 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRIAGE: Dialectical Reasoning for Explainable Risk Prediction on Irregularly Sampled Medical Time Series with LLMs
Jun 08, 2026Clinical early warning systems built on electronic health records, in which clinical observations are recorded as irregularly sampled medical time series (ISMTS), must deliver both calibrated risk scores for patient triage and interpretable rationales that clinicians can verify. Large Language Models (LLMs) have been explored for this task, yet they collapse graded clinical risk into overconfident binary predictions. This risk polarization undermines both calibration and cross-patient comparability. To address this, we propose TRIAGE, a framework that trains an LLM to generate dialectical reasoning over competing clinical outcomes by eliciting outcome-specific rationales. This dialectical formulation mitigates risk polarization, enabling a single LLM to yield continuous risk scores grounded in explicit clinical reasoning. Evaluated on three ISMTS benchmarks, TRIAGE achieves an average AUPRC improvement of 3.3% and reduces calibration error by 81% compared to the competitive baselines. An LLM-as-a-judge assessment further shows that our rationales surpass post-hoc explanations from the baseline by 20% in clinical reasoning quality. The source code is available at https://github.com/HyeongWon-Jang/TRIAGE .
DRetHTR: Linear-Time Decoder-Only Retentive Network for Handwritten Text Recognition
Feb 19, 2026State-of-the-art handwritten text recognition (HTR) systems commonly use Transformers, whose growing key-value (KV) cache makes decoding slow and memory-intensive. We introduce DRetHTR, a decoder-only model built on Retentive Networks (RetNet). Compared to an equally sized decoder-only Transformer baseline, DRetHTR delivers 1.6-1.9x faster inference with 38-42% less memory usage, without loss of accuracy. By replacing softmax attention with softmax-free retention and injecting multi-scale sequential priors, DRetHTR avoids a growing KV cache: decoding is linear in output length in both time and memory. To recover the local-to-global inductive bias of attention, we propose layer-wise gamma scaling, which progressively enlarges the effective retention horizon in deeper layers. This encourages early layers to model short-range dependencies and later layers to capture broader context, mitigating the flexibility gap introduced by removing softmax. Consequently, DRetHTR achieves best reported test character error rates of 2.26% (IAM-A, en), 1.81% (RIMES, fr), and 3.46% (Bentham, en), and is competitive on READ-2016 (de) with 4.21%. This demonstrates that decoder-only RetNet enables Transformer-level HTR accuracy with substantially improved decoding speed and memory efficiency.
Physics-informed GNN for medium-high voltage AC power flow with edge-aware attention and line search correction operator
Sep 26, 2025Physics-informed graph neural networks (PIGNNs) have emerged as fast AC power-flow solvers that can replace classic Newton--Raphson (NR) solvers, especially when thousands of scenarios must be evaluated. However, current PIGNNs still need accuracy improvements at parity speed; in particular, the physics loss is inoperative at inference, which can deter operational adoption. We address this with PIGNN-Attn-LS, combining an edge-aware attention mechanism that explicitly encodes line physics via per-edge biases, capturing the grid's anisotropy, with a backtracking line-search-based globalized correction operator that restores an operative decrease criterion at inference. Training and testing use a realistic High-/Medium-Voltage scenario generator, with NR used only to construct reference states. On held-out HV cases consisting of 4--32-bus grids, PIGNN-Attn-LS achieves a test RMSE of 0.00033 p.u. in voltage and 0.08$^\circ$ in angle, outperforming the PIGNN-MLP baseline by 99.5\% and 87.1\%, respectively. With streaming micro-batches, it delivers 2--5$\times$ faster batched inference than NR on 4--1024-bus grids.
