 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCloudFixer: Test-Time Adaptation for 3D Point Clouds via Diffusion-Guided Geometric Transformation
Jul 23, 2024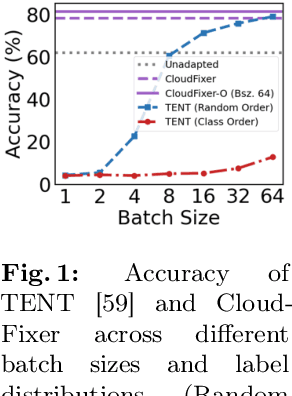
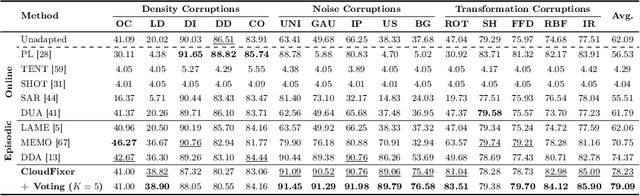
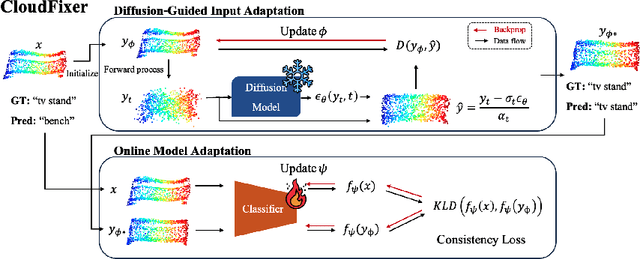
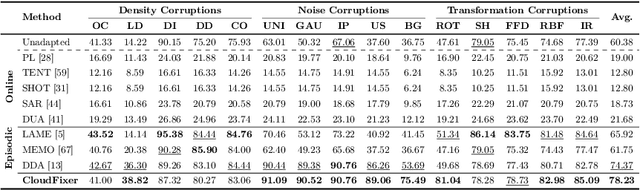
3D point clouds captured from real-world sensors frequently encompass noisy points due to various obstacles, such as occlusion, limited resolution, and variations in scale. These challenges hinder the deployment of pre-trained point cloud recognition models trained on clean point clouds, leading to significant performance degradation. While test-time adaptation (TTA) strategies have shown promising results on this issue in the 2D domain, their application to 3D point clouds remains under-explored. Among TTA methods, an input adaptation approach, which directly converts test instances to the source domain using a pre-trained diffusion model, has been proposed in the 2D domain. Despite its robust TTA performance in practical situations, naively adopting this into the 3D domain may be suboptimal due to the neglect of inherent properties of point clouds, and its prohibitive computational cost. Motivated by these limitations, we propose CloudFixer, a test-time input adaptation method tailored for 3D point clouds, employing a pre-trained diffusion model. Specifically, CloudFixer optimizes geometric transformation parameters with carefully designed objectives that leverage the geometric properties of point clouds. We also substantially improve computational efficiency by avoiding backpropagation through the diffusion model and a prohibitive generation process. Furthermore, we propose an online model adaptation strategy by aligning the original model prediction with that of the adapted input. Extensive experiments showcase the superiority of CloudFixer over various TTA baselines, excelling in handling common corruptions and natural distribution shifts across diverse real-world scenarios. Our code is available at https://github.com/shimazing/CloudFixer
SGEM: Test-Time Adaptation for Automatic Speech Recognition via Sequential-Level Generalized Entropy Minimization
Jun 21, 2023Automatic speech recognition (ASR) models are frequently exposed to data distribution shifts in many real-world scenarios, leading to erroneous predictions. To tackle this issue, an existing test-time adaptation (TTA) method has recently been proposed to adapt the pre-trained ASR model on unlabeled test instances without source data. Despite decent performance gain, this work relies solely on naive greedy decoding and performs adaptation across timesteps at a frame level, which may not be optimal given the sequential nature of the model output. Motivated by this, we propose a novel TTA framework, dubbed SGEM, for general ASR models. To treat the sequential output, SGEM first exploits beam search to explore candidate output logits and selects the most plausible one. Then, it utilizes generalized entropy minimization and negative sampling as unsupervised objectives to adapt the model. SGEM achieves state-of-the-art performance for three mainstream ASR models under various domain shifts.
