 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Based Facial Retargeting Using Local Patches
Jan 13, 2026In the era of digital animation, the quest to produce lifelike facial animations for virtual characters has led to the development of various retargeting methods. While the retargeting facial motion between models of similar shapes has been very successful, challenges arise when the retargeting is performed on stylized or exaggerated 3D characters that deviate significantly from human facial structures. In this scenario, it is important to consider the target character's facial structure and possible range of motion to preserve the semantics assumed by the original facial motions after the retargeting. To achieve this, we propose a local patch-based retargeting method that transfers facial animations captured in a source performance video to a target stylized 3D character. Our method consists of three modules. The Automatic Patch Extraction Module extracts local patches from the source video frame. These patches are processed through the Reenactment Module to generate correspondingly re-enacted target local patches. The Weight Estimation Module calculates the animation parameters for the target character at every frame for the creation of a complete facial animation sequence. Extensive experiments demonstrate that our method can successfully transfer the semantic meaning of source facial expressions to stylized characters with considerable variations in facial feature proportion.
* Eurographics 25
Enabling Automatic Self-Talk Detection via Earables
Nov 10, 2025



Self-talk-an internal dialogue that can occur silently or be spoken aloud-plays a crucial role in emotional regulation, cognitive processing, and motivation, yet has remained largely invisible and unmeasurable in everyday life. In this paper, we present MutterMeter, a mobile system that automatically detects vocalized self-talk from audio captured by earable microphones in real-world settings. Detecting self-talk is technically challenging due to its diverse acoustic forms, semantic and grammatical incompleteness, and irregular occurrence patterns, which differ fundamentally from assumptions underlying conventional speech understanding models. To address these challenges, MutterMeter employs a hierarchical classification architecture that progressively integrates acoustic, linguistic, and contextual information through a sequential processing pipeline, adaptively balancing accuracy and computational efficiency. We build and evaluate MutterMeter using a first-of-its-kind dataset comprising 31.1 hours of audio collected from 25 participants. Experimental results demonstrate that MutterMeter achieves robust performance with a macro-averaged F1 score of 0.84, outperforming conventional approaches, including LLM-based and speech emotion recognition models.
Learning to Explore for Stochastic Gradient MCMC
Aug 17, 2024Bayesian Neural Networks(BNNs) with high-dimensional parameters pose a challenge for posterior inference due to the multi-modality of the posterior distributions. Stochastic Gradient MCMC(SGMCMC) with cyclical learning rate scheduling is a promising solution, but it requires a large number of sampling steps to explore high-dimensional multi-modal posteriors, making it computationally expensive. In this paper, we propose a meta-learning strategy to build \gls{sgmcmc} which can efficiently explore the multi-modal target distributions. Our algorithm allows the learned SGMCMC to quickly explore the high-density region of the posterior landscape. Also, we show that this exploration property is transferrable to various tasks, even for the ones unseen during a meta-training stage. Using popular image classification benchmarks and a variety of downstream tasks, we demonstrate that our method significantly improves the sampling efficiency, achieving better performance than vanilla \gls{sgmcmc} without incurring significant computational overhead.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
TRACE: Table Reconstruction Aligned to Corner and Edges
May 01, 2023



A table is an object that captures structured and informative content within a document, and recognizing a table in an image is challenging due to the complexity and variety of table layouts. Many previous works typically adopt a two-stage approach; (1) Table detection(TD) localizes the table region in an image and (2) Table Structure Recognition(TSR) identifies row- and column-wise adjacency relations between the cells. The use of a two-stage approach often entails the consequences of error propagation between the modules and raises training and inference inefficiency. In this work, we analyze the natural characteristics of a table, where a table is composed of cells and each cell is made up of borders consisting of edges. We propose a novel method to reconstruct the table in a bottom-up manner. Through a simple process, the proposed method separates cell boundaries from low-level features, such as corners and edges, and localizes table positions by combining the cells. A simple design makes the model easier to train and requires less computation than previous two-stage methods. We achieve state-of-the-art performance on the ICDAR2013 table competition benchmark and Wired Table in the Wild(WTW) dataset.
