 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Style Prompting with Swapping Self-Attention
Feb 21, 2024In the evolving domain of text-to-image generation, diffusion models have emerged as powerful tools in content creation. Despite their remarkable capability, existing models still face challenges in achieving controlled generation with a consistent style, requiring costly fine-tuning or often inadequately transferring the visual elements due to content leakage. To address these challenges, we propose a novel approach, \ours, to produce a diverse range of images while maintaining specific style elements and nuances. During the denoising process, we keep the query from original features while swapping the key and value with those from reference features in the late self-attention layers. This approach allows for the visual style prompting without any fine-tuning, ensuring that generated images maintain a faithful style. Through extensive evaluation across various styles and text prompts, our method demonstrates superiority over existing approaches, best reflecting the style of the references and ensuring that resulting images match the text prompts most accurately. Our project page is available https://curryjung.github.io/VisualStylePrompt/.
User-friendly Image Editing with Minimal Text Input: Leveraging Captioning and Injection Techniques
Jun 05, 2023



Recent text-driven image editing in diffusion models has shown remarkable success. However, the existing methods assume that the user's description sufficiently grounds the contexts in the source image, such as objects, background, style, and their relations. This assumption is unsuitable for real-world applications because users have to manually engineer text prompts to find optimal descriptions for different images. From the users' standpoint, prompt engineering is a labor-intensive process, and users prefer to provide a target word for editing instead of a full sentence. To address this problem, we first demonstrate the importance of a detailed text description of the source image, by dividing prompts into three categories based on the level of semantic details. Then, we propose simple yet effective methods by combining prompt generation frameworks, thereby making the prompt engineering process more user-friendly. Extensive qualitative and quantitative experiments demonstrate the importance of prompts in text-driven image editing and our method is comparable to ground-truth prompts.
Custom-Edit: Text-Guided Image Editing with Customized Diffusion Models
May 25, 2023Text-to-image diffusion models can generate diverse, high-fidelity images based on user-provided text prompts. Recent research has extended these models to support text-guided image editing. While text guidance is an intuitive editing interface for users, it often fails to ensure the precise concept conveyed by users. To address this issue, we propose Custom-Edit, in which we (i) customize a diffusion model with a few reference images and then (ii) perform text-guided editing. Our key discovery is that customizing only language-relevant parameters with augmented prompts improves reference similarity significantly while maintaining source similarity. Moreover, we provide our recipe for each customization and editing process. We compare popular customization methods and validate our findings on two editing methods using various datasets.
Learning Input-agnostic Manipulation Directions in StyleGAN with Text Guidance
Feb 26, 2023With the advantages of fast inference and human-friendly flexible manipulation, image-agnostic style manipulation via text guidance enables new applications that were not previously available. The state-of-the-art text-guided image-agnostic manipulation method embeds the representation of each channel of StyleGAN independently in the Contrastive Language-Image Pre-training (CLIP) space, and provides it in the form of a Dictionary to quickly find out the channel-wise manipulation direction during inference time. However, in this paper we argue that this dictionary which is constructed by controlling single channel individually is limited to accommodate the versatility of text guidance since the collective and interactive relation among multiple channels are not considered. Indeed, we show that it fails to discover a large portion of manipulation directions that can be found by existing methods, which manually manipulates latent space without texts. To alleviate this issue, we propose a novel method that learns a Dictionary, whose entry corresponds to the representation of a single channel, by taking into account the manipulation effect coming from the interaction with multiple other channels. We demonstrate that our strategy resolves the inability of previous methods in finding diverse known directions from unsupervised methods and unknown directions from random text while maintaining the real-time inference speed and disentanglement ability.