DeltaSHAP: Explaining Prediction Evolutions in Online Patient Monitoring with Shapley Values
Jul 03, 2025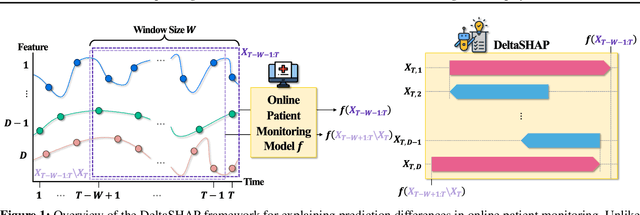
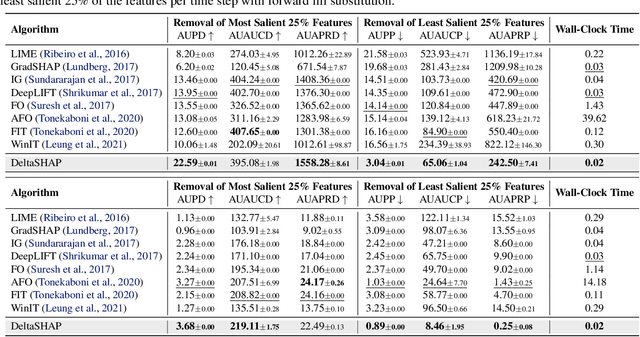
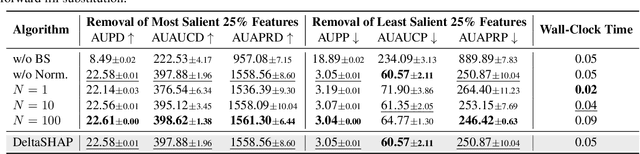
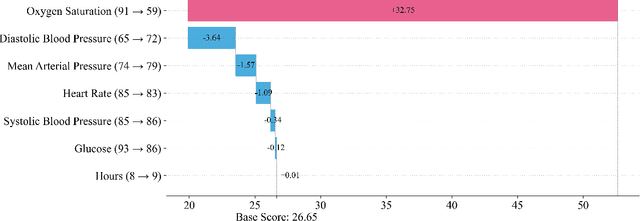
This study proposes DeltaSHAP, a novel explainable artificial intelligence (XAI) algorithm specifically designed for online patient monitoring systems. In clinical environments, discovering the causes driving patient risk evolution is critical for timely intervention, yet existing XAI methods fail to address the unique requirements of clinical time series explanation tasks. To this end, DeltaSHAP addresses three key clinical needs: explaining the changes in the consecutive predictions rather than isolated prediction scores, providing both magnitude and direction of feature attributions, and delivering these insights in real time. By adapting Shapley values to temporal settings, our approach accurately captures feature coalition effects. It further attributes prediction changes using only the actually observed feature combinations, making it efficient and practical for time-sensitive clinical applications. We also introduce new evaluation metrics to evaluate the faithfulness of the attributions for online time series, and demonstrate through experiments on online patient monitoring tasks that DeltaSHAP outperforms state-of-the-art XAI methods in both explanation quality as 62% and computational efficiency as 33% time reduction on the MIMIC-III decompensation benchmark. We release our code at https://github.com/AITRICS/DeltaSHAP.
TIMING: Temporality-Aware Integrated Gradients for Time Series Explanation
Jun 05, 2025Recent explainable artificial intelligence (XAI) methods for time series primarily estimate point-wise attribution magnitudes, while overlooking the directional impact on predictions, leading to suboptimal identification of significant points. Our analysis shows that conventional Integrated Gradients (IG) effectively capture critical points with both positive and negative impacts on predictions. However, current evaluation metrics fail to assess this capability, as they inadvertently cancel out opposing feature contributions. To address this limitation, we propose novel evaluation metrics-Cumulative Prediction Difference (CPD) and Cumulative Prediction Preservation (CPP)-to systematically assess whether attribution methods accurately identify significant positive and negative points in time series XAI. Under these metrics, conventional IG outperforms recent counterparts. However, directly applying IG to time series data may lead to suboptimal outcomes, as generated paths ignore temporal relationships and introduce out-of-distribution samples. To overcome these challenges, we introduce TIMING, which enhances IG by incorporating temporal awareness while maintaining its theoretical properties. Extensive experiments on synthetic and real-world time series benchmarks demonstrate that TIMING outperforms existing time series XAI baselines. Our code is available at https://github.com/drumpt/TIMING.
Impact of Data Sparsity on Machine Learning for Fault Detection in Power System Protection
May 21, 2025Germany's transition to a renewable energy-based power system is reshaping grid operations, requiring advanced monitoring and control to manage decentralized generation. Machine learning (ML) has emerged as a powerful tool for power system protection, particularly for fault detection (FD) and fault line identification (FLI) in transmission grids. However, ML model reliability depends on data quality and availability. Data sparsity resulting from sensor failures, communication disruptions, or reduced sampling rates poses a challenge to ML-based FD and FLI. Yet, its impact has not been systematically validated prior to this work. In response, we propose a framework to assess the impact of data sparsity on ML-based FD and FLI performance. We simulate realistic data sparsity scenarios, evaluate their impact, derive quantitative insights, and demonstrate the effectiveness of this evaluation strategy by applying it to an existing ML-based framework. Results show the ML model remains robust for FD, maintaining an F1-score of 0.999 $\pm$ 0.000 even after a 50x data reduction. In contrast, FLI is more sensitive, with performance decreasing by 55.61% for missing voltage measurements and 9.73% due to communication failures at critical network points. These findings offer actionable insights for optimizing ML models for real-world grid protection. This enables more efficient FD and supports targeted improvements in FLI.