Diffusion Video Autoencoders: Toward Temporally Consistent Face Video Editing via Disentangled Video Encoding
Dec 06, 2022Inspired by the impressive performance of recent face image editing methods, several studies have been naturally proposed to extend these methods to the face video editing task. One of the main challenges here is temporal consistency among edited frames, which is still unresolved. To this end, we propose a novel face video editing framework based on diffusion autoencoders that can successfully extract the decomposed features - for the first time as a face video editing model - of identity and motion from a given video. This modeling allows us to edit the video by simply manipulating the temporally invariant feature to the desired direction for the consistency. Another unique strength of our model is that, since our model is based on diffusion models, it can satisfy both reconstruction and edit capabilities at the same time, and is robust to corner cases in wild face videos (e.g. occluded faces) unlike the existing GAN-based methods.
Fighting Fire with Fire: Contrastive Debiasing without Bias-free Data via Generative Bias-transformation
Dec 02, 2021

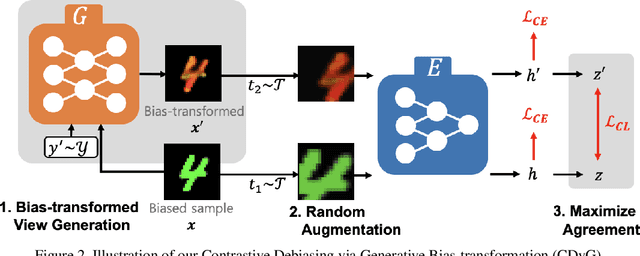
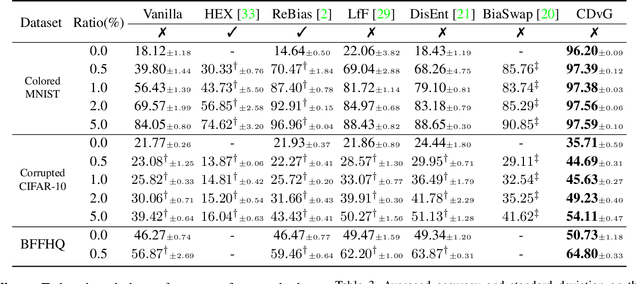
Despite their remarkable ability to generalize with over-capacity networks, deep neural networks often learn to abuse spurious biases in the data instead of using the actual task-related information. Since such shortcuts are only effective within the collected dataset, the resulting biased model underperforms on real-world inputs, or cause unintended social repercussions such as gender discrimination. To counteract the influence of bias, existing methods either exploit auxiliary information which is rarely obtainable in practice, or sift for bias-free samples in the training data, hoping for the sufficient existence of clean samples. However, such presumptions about the data are not always guaranteed. In this paper, we propose Contrastive Debiasing via Generative Bias-transformation~(CDvG) which is capable of operating in more general environments where existing methods break down due to unmet presumptions such as insufficient bias-free samples. Motivated by our observation that not only discriminative models, as previously known, but also generative models tend to focus on the bias when possible, CDvG uses a translation model to transform the bias in the sample to another mode of bias while preserving task-relevant information. Through contrastive learning, we set transformed biased views against another, learning bias-invariant representations. Experimental results on synthetic and real-world datasets demonstrate that our framework outperforms the current state-of-the-arts, and effectively prevents the models from being biased even when bias-free samples are extremely scarce.