3D-aware Blending with Generative NeRFs
Feb 13, 2023Image blending aims to combine multiple images seamlessly. It remains challenging for existing 2D-based methods, especially when input images are misaligned due to differences in 3D camera poses and object shapes. To tackle these issues, we propose a 3D-aware blending method using generative Neural Radiance Fields (NeRF), including two key components: 3D-aware alignment and 3D-aware blending. For 3D-aware alignment, we first estimate the camera pose of the reference image with respect to generative NeRFs and then perform 3D local alignment for each part. To further leverage 3D information of the generative NeRF, we propose 3D-aware blending that directly blends images on the NeRF's latent representation space, rather than raw pixel space. Collectively, our method outperforms existing 2D baselines, as validated by extensive quantitative and qualitative evaluations with FFHQ and AFHQ-Cat.
Diffusion Video Autoencoders: Toward Temporally Consistent Face Video Editing via Disentangled Video Encoding
Dec 06, 2022Inspired by the impressive performance of recent face image editing methods, several studies have been naturally proposed to extend these methods to the face video editing task. One of the main challenges here is temporal consistency among edited frames, which is still unresolved. To this end, we propose a novel face video editing framework based on diffusion autoencoders that can successfully extract the decomposed features - for the first time as a face video editing model - of identity and motion from a given video. This modeling allows us to edit the video by simply manipulating the temporally invariant feature to the desired direction for the consistency. Another unique strength of our model is that, since our model is based on diffusion models, it can satisfy both reconstruction and edit capabilities at the same time, and is robust to corner cases in wild face videos (e.g. occluded faces) unlike the existing GAN-based methods.
Generator Knows What Discriminator Should Learn in Unconditional GANs
Jul 27, 2022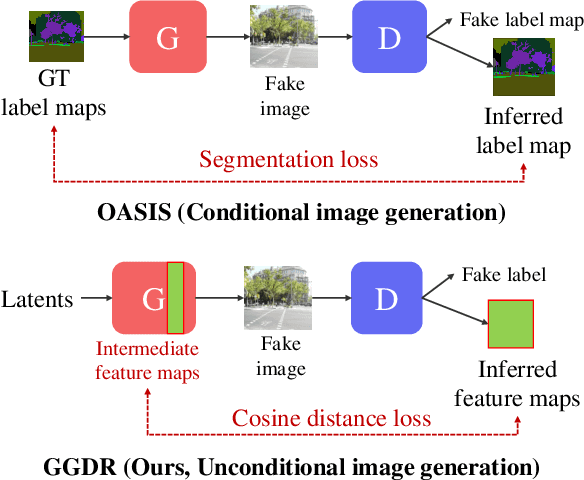
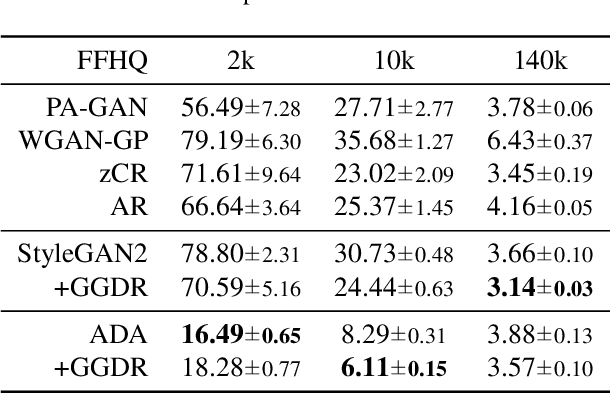
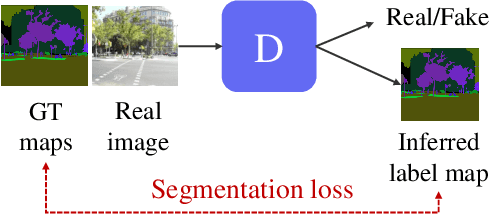
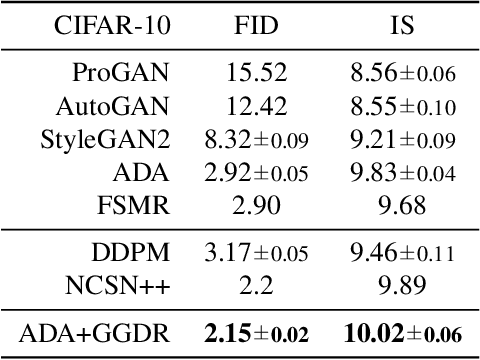