Stable-TTS: Stable Speaker-Adaptive Text-to-Speech Synthesis via Prosody Prompting
Dec 28, 2024



Speaker-adaptive Text-to-Speech (TTS) synthesis has attracted considerable attention due to its broad range of applications, such as personalized voice assistant services. While several approaches have been proposed, they often exhibit high sensitivity to either the quantity or the quality of target speech samples. To address these limitations, we introduce Stable-TTS, a novel speaker-adaptive TTS framework that leverages a small subset of a high-quality pre-training dataset, referred to as prior samples. Specifically, Stable-TTS achieves prosody consistency by leveraging the high-quality prosody of prior samples, while effectively capturing the timbre of the target speaker. Additionally, it employs a prior-preservation loss during fine-tuning to maintain the synthesis ability for prior samples to prevent overfitting on target samples. Extensive experiments demonstrate the effectiveness of Stable-TTS even under limited amounts of and noisy target speech samples.
CloudFixer: Test-Time Adaptation for 3D Point Clouds via Diffusion-Guided Geometric Transformation
Jul 23, 2024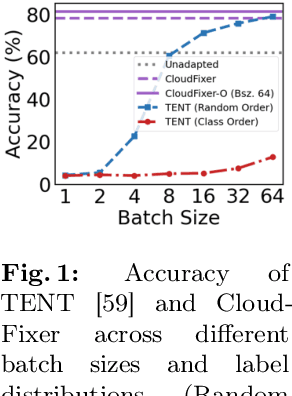
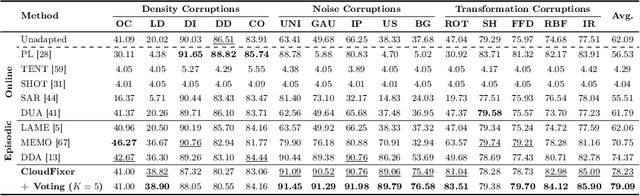
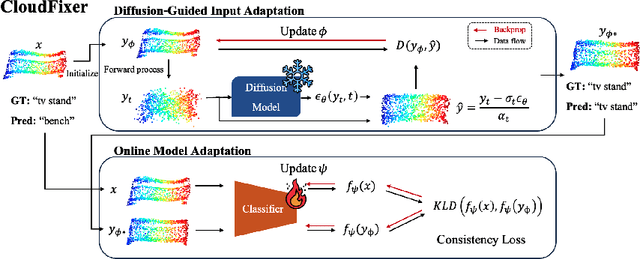
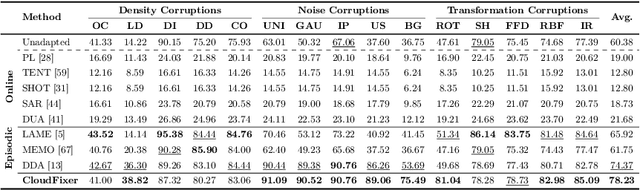
3D point clouds captured from real-world sensors frequently encompass noisy points due to various obstacles, such as occlusion, limited resolution, and variations in scale. These challenges hinder the deployment of pre-trained point cloud recognition models trained on clean point clouds, leading to significant performance degradation. While test-time adaptation (TTA) strategies have shown promising results on this issue in the 2D domain, their application to 3D point clouds remains under-explored. Among TTA methods, an input adaptation approach, which directly converts test instances to the source domain using a pre-trained diffusion model, has been proposed in the 2D domain. Despite its robust TTA performance in practical situations, naively adopting this into the 3D domain may be suboptimal due to the neglect of inherent properties of point clouds, and its prohibitive computational cost. Motivated by these limitations, we propose CloudFixer, a test-time input adaptation method tailored for 3D point clouds, employing a pre-trained diffusion model. Specifically, CloudFixer optimizes geometric transformation parameters with carefully designed objectives that leverage the geometric properties of point clouds. We also substantially improve computational efficiency by avoiding backpropagation through the diffusion model and a prohibitive generation process. Furthermore, we propose an online model adaptation strategy by aligning the original model prediction with that of the adapted input. Extensive experiments showcase the superiority of CloudFixer over various TTA baselines, excelling in handling common corruptions and natural distribution shifts across diverse real-world scenarios. Our code is available at https://github.com/shimazing/CloudFixer
