 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLINT: Modeling Scene-Scale Transparency via Gaussian Radiance Transport
Mar 27, 2026While 3D Gaussian splatting has emerged as a powerful paradigm, it fundamentally fails to model transparency such as glass panels. The core challenge lies in decoupling the intertwined radiance contributions from transparent interfaces and the transmitted geometry observed through the glass. We present GLINT, a framework that models scene-scale transparency through explicit decomposed Gaussian representation. GLINT reconstructs the primary interface and models reflected and transmitted radiance separately, enabling consistent radiance transport. During optimization, GLINT bootstraps transparency localization from geometry-separation cues induced by the decomposition, together with geometry and material priors from a pre-trained video relighting model. Extensive experiments demonstrate consistent improvements over prior methods for reconstructing complex transparent scenes.
LighthouseGS: Indoor Structure-aware 3D Gaussian Splatting for Panorama-Style Mobile Captures
Jul 08, 2025Recent advances in 3D Gaussian Splatting (3DGS) have enabled real-time novel view synthesis (NVS) with impressive quality in indoor scenes. However, achieving high-fidelity rendering requires meticulously captured images covering the entire scene, limiting accessibility for general users. We aim to develop a practical 3DGS-based NVS framework using simple panorama-style motion with a handheld camera (e.g., mobile device). While convenient, this rotation-dominant motion and narrow baseline make accurate camera pose and 3D point estimation challenging, especially in textureless indoor scenes. To address these challenges, we propose LighthouseGS, a novel framework inspired by the lighthouse-like sweeping motion of panoramic views. LighthouseGS leverages rough geometric priors, such as mobile device camera poses and monocular depth estimation, and utilizes the planar structures often found in indoor environments. We present a new initialization method called plane scaffold assembly to generate consistent 3D points on these structures, followed by a stable pruning strategy to enhance geometry and optimization stability. Additionally, we introduce geometric and photometric corrections to resolve inconsistencies from motion drift and auto-exposure in mobile devices. Tested on collected real and synthetic indoor scenes, LighthouseGS delivers photorealistic rendering, surpassing state-of-the-art methods and demonstrating the potential for panoramic view synthesis and object placement.
MetaFormer: High-fidelity Metalens Imaging via Aberration Correcting Transformers
Dec 05, 2024



Metalens is an emerging optical system with an irreplaceable merit in that it can be manufactured in ultra-thin and compact sizes, which shows great promise of various applications such as medical imaging and augmented/virtual reality (AR/VR). Despite its advantage in miniaturization, its practicality is constrained by severe aberrations and distortions, which significantly degrade the image quality. Several previous arts have attempted to address different types of aberrations, yet most of them are mainly designed for the traditional bulky lens and not convincing enough to remedy harsh aberrations of the metalens. While there have existed aberration correction methods specifically for metalens, they still fall short of restoration quality. In this work, we propose MetaFormer, an aberration correction framework for metalens-captured images, harnessing Vision Transformers (ViT) that has shown remarkable restoration performance in diverse image restoration tasks. Specifically, we devise a Multiple Adaptive Filters Guidance (MAFG), where multiple Wiener filters enrich the degraded input images with various noise-detail balances, enhancing output restoration quality. In addition, we introduce a Spatial and Transposed self-Attention Fusion (STAF) module, which aggregates features from spatial self-attention and transposed self-attention modules to further ameliorate aberration correction. We conduct extensive experiments, including correcting aberrated images and videos, and clean 3D reconstruction from the degraded images. The proposed method outperforms the previous arts by a significant margin. We further fabricate a metalens and verify the practicality of MetaFormer by restoring the images captured with the manufactured metalens in the wild. Code and pre-trained models are available at https://benhenryl.github.io/MetaFormer
Learning Infinitesimal Generators of Continuous Symmetries from Data
Oct 29, 2024Exploiting symmetry inherent in data can significantly improve the sample efficiency of a learning procedure and the generalization of learned models. When data clearly reveals underlying symmetry, leveraging this symmetry can naturally inform the design of model architectures or learning strategies. Yet, in numerous real-world scenarios, identifying the specific symmetry within a given data distribution often proves ambiguous. To tackle this, some existing works learn symmetry in a data-driven manner, parameterizing and learning expected symmetry through data. However, these methods often rely on explicit knowledge, such as pre-defined Lie groups, which are typically restricted to linear or affine transformations. In this paper, we propose a novel symmetry learning algorithm based on transformations defined with one-parameter groups, continuously parameterized transformations flowing along the directions of vector fields called infinitesimal generators. Our method is built upon minimal inductive biases, encompassing not only commonly utilized symmetries rooted in Lie groups but also extending to symmetries derived from nonlinear generators. To learn these symmetries, we introduce a notion of a validity score that examine whether the transformed data is still valid for the given task. The validity score is designed to be fully differentiable and easily computable, enabling effective searches for transformations that achieve symmetries innate to the data. We apply our method mainly in two domains: image data and partial differential equations, and demonstrate its advantages. Our codes are available at \url{https://github.com/kogyeonghoon/learning-symmetry-from-scratch.git}.
Variational Partial Group Convolutions for Input-Aware Partial Equivariance of Rotations and Color-Shifts
Jul 05, 2024