Recent methods for conditional image generation benefit from dense supervision such as segmentation label maps to achieve high-fidelity. However, it is rarely explored to employ dense supervision for unconditional image generation. Here we explore the efficacy of dense supervision in unconditional generation and find generator feature maps can be an alternative of cost-expensive semantic label maps. From our empirical evidences, we propose a new generator-guided discriminator regularization(GGDR) in which the generator feature maps supervise the discriminator to have rich semantic representations in unconditional generation. In specific, we employ an U-Net architecture for discriminator, which is trained to predict the generator feature maps given fake images as inputs. Extensive experiments on mulitple datasets show that our GGDR consistently improves the performance of baseline methods in terms of quantitative and qualitative aspects. Code is available at https://github.com/naver-ai/GGDR
Memory Efficient Patch-based Training for INR-based GANs
Jul 09, 2022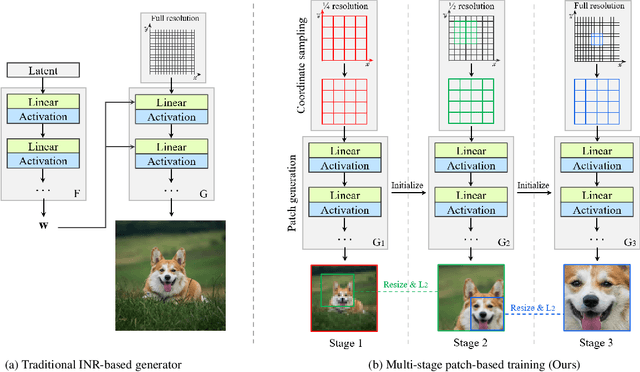
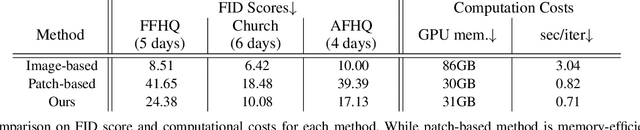


Recent studies have shown remarkable progress in GANs based on implicit neural representation (INR) - an MLP that produces an RGB value given its (x, y) coordinate. They represent an image as a continuous version of the underlying 2D signal instead of a 2D array of pixels, which opens new horizons for GAN applications (e.g., zero-shot super-resolution, image outpainting). However, training existing approaches require a heavy computational cost proportional to the image resolution, since they compute an MLP operation for every (x, y) coordinate. To alleviate this issue, we propose a multi-stage patch-based training, a novel and scalable approach that can train INR-based GANs with a flexible computational cost regardless of the image resolution. Specifically, our method allows to generate and discriminate by patch to learn the local details of the image and learn global structural information by a novel reconstruction loss to enable efficient GAN training. We conduct experiments on several benchmark datasets to demonstrate that our approach enhances baseline models in GPU memory while maintaining FIDs at a reasonable level.
