 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Pre-Consultation Ability of LLMs using Diagnostic Guidelines
Jan 08, 2026We introduce EPAG, a benchmark dataset and framework designed for Evaluating the Pre-consultation Ability of LLMs using diagnostic Guidelines. LLMs are evaluated directly through HPI-diagnostic guideline comparison and indirectly through disease diagnosis. In our experiments, we observe that small open-source models fine-tuned with a well-curated, task-specific dataset can outperform frontier LLMs in pre-consultation. Additionally, we find that increased amount of HPI (History of Present Illness) does not necessarily lead to improved diagnostic performance. Further experiments reveal that the language of pre-consultation influences the characteristics of the dialogue. By open-sourcing our dataset and evaluation pipeline on https://github.com/seemdog/EPAG, we aim to contribute to the evaluation and further development of LLM applications in real-world clinical settings.
On the Collapse of Generative Paths: A Criterion and Correction for Diffusion Steering
Dec 11, 2025Inference-time steering enables pretrained diffusion/flow models to be adapted to new tasks without retraining. A widely used approach is the ratio-of-densities method, which defines a time-indexed target path by reweighting probability-density trajectories from multiple models with positive, or in some cases, negative exponents. This construction, however, harbors a critical and previously unformalized failure mode: Marginal Path Collapse, where intermediate densities become non-normalizable even though endpoints remain valid. Collapse arises systematically when composing heterogeneous models trained on different noise schedules or datasets, including a common setting in molecular design where de-novo, conformer, and pocket-conditioned models must be combined for tasks such as flexible-pose scaffold decoration. We provide a novel and complete solution for the problem. First, we derive a simple path existence criterion that predicts exactly when collapse occurs from noise schedules and exponents alone. Second, we introduce Adaptive path Correction with Exponents (ACE), which extends Feynman-Kac steering to time-varying exponents and guarantees a valid probability path. On a synthetic 2D benchmark and on flexible-pose scaffold decoration, ACE eliminates collapse and enables high-guidance compositional generation, improving distributional and docking metrics over constant-exponent baselines and even specialized task-specific scaffold decoration models. Our work turns ratio-of-densities steering with heterogeneous experts from an unstable heuristic into a reliable tool for controllable generation.
Towards Reliable Test-Time Adaptation: Style Invariance as a Correctness Likelihood
Dec 08, 2025Test-time adaptation (TTA) enables efficient adaptation of deployed models, yet it often leads to poorly calibrated predictive uncertainty - a critical issue in high-stakes domains such as autonomous driving, finance, and healthcare. Existing calibration methods typically assume fixed models or static distributions, resulting in degraded performance under real-world, dynamic test conditions. To address these challenges, we introduce Style Invariance as a Correctness Likelihood (SICL), a framework that leverages style-invariance for robust uncertainty estimation. SICL estimates instance-wise correctness likelihood by measuring prediction consistency across style-altered variants, requiring only the model's forward pass. This makes it a plug-and-play, backpropagation-free calibration module compatible with any TTA method. Comprehensive evaluations across four baselines, five TTA methods, and two realistic scenarios with three model architecture demonstrate that SICL reduces calibration error by an average of 13 percentage points compared to conventional calibration approaches.
Instruction-Guided Lesion Segmentation for Chest X-rays with Automatically Generated Large-Scale Dataset
Nov 19, 2025The applicability of current lesion segmentation models for chest X-rays (CXRs) has been limited both by a small number of target labels and the reliance on long, detailed expert-level text inputs, creating a barrier to practical use. To address these limitations, we introduce a new paradigm: instruction-guided lesion segmentation (ILS), which is designed to segment diverse lesion types based on simple, user-friendly instructions. Under this paradigm, we construct MIMIC-ILS, the first large-scale instruction-answer dataset for CXR lesion segmentation, using our fully automated multimodal pipeline that generates annotations from chest X-ray images and their corresponding reports. MIMIC-ILS contains 1.1M instruction-answer pairs derived from 192K images and 91K unique segmentation masks, covering seven major lesion types. To empirically demonstrate its utility, we introduce ROSALIA, a vision-language model fine-tuned on MIMIC-ILS. ROSALIA can segment diverse lesions and provide textual explanations in response to user instructions. The model achieves high segmentation and textual accuracy in our newly proposed task, highlighting the effectiveness of our pipeline and the value of MIMIC-ILS as a foundational resource for pixel-level CXR lesion grounding.