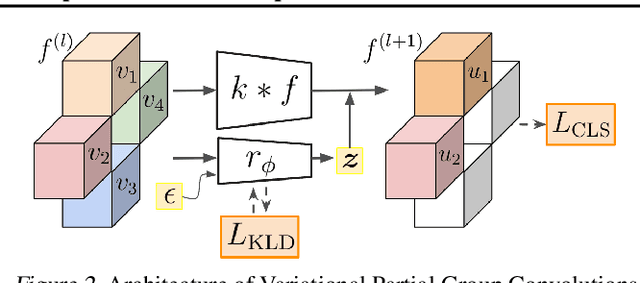

Group Equivariant CNNs (G-CNNs) have shown promising efficacy in various tasks, owing to their ability to capture hierarchical features in an equivariant manner. However, their equivariance is fixed to the symmetry of the whole group, limiting adaptability to diverse partial symmetries in real-world datasets, such as limited rotation symmetry of handwritten digit images and limited color-shift symmetry of flower images. Recent efforts address this limitation, one example being Partial G-CNN which restricts the output group space of convolution layers to break full equivariance. However, such an approach still fails to adjust equivariance levels across data. In this paper, we propose a novel approach, Variational Partial G-CNN (VP G-CNN), to capture varying levels of partial equivariance specific to each data instance. VP G-CNN redesigns the distribution of the output group elements to be conditioned on input data, leveraging variational inference to avoid overfitting. This enables the model to adjust its equivariance levels according to the needs of individual data points. Additionally, we address training instability inherent in discrete group equivariance models by redesigning the reparametrizable distribution. We demonstrate the effectiveness of VP G-CNN on both toy and real-world datasets, including MNIST67-180, CIFAR10, ColorMNIST, and Flowers102. Our results show robust performance, even in uncertainty metrics.
Fast Ensembling with Diffusion Schrödinger Bridge
Apr 24, 2024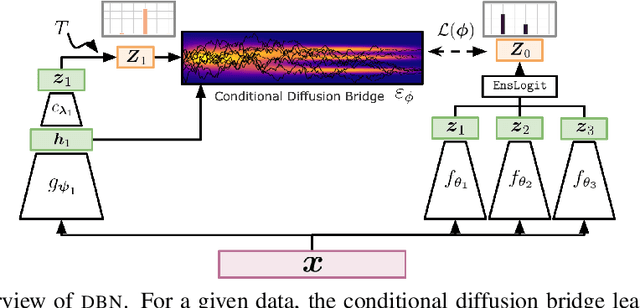
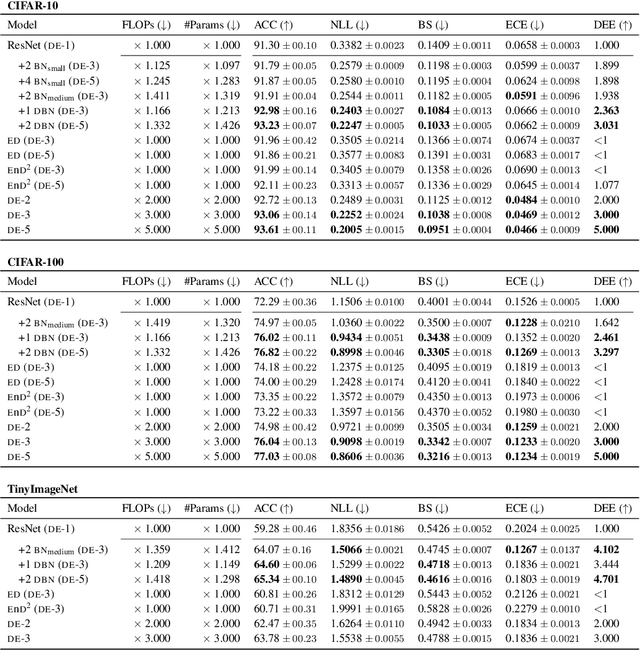
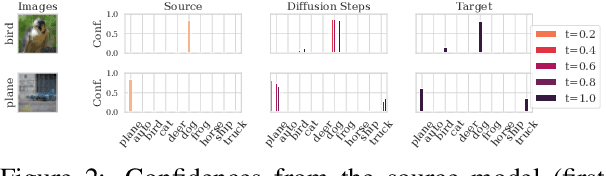