Graph Transplant: Node Saliency-Guided Graph Mixup with Local Structure Preservation
Nov 10, 2021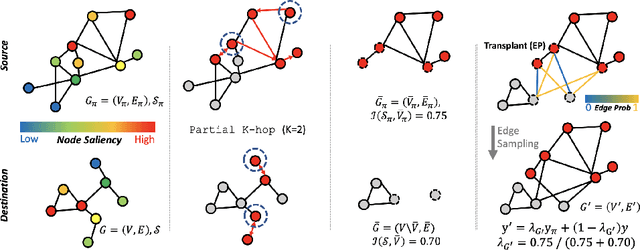
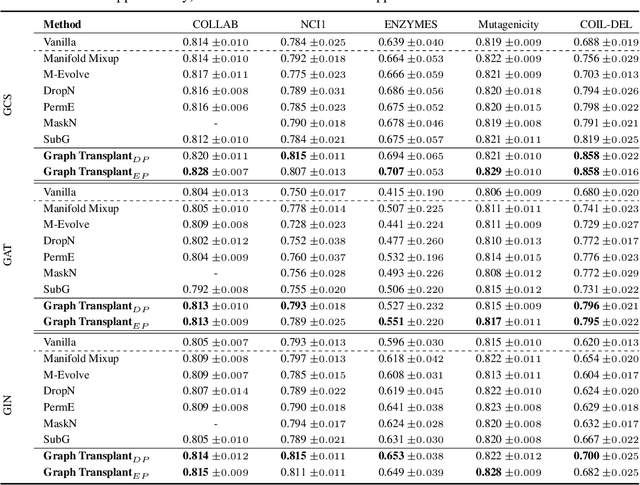
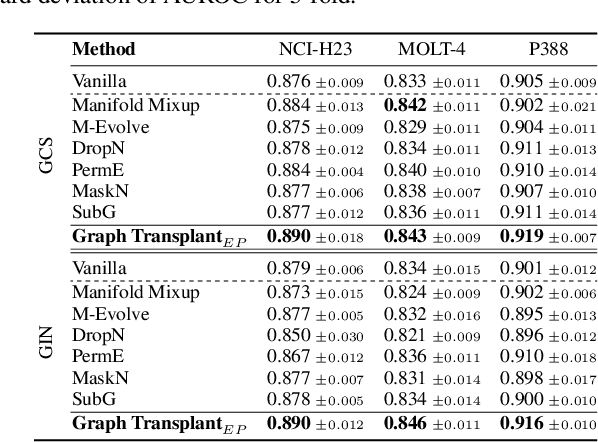
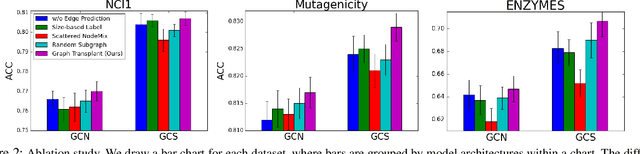
Graph-structured datasets usually have irregular graph sizes and connectivities, rendering the use of recent data augmentation techniques, such as Mixup, difficult. To tackle this challenge, we present the first Mixup-like graph augmentation method at the graph-level called Graph Transplant, which mixes irregular graphs in data space. To be well defined on various scales of the graph, our method identifies the sub-structure as a mix unit that can preserve the local information. Since the mixup-based methods without special consideration of the context are prone to generate noisy samples, our method explicitly employs the node saliency information to select meaningful subgraphs and adaptively determine the labels. We extensively validate our method with diverse GNN architectures on multiple graph classification benchmark datasets from a wide range of graph domains of different sizes. Experimental results show the consistent superiority of our method over other basic data augmentation baselines. We also demonstrate that Graph Transplant enhances the performance in terms of robustness and model calibration.
Mutually-Constrained Monotonic Multihead Attention for Online ASR
Mar 26, 2021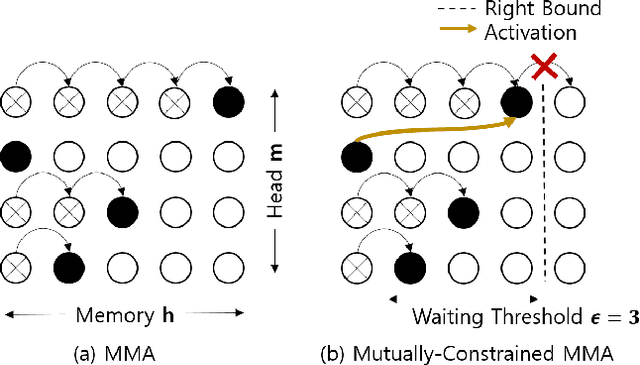
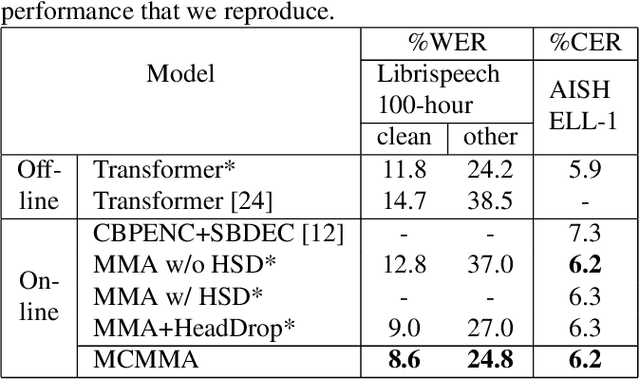
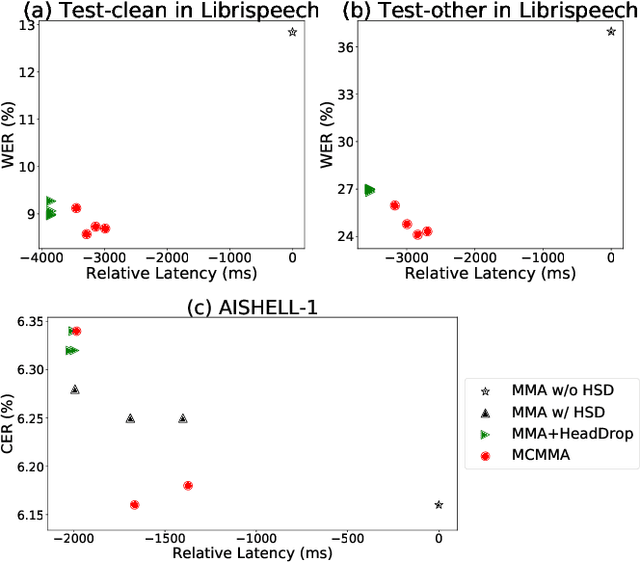
Despite the feature of real-time decoding, Monotonic Multihead Attention (MMA) shows comparable performance to the state-of-the-art offline methods in machine translation and automatic speech recognition (ASR) tasks. However, the latency of MMA is still a major issue in ASR and should be combined with a technique that can reduce the test latency at inference