Towards Unified Scene Text Spotting based on Sequence Generation
Apr 07, 2023
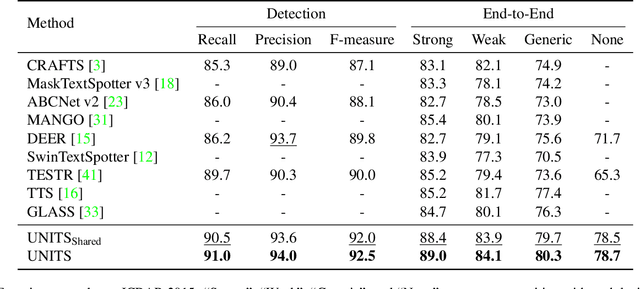

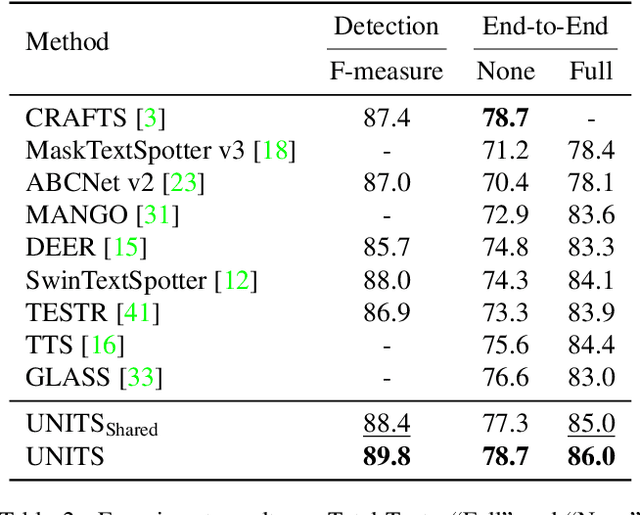
Sequence generation models have recently made significant progress in unifying various vision tasks. Although some auto-regressive models have demonstrated promising results in end-to-end text spotting, they use specific detection formats while ignoring various text shapes and are limited in the maximum number of text instances that can be detected. To overcome these limitations, we propose a UNIfied scene Text Spotter, called UNITS. Our model unifies various detection formats, including quadrilaterals and polygons, allowing it to detect text in arbitrary shapes. Additionally, we apply starting-point prompting to enable the model to extract texts from an arbitrary starting point, thereby extracting more texts beyond the number of instances it was trained on. Experimental results demonstrate that our method achieves competitive performance compared to state-of-the-art methods. Further analysis shows that UNITS can extract a larger number of texts than it was trained on. We provide the code for our method at https://github.com/clovaai/units.
