature alignment technique, resulting in a more effective understanding of textual information within document images. Our approach, thus, seeks to bridge the gap between vision and language understanding, paving the way for more sophisticated Document Intelligence Assistants. Rigorous evaluations across diverse tasks, such as visual question answering on document images, demonstrate the efficacy of Cream as a state-of-the-art model in the field of visual document understanding. We provide our codebase and newly-generated datasets at https://github.com/naver-ai/cream
Towards Unified Scene Text Spotting based on Sequence Generation
Apr 07, 2023
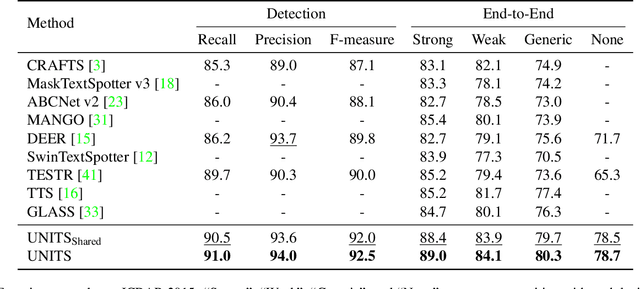

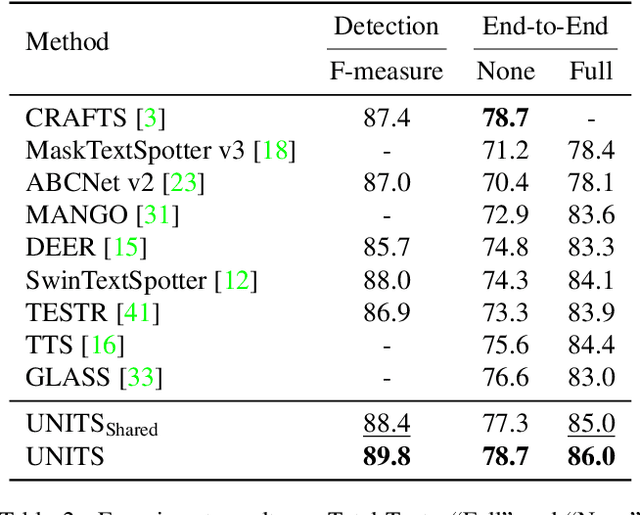
Sequence generation models have recently made significant progress in unifying various vision tasks. Although some auto-regressive models have demonstrated promising results in end-to-end text spotting, they use specific detection formats while ignoring various text shapes and are limited in the maximum number of text instances that can be detected. To overcome these limitations, we propose a UNIfied scene Text Spotter, called UNITS. Our model unifies various detection formats, including quadrilaterals and polygons, allowing it to detect text in arbitrary shapes. Additionally, we apply starting-point prompting to enable the model to extract texts from an arbitrary starting point, thereby extracting more texts beyond the number of instances it was trained on. Experimental results demonstrate that our method achieves competitive performance compared to state-of-the-art methods. Further analysis shows that UNITS can extract a larger number of texts than it was trained on. We provide the code for our method at https://github.com/clovaai/units.
Supervised Contrastive ResNet and Transfer Learning for the In-vehicle Intrusion Detection System
Jul 18, 2022
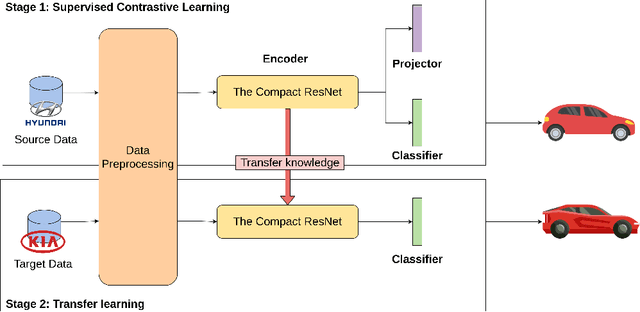
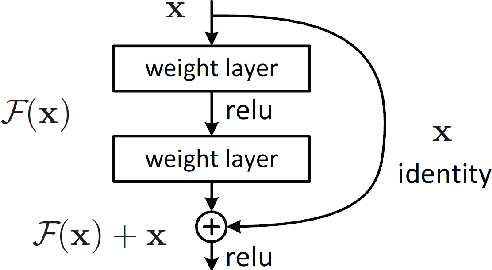
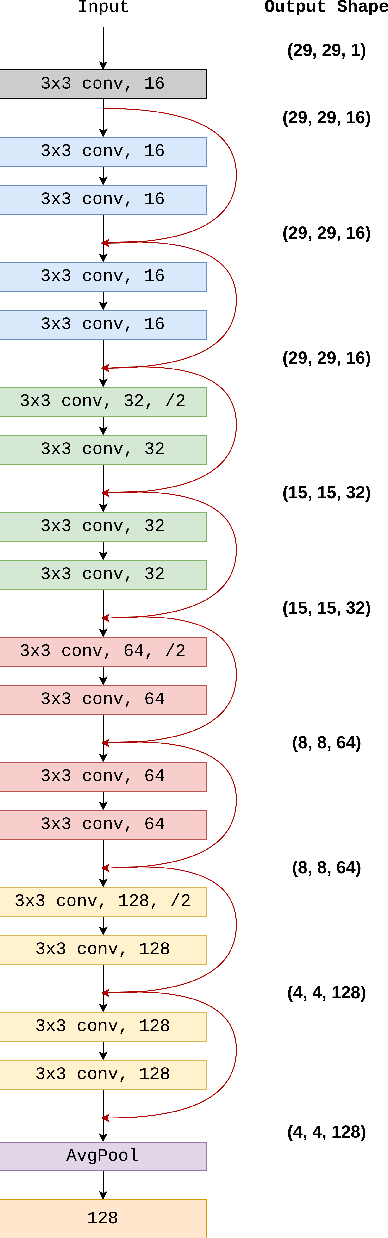
High-end vehicles have been furnished with a number of electronic control units (ECUs), which provide upgrading functions to enhance the driving experience. The controller area network (CAN) is a well-known protocol that connects these ECUs because of its modesty and efficiency. However, the CAN bus is vulnerable to various types of attacks. Although the intrusion detection system (IDS) is proposed to address the security problem of the CAN bus, most previous studies only provide alerts when attacks occur without knowing the specific type of attack. Moreover, an IDS is designed for a specific car model due to diverse car