time, such as head-synchronous beam search decoding, which forces all non-activated heads to activate after a small fixed delay from the first head activation. In this paper, we remove the discrepancy between training and test phases by considering, in the training of MMA, the interactions across multiple heads that will occur in the test time. Specifically, we derive the expected alignments from monotonic attention by considering the boundaries of other heads and reflect them in the learning process. We validate our proposed method on the two standard benchmark datasets for ASR and show that our approach, MMA with the mutually-constrained heads from the training stage, provides better performance than baselines.
Why Pay More When You Can Pay Less: A Joint Learning Framework for Active Feature Acquisition and Classification
Sep 18, 2017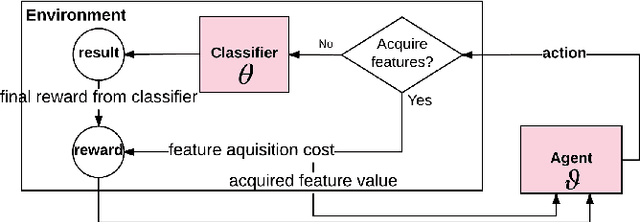

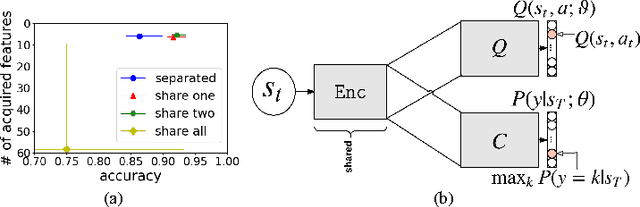
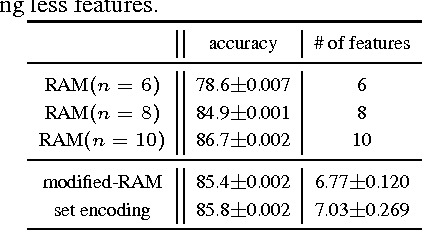
We consider the problem of active feature acquisition, where we sequentially select the subset of features in order to achieve the maximum prediction performance in the most cost-effective way. In this work, we formulate this active feature acquisition problem as a reinforcement learning problem, and provide a novel framework for jointly learning both the RL agent and the classifier (environment). We also introduce a more systematic way of encoding subsets of features that can properly handle innate challenge with missing entries in active feature acquisition problems, that uses the orderless LSTM-based set encoding mechanism that readily fits in the joint learning framework. We evaluate our model on a carefully designed synthetic dataset for the active feature acquisition as well as several real datasets such as electric health record (EHR) datasets, on which it outperforms all baselines in terms of prediction performance as well feature acquisition cost.