AdapTable: Test-Time Adaptation for Tabular Data via Shift-Aware Uncertainty Calibrator and Label Distribution Handler
Jul 15, 2024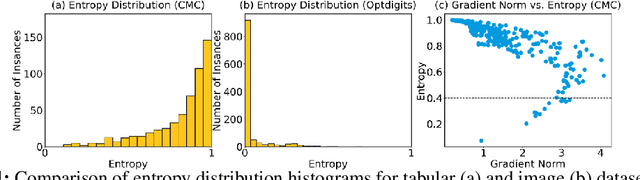
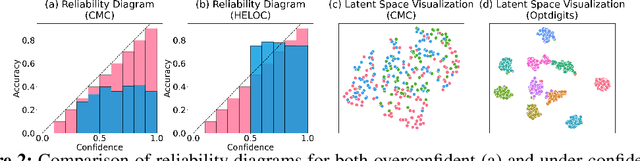
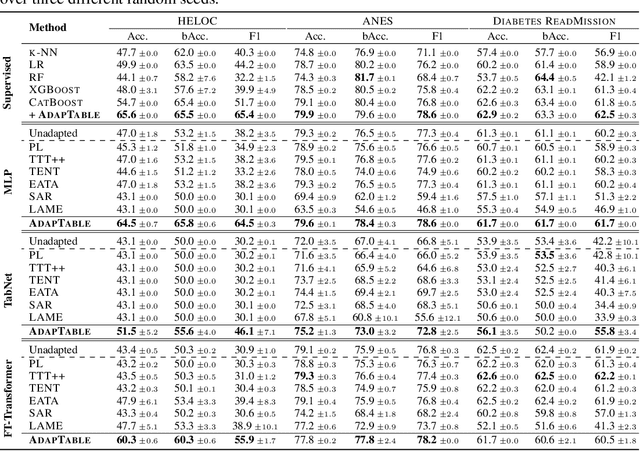
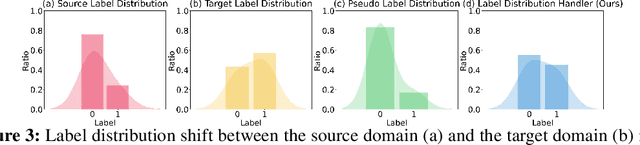
In real-world applications, tabular data often suffer from distribution shifts due to their widespread and abundant nature, leading to erroneous predictions of pre-trained machine learning models. However, addressing such distribution shifts in the tabular domain has been relatively underexplored due to unique challenges such as varying attributes and dataset sizes, as well as the limited representation learning capabilities of deep learning models for tabular data. Particularly, with the recent promising paradigm of test-time adaptation (TTA), where we adapt the off-the-shelf model to the unlabeled target domain during the inference phase without accessing the source domain, we observe that directly adopting commonly used TTA methods from other domains often leads to model collapse. We systematically explore challenges in tabular data test-time adaptation, including skewed entropy, complex latent space decision boundaries, confidence calibration issues with both overconfident and under-confident, and model bias towards source label distributions along with class imbalances. Based on these insights, we introduce AdapTable, a novel tabular test-time adaptation method that directly modifies output probabilities by estimating target label distributions and adjusting initial probabilities based on calibrated uncertainty. Extensive experiments on both natural distribution shifts and synthetic corruptions demonstrate the adaptation efficacy of the proposed method.
SGEM: Test-Time Adaptation for Automatic Speech Recognition via Sequential-Level Generalized Entropy Minimization
Jun 21, 2023Automatic speech recognition (ASR) models are frequently exposed to data distribution shifts in many real-world scenarios, leading to erroneous predictions. To tackle this issue, an existing test-time adaptation (TTA) method has recently been proposed to adapt the pre-trained ASR model on unlabeled test instances without source data. Despite decent performance gain, this work relies solely on naive greedy decoding and performs adaptation across timesteps at a frame level, which may not be optimal given the sequential nature of the model output. Motivated by this, we propose a novel TTA framework, dubbed SGEM, for general ASR models. To treat the sequential output, SGEM first exploits beam search to explore candidate output logits and selects the most plausible one. Then, it utilizes generalized entropy minimization and negative sampling as unsupervised objectives to adapt the model. SGEM achieves state-of-the-art performance for three mainstream ASR models under various domain shifts.