EMR-AGENT: Automating Cohort and Feature Extraction from EMR Databases
Oct 02, 2025Machine learning models for clinical prediction rely on structured data extracted from Electronic Medical Records (EMRs), yet this process remains dominated by hardcoded, database-specific pipelines for cohort definition, feature selection, and code mapping. These manual efforts limit scalability, reproducibility, and cross-institutional generalization. To address this, we introduce EMR-AGENT (Automated Generalized Extraction and Navigation Tool), an agent-based framework that replaces manual rule writing with dynamic, language model-driven interaction to extract and standardize structured clinical data. Our framework automates cohort selection, feature extraction, and code mapping through interactive querying of databases. Our modular agents iteratively observe query results and reason over schema and documentation, using SQL not just for data retrieval but also as a tool for database observation and decision making. This eliminates the need for hand-crafted, schema-specific logic. To enable rigorous evaluation, we develop a benchmarking codebase for three EMR databases (MIMIC-III, eICU, SICdb), including both seen and unseen schema settings. Our results demonstrate strong performance and generalization across these databases, highlighting the feasibility of automating a process previously thought to require expert-driven design. The code will be released publicly at https://github.com/AITRICS/EMR-AGENT/tree/main. For a demonstration, please visit our anonymous demo page: https://anonymoususer-max600.github.io/EMR_AGENT/
Format Inertia: A Failure Mechanism of LLMs in Medical Pre-Consultation
Oct 02, 2025Recent advances in Large Language Models (LLMs) have brought significant improvements to various service domains, including chatbots and medical pre-consultation applications. In the healthcare domain, the most common approach for adapting LLMs to multi-turn dialogue generation is Supervised Fine-Tuning (SFT). However, datasets for SFT in tasks like medical pre-consultation typically exhibit a skewed turn-count distribution. Training on such data induces a novel failure mechanism we term **Format Inertia**, where models tend to generate repetitive, format-correct, but diagnostically uninformative questions in long medical dialogues. To mitigate this observed failure mechanism, we adopt a simple, data-centric method that rebalances the turn-count distribution of the training dataset. Experimental results show that our approach substantially alleviates Format Inertia in medical pre-consultation.
Taxonomy of Comprehensive Safety for Clinical Agents
Sep 26, 2025Safety is a paramount concern in clinical chatbot applications, where inaccurate or harmful responses can lead to serious consequences. Existing methods--such as guardrails and tool calling--often fall short in addressing the nuanced demands of the clinical domain. In this paper, we introduce TACOS (TAxonomy of COmprehensive Safety for Clinical Agents), a fine-grained, 21-class taxonomy that integrates safety filtering and tool selection into a single user intent classification step. TACOS is a taxonomy that can cover a wide spectrum of clinical and non-clinical queries, explicitly modeling varying safety thresholds and external tool dependencies. To validate our framework, we curate a TACOS-annotated dataset and perform extensive experiments. Our results demonstrate the value of a new taxonomy specialized for clinical agent settings, and reveal useful insights about train data distribution and pretrained knowledge of base models.
DeltaSHAP: Explaining Prediction Evolutions in Online Patient Monitoring with Shapley Values
Jul 03, 2025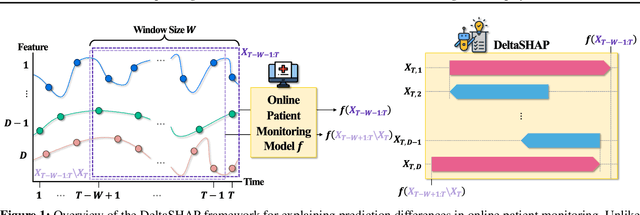
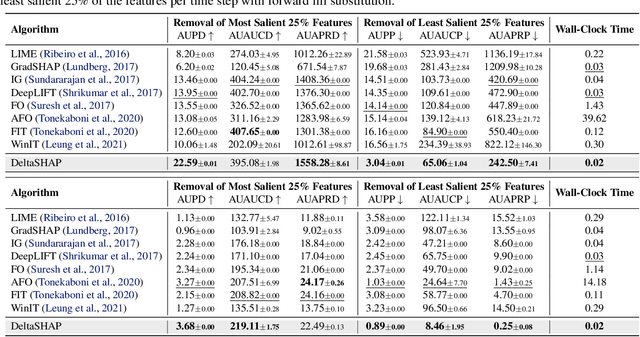
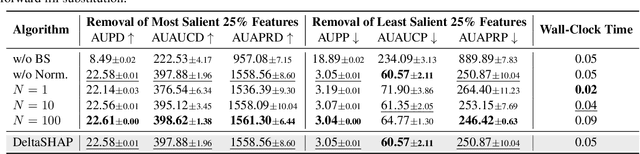
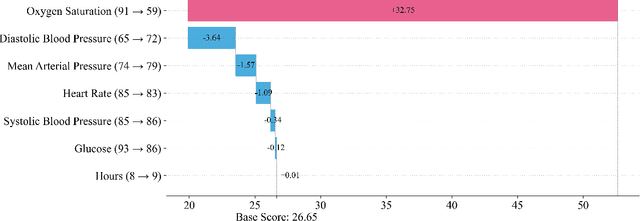