Rarity Score : A New Metric to Evaluate the Uncommonness of Synthesized Images
Jun 26, 2022
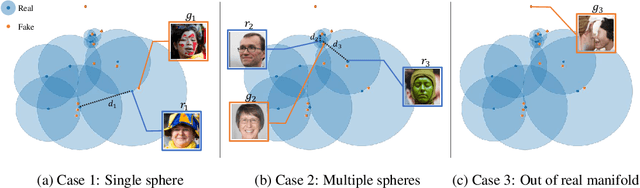
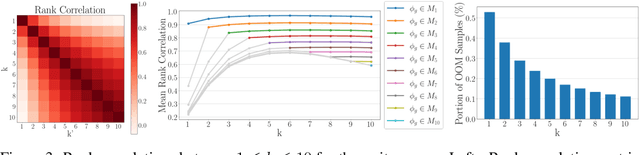

Evaluation metrics in image synthesis play a key role to measure performances of generative models. However, most metrics mainly focus on image fidelity. Existing diversity metrics are derived by comparing distributions, and thus they cannot quantify the diversity or rarity degree of each generated image. In this work, we propose a new evaluation metric, called `rarity score', to measure the individual rarity of each image synthesized by generative models. We first show empirical observation that common samples are close to each other and rare samples are far from each other in nearest-neighbor distances of feature space. We then use our metric to demonstrate that the extent to which different generative models produce rare images can be effectively compared. We also propose a method to compare rarities between datasets that share the same concept such as CelebA-HQ and FFHQ. Finally, we analyze the use of metrics in different designs of feature spaces to better understand the relationship between feature spaces and resulting sparse images. Code will be publicly available online for the research community.
Feature Statistics Mixing Regularization for Generative Adversarial Networks
Dec 08, 2021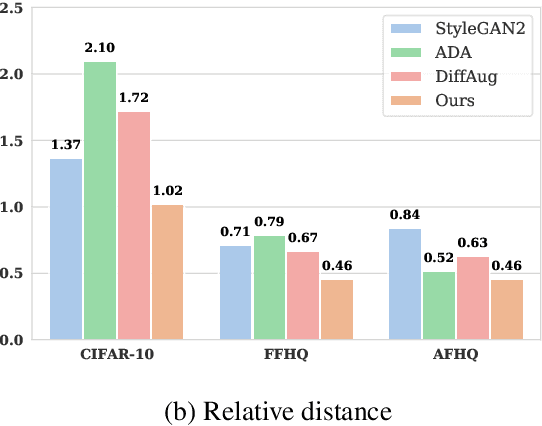
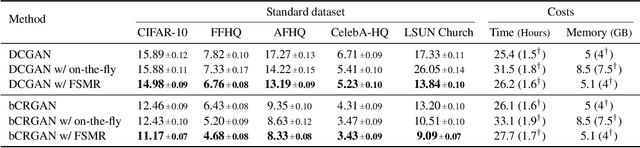
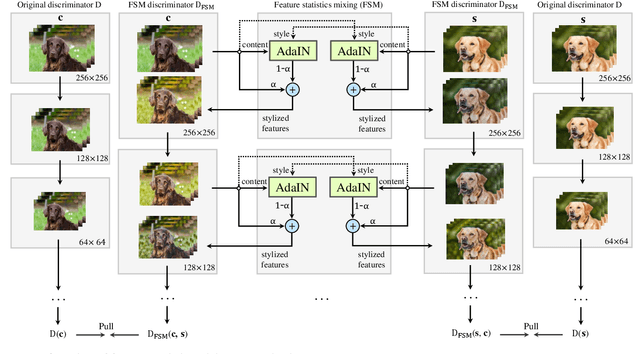

In generative adversarial networks, improving discriminators is one of the key components for generation performance. As image classifiers are biased toward texture and debiasing improves accuracy, we investigate 1) if the discriminators are biased, and 2) if debiasing the discriminators will improve generation performance. Indeed, we find empirical evidence that the discriminators are sensitive to the style (\e.g., texture and color) of images. As a remedy, we propose feature statistics mixing regularization (FSMR) that encourages the discriminator's prediction to be invariant to the styles of input images. Specifically, we generate a mixed feature of an original and a reference image in the discriminator's feature space and we apply regularization so that the prediction for the mixed feature is consistent with the prediction for the original image. We conduct extensive experiments to demonstrate that our regularization leads to reduced sensitivity to style and consistently improves the performance of various GAN architectures on nine datasets. In addition, adding FSMR to recently-proposed augmentation-based GAN methods further improves image quality. Code will be publicly available online for the research community.