Generator Knows What Discriminator Should Learn in Unconditional GANs
Jul 27, 2022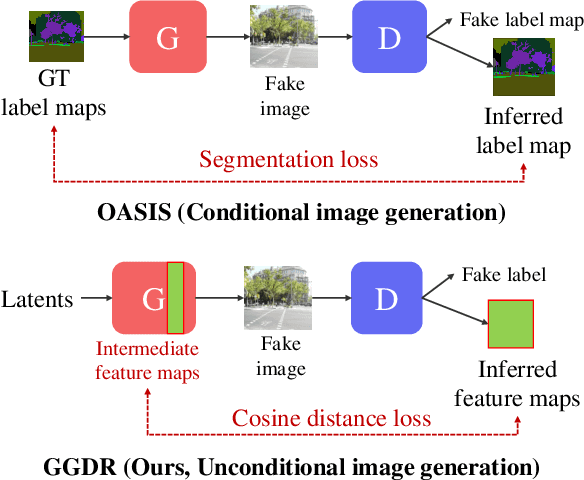
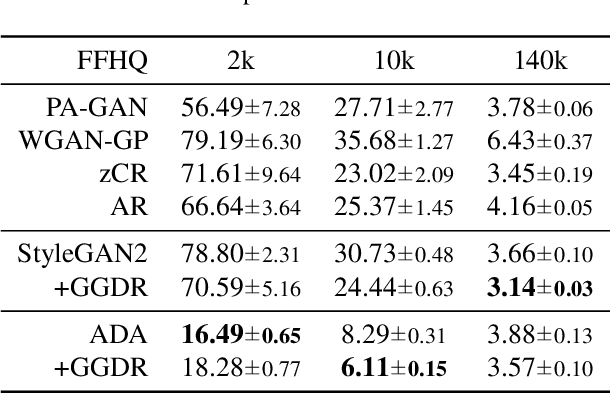
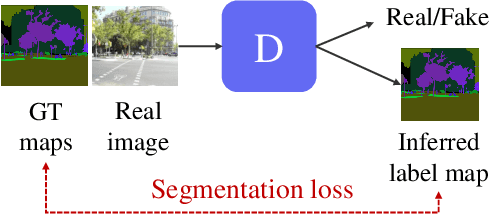
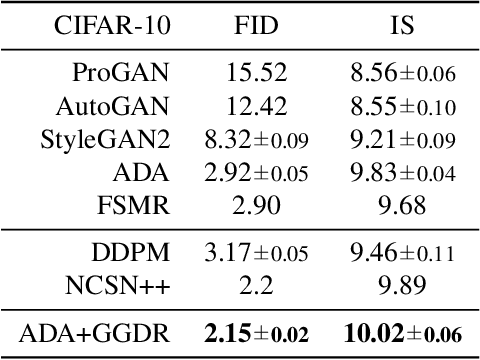
Recent methods for conditional image generation benefit from dense supervision such as segmentation label maps to achieve high-fidelity. However, it is rarely explored to employ dense supervision for unconditional image generation. Here we explore the efficacy of dense supervision in unconditional generation and find generator feature maps can be an alternative of cost-expensive semantic label maps. From our empirical evidences, we propose a new generator-guided discriminator regularization(GGDR) in which the generator feature maps supervise the discriminator to have rich semantic representations in unconditional generation. In specific, we employ an U-Net architecture for discriminator, which is trained to predict the generator feature maps given fake images as inputs. Extensive experiments on mulitple datasets show that our GGDR consistently improves the performance of baseline methods in terms of quantitative and qualitative aspects. Code is available at https://github.com/naver-ai/GGDR
DEER: Detection-agnostic End-to-End Recognizer for Scene Text Spotting
Mar 10, 2022
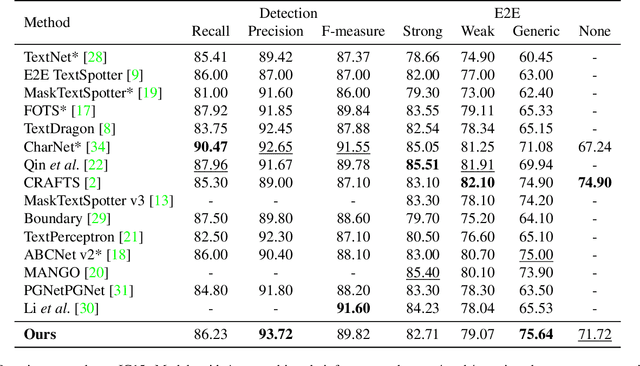
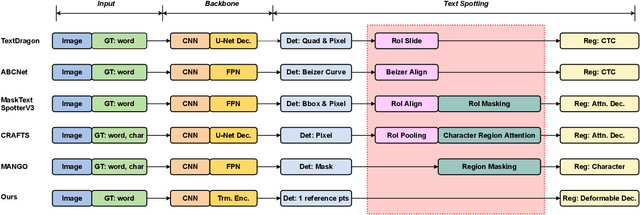
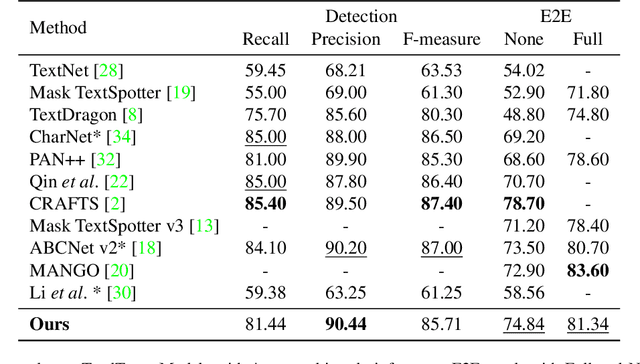
Recent end-to-end scene text spotters have achieved great improvement in recognizing arbitrary-shaped text instances. Common approaches for text spotting use region of interest pooling or segmentation masks to restrict features to single text instances. However, this makes it hard for the recognizer to decode correct sequences when the detection is not accurate i.e. one or more characters are cropped out. Considering that it is hard to accurately decide word boundaries with only the detector, we propose a novel Detection-agnostic End-to-End Recognizer, DEER, framework. The proposed method reduces the tight dependency between detection and recognition modules by bridging them with a single reference point for each text instance, instead of using detected regions. The proposed method