Deep Ensemble (DE) approach is a straightforward technique used to enhance the performance of deep neural networks by training them from different initial points, converging towards various local optima. However, a limitation of this methodology lies in its high computational overhead for inference, arising from the necessity to store numerous learned parameters and execute individual forward passes for each parameter during the inference stage. We propose a novel approach called Diffusion Bridge Network (DBN) to address this challenge. Based on the theory of the Schr\"odinger bridge, this method directly learns to simulate an Stochastic Differential Equation (SDE) that connects the output distribution of a single ensemble member to the output distribution of the ensembled model, allowing us to obtain ensemble prediction without having to invoke forward pass through all the ensemble models. By substituting the heavy ensembles with this lightweight neural network constructing DBN, we achieved inference with reduced computational cost while maintaining accuracy and uncertainty scores on benchmark datasets such as CIFAR-10, CIFAR-100, and TinyImageNet. Our implementation is available at https://github.com/kim-hyunsu/dbn.
Sequential Data Generation with Groupwise Diffusion Process
Oct 02, 2023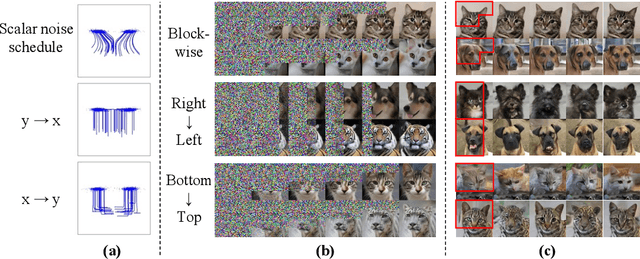



We present the Groupwise Diffusion Model (GDM), which divides data into multiple groups and diffuses one group at one time interval in the forward diffusion process. GDM generates data sequentially from one group at one time interval, leading to several interesting properties. First, as an extension of diffusion models, GDM generalizes certain forms of autoregressive models and cascaded diffusion models. As a unified framework, GDM allows us to investigate design choices that have been overlooked in previous works, such as data-grouping strategy and order of generation. Furthermore, since one group of the initial noise affects only a certain group of the generated data, latent space now possesses group-wise interpretable meaning. We can further extend GDM to the frequency domain where the forward process sequentially diffuses each group of frequency components. Dividing the frequency bands of the data as groups allows the latent variables to become a hierarchical representation where individual groups encode data at different levels of abstraction. We demonstrate several applications of such representation including disentanglement of semantic attributes, image editing, and generating variations.
Probabilistic Imputation for Time-series Classification with Missing Data
Aug 13, 2023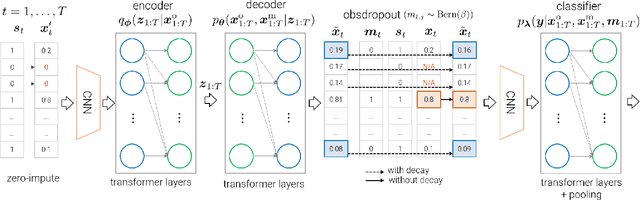
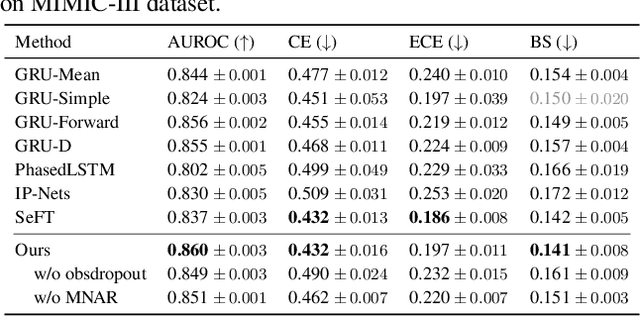
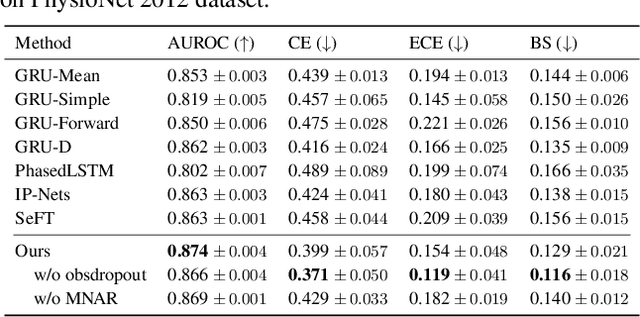
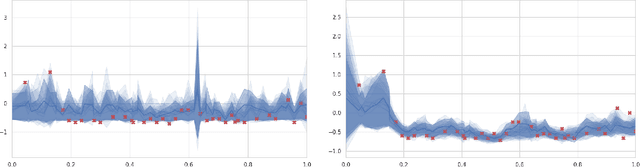
Multivariate time series data for real-world applications typically contain a significant amount of missing values. The dominant approach for classification with such missing values is to impute them heuristically with specific values (zero, mean, values of adjacent time-steps) or learnable parameters. However, these simple strategies do not take the data generative process into account, and more importantly, do not effectively capture the uncertainty in prediction due to the multiple possibilities for the missing values. In this paper, we propose a novel probabilistic framework for classification with multivariate time series data with missing values. Our model consists of two parts; a deep generative model for missing value imputation and a classifier. Extending the existing deep generative models to better capture structures of time-series data, our deep generative model part is trained to impute the missing values in multiple plausible ways, effectively modeling the uncertainty of the imputation. The classifier part takes the time series data along with the imputed missing values and classifies signals, and is trained to capture the predictive uncertainty due to the multiple possibilities of imputations. Importantly, we show that na\"ively combining the generative model and the classifier could result in trivial solutions where the generative model does not produce meaningful imputations. To resolve this, we present a novel regularization technique that can promote the model to produce useful imputation values that help classification. Through extensive experiments on real-world time series data with missing values, we demonstrate the effectiveness of our method.
User-friendly Image Editing with Minimal Text Input: Leveraging Captioning and Injection Techniques
Jun 05, 2023