manufacturers. In this study, we proposed a novel deep learning model called supervised contrastive (SupCon) ResNet, which can handle multiple attack identification on the CAN bus. Furthermore, the model can be used to improve the performance of a limited-size dataset using a transfer learning technique. The capability of the proposed model is evaluated on two real car datasets. When tested with the car hacking dataset, the experiment results show that the SupCon ResNet model improves the overall false-negative rates of four types of attack by four times on average, compared to other models. In addition, the model achieves the highest F1 score at 0.9994 on the survival dataset by utilizing transfer learning. Finally, the model can adapt to hardware constraints in terms of memory size and running time.
SelfReg: Self-supervised Contrastive Regularization for Domain Generalization
Apr 20, 2021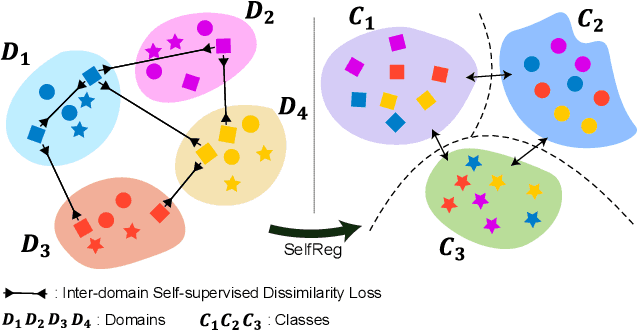
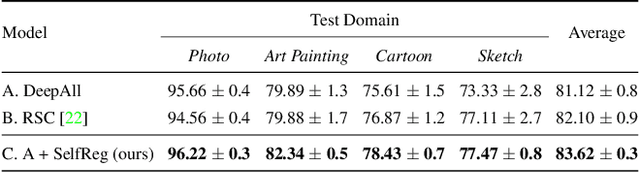
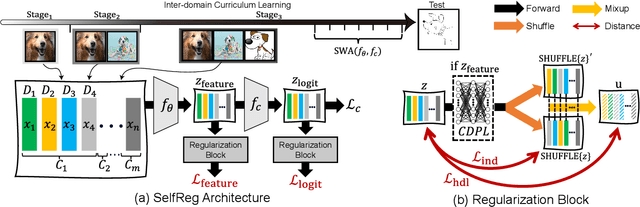

In general, an experimental environment for deep learning assumes that the training and the test dataset are sampled from the same distribution. However, in real-world situations, a difference in the distribution between two datasets, domain shift, may occur, which becomes a major factor impeding the generalization performance of the model. The research field to solve this problem is called domain generalization, and it alleviates the domain shift problem by extracting domain-invariant features explicitly or implicitly. In recent studies, contrastive learning-based domain generalization approaches have been proposed and achieved high performance. These approaches require sampling of the negative data pair. However, the performance of contrastive learning fundamentally depends on quality and quantity of negative data pairs. To address this issue, we propose a new regularization method for domain generalization based on contrastive learning, self-supervised contrastive regularization (SelfReg). The proposed approach use only positive data pairs, thus it resolves various problems caused by negative pair sampling. Moreover, we propose a class-specific domain perturbation layer (CDPL), which makes it possible to effectively apply mixup augmentation even when only positive data pairs are used. The experimental results show that the techniques incorporated by SelfReg contributed to the performance in a compatible manner. In the recent benchmark, DomainBed, the proposed method shows comparable performance to the conventional state-of-the-art alternatives. Codes are available at https://github.com/dnap512/SelfReg.