allows the decoder to recognize the texts that are indicated by the reference point, with features from the whole image. Since only a single point is required to recognize the text, the proposed method enables text spotting without an arbitrarily-shaped detector or bounding polygon annotations. Experimental results present that the proposed method achieves competitive results on regular and arbitrarily-shaped text spotting benchmarks. Further analysis shows that DEER is robust to the detection errors. The code and dataset will be publicly available.
RewriteNet: Realistic Scene Text Image Generation via Editing Text in Real-world Image
Jul 23, 2021
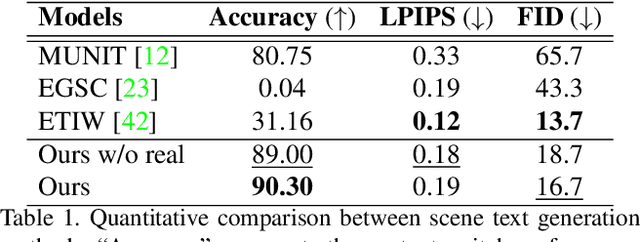
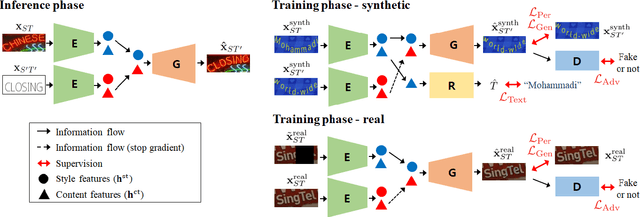
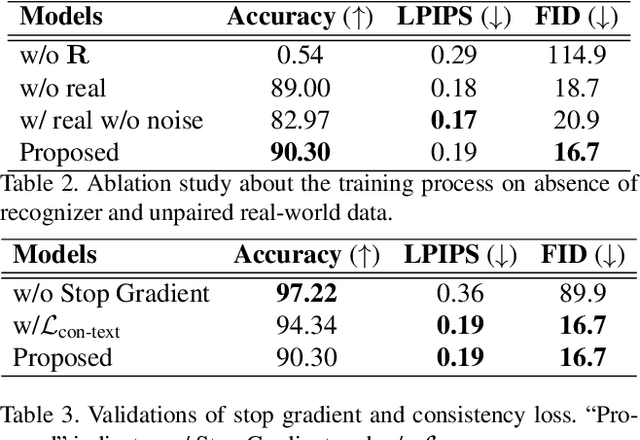
Scene text editing (STE), which converts a text in a scene image into the desired text while preserving an original style, is a challenging task due to a complex intervention between text and style. To address this challenge, we propose a novel representational learning-based STE model, referred to as RewriteNet that employs textual information as well as visual information. We assume that the scene text image can be decomposed into content and style features where the former represents the text information and style represents scene text characteristics such as font, alignment, and background. Under this assumption, we propose a method to separately encode content and style features of the input image by introducing the scene text recognizer that is trained by text information. Then, a text-edited image is generated by combining the style feature from the original image and the content feature from the target text. Unlike previous works that are only able to use synthetic images in the training phase, we also exploit real-world images by proposing a self-supervised training scheme, which bridges the domain gap between synthetic and real data. Our experiments demonstrate that RewriteNet achieves better quantitative and qualitative performance than other comparisons. Moreover, we validate that the use of text information and the self-supervised training scheme improves text switching performance. The implementation and dataset will be publicly available.