This study proposes DeltaSHAP, a novel explainable artificial intelligence (XAI) algorithm specifically designed for online patient monitoring systems. In clinical environments, discovering the causes driving patient risk evolution is critical for timely intervention, yet existing XAI methods fail to address the unique requirements of clinical time series explanation tasks. To this end, DeltaSHAP addresses three key clinical needs: explaining the changes in the consecutive predictions rather than isolated prediction scores, providing both magnitude and direction of feature attributions, and delivering these insights in real time. By adapting Shapley values to temporal settings, our approach accurately captures feature coalition effects. It further attributes prediction changes using only the actually observed feature combinations, making it efficient and practical for time-sensitive clinical applications. We also introduce new evaluation metrics to evaluate the faithfulness of the attributions for online time series, and demonstrate through experiments on online patient monitoring tasks that DeltaSHAP outperforms state-of-the-art XAI methods in both explanation quality as 62% and computational efficiency as 33% time reduction on the MIMIC-III decompensation benchmark. We release our code at https://github.com/AITRICS/DeltaSHAP.
TIMING: Temporality-Aware Integrated Gradients for Time Series Explanation
Jun 05, 2025Recent explainable artificial intelligence (XAI) methods for time series primarily estimate point-wise attribution magnitudes, while overlooking the directional impact on predictions, leading to suboptimal identification of significant points. Our analysis shows that conventional Integrated Gradients (IG) effectively capture critical points with both positive and negative impacts on predictions. However, current evaluation metrics fail to assess this capability, as they inadvertently cancel out opposing feature contributions. To address this limitation, we propose novel evaluation metrics-Cumulative Prediction Difference (CPD) and Cumulative Prediction Preservation (CPP)-to systematically assess whether attribution methods accurately identify significant positive and negative points in time series XAI. Under these metrics, conventional IG outperforms recent counterparts. However, directly applying IG to time series data may lead to suboptimal outcomes, as generated paths ignore temporal relationships and introduce out-of-distribution samples. To overcome these challenges, we introduce TIMING, which enhances IG by incorporating temporal awareness while maintaining its theoretical properties. Extensive experiments on synthetic and real-world time series benchmarks demonstrate that TIMING outperforms existing time series XAI baselines. Our code is available at https://github.com/drumpt/TIMING.
Reasoning Model is Stubborn: Diagnosing Instruction Overriding in Reasoning Models
May 22, 2025


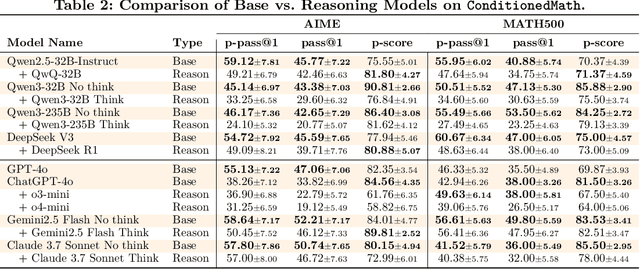
Large language models have demonstrated remarkable proficiency in long and complex reasoning tasks. However, they frequently exhibit a problematic reliance on familiar reasoning patterns, a phenomenon we term \textit{reasoning rigidity}. Despite explicit instructions from users, these models often override clearly stated conditions and default to habitual reasoning trajectories, leading to incorrect conclusions. This behavior presents significant challenges, particularly in domains such as mathematics and logic puzzle, where precise adherence to specified constraints is critical. To systematically investigate reasoning rigidity, a behavior largely unexplored in prior work, we introduce a expert-curated diagnostic set, \dataset{}. Our dataset includes specially modified variants of existing mathematical benchmarks, namely AIME and MATH500, as well as well-known puzzles deliberately redesigned to require deviation from familiar reasoning strategies. Using this dataset, we identify recurring contamination patterns that occur when models default to ingrained reasoning. Specifically, we categorize this contamination into three distinctive modes: (i) Interpretation Overload, (ii) Input Distrust, and (iii) Partial Instruction Attention, each causing models to ignore or distort provided instructions. We publicly release our diagnostic set to facilitate future research on mitigating reasoning rigidity in language models.