Recent text-driven image editing in diffusion models has shown remarkable success. However, the existing methods assume that the user's description sufficiently grounds the contexts in the source image, such as objects, background, style, and their relations. This assumption is unsuitable for real-world applications because users have to manually engineer text prompts to find optimal descriptions for different images. From the users' standpoint, prompt engineering is a labor-intensive process, and users prefer to provide a target word for editing instead of a full sentence. To address this problem, we first demonstrate the importance of a detailed text description of the source image, by dividing prompts into three categories based on the level of semantic details. Then, we propose simple yet effective methods by combining prompt generation frameworks, thereby making the prompt engineering process more user-friendly. Extensive qualitative and quantitative experiments demonstrate the importance of prompts in text-driven image editing and our method is comparable to ground-truth prompts.
Regularizing Towards Soft Equivariance Under Mixed Symmetries
Jun 01, 2023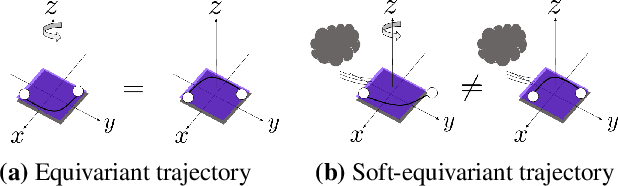

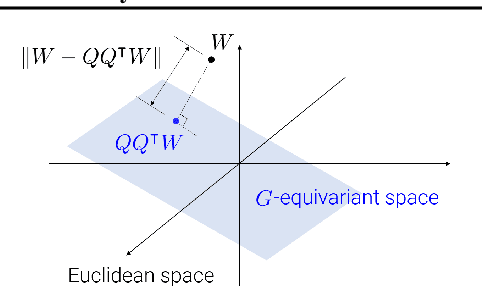

Datasets often have their intrinsic symmetries, and particular deep-learning models called equivariant or invariant models have been developed to exploit these symmetries. However, if some or all of these symmetries are only approximate, which frequently happens in practice, these models may be suboptimal due to the architectural restrictions imposed on them. We tackle this issue of approximate symmetries in a setup where symmetries are mixed, i.e., they are symmetries of not single but multiple different types and the degree of approximation varies across these types. Instead of proposing a new architectural restriction as in most of the previous approaches, we present a regularizer-based method for building a model for a dataset with mixed approximate symmetries. The key component of our method is what we call equivariance regularizer for a given type of symmetries, which measures how much a model is equivariant with respect to the symmetries of the type. Our method is trained with these regularizers, one per each symmetry type, and the strength of the regularizers is automatically tuned during training, leading to the discovery of the approximation levels of some candidate symmetry types without explicit supervision. Using synthetic function approximation and motion forecasting tasks, we demonstrate that our method achieves better accuracy than prior approaches while discovering the approximate symmetry levels correctly.