Few-shot Compositional Font Generation with Dual Memory
May 21, 2020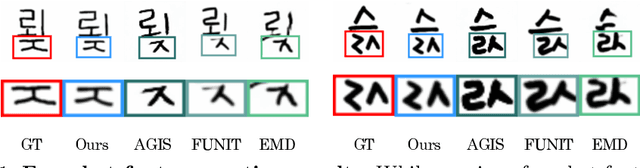
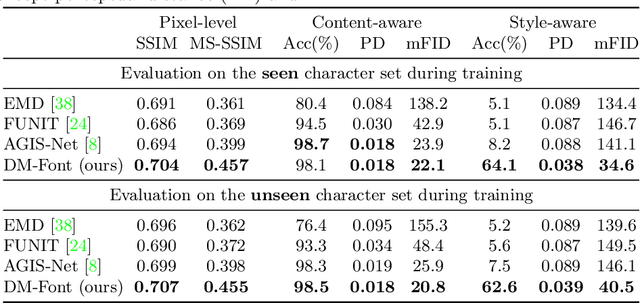
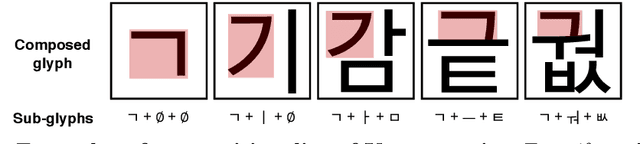
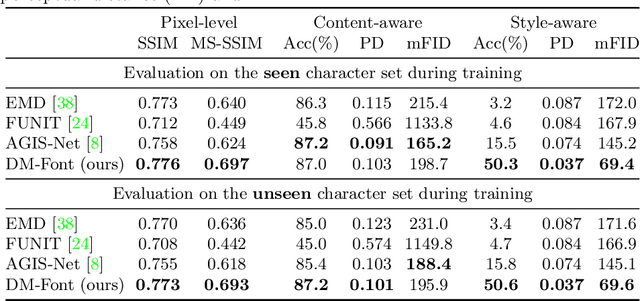
Generating a new font library is a very labor-intensive and time-consuming job for glyph-rich scripts. Despite the remarkable success of existing font generation methods, they have significant drawbacks; they require a large number of reference images to generate a new font set, or they fail to capture detailed styles with a few samples. In this paper, we focus on compositional scripts, a widely used letter system in the world, where each glyph can be decomposed by several components. By utilizing the compositionality of compositional scripts, we propose a novel font generation framework, named Dual Memory-augmented Font Generation Network (DM-Font), which enables us to generate a high-quality font library with only a few samples. We employ memory components and global-context awareness in the generator to take advantage of the compositionality. In the experiments on Korean-handwriting fonts and Thai-printing fonts, we observe that our method generates a significantly better quality of samples with faithful stylization compared to the state-of-the-art generation methods in quantitatively and qualitatively.