 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLANTERN++: Enhanced Relaxed Speculative Decoding with Static Tree Drafting for Visual Auto-regressive Models
Feb 10, 2025



Speculative decoding has been widely used to accelerate autoregressive (AR) text generation. However, its effectiveness in visual AR models remains limited due to token selection ambiguity, where multiple tokens receive similarly low probabilities, reducing acceptance rates. While dynamic tree drafting has been proposed to improve speculative decoding, we show that it fails to mitigate token selection ambiguity, resulting in shallow draft trees and suboptimal acceleration. To address this, we introduce LANTERN++, a novel framework that integrates static tree drafting with a relaxed acceptance condition, allowing drafts to be selected independently of low-confidence predictions. This enables deeper accepted sequences, improving decoding efficiency while preserving image quality. Extensive experiments on state-of-the-art visual AR models demonstrate that LANTERN++ significantly accelerates inference, achieving up to $\mathbf{\times 2.56}$ speedup over standard AR decoding while maintaining high image quality.
TTD: Text-Tag Self-Distillation Enhancing Image-Text Alignment in CLIP to Alleviate Single Tag Bias
Mar 30, 2024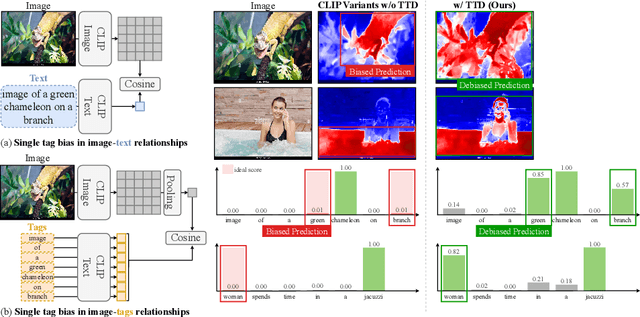
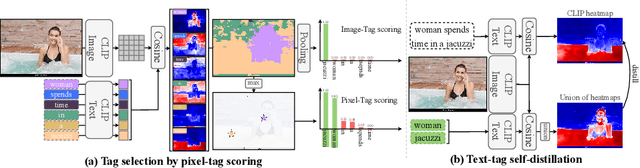

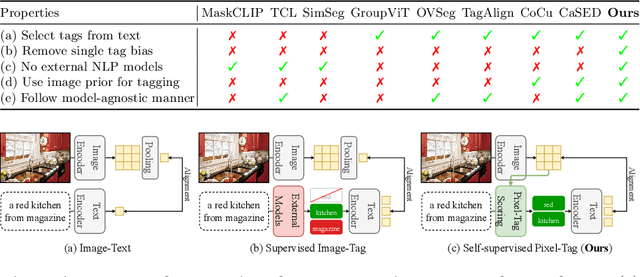
We identify a critical bias in contemporary CLIP-based models, which we denote as \textit{single tag bias}. This bias manifests as a disproportionate focus on a singular tag (word) while neglecting other pertinent tags, stemming from CLIP's text embeddings that prioritize one specific tag in image-text relationships. When deconstructing text into individual tags, only one tag tends to have high relevancy with CLIP's image embedding, leading to an imbalanced tag relevancy. This results in an uneven alignment among multiple tags present in the text. To tackle this challenge, we introduce a novel two-step fine-tuning approach. First, our method leverages the similarity between tags and their nearest pixels for scoring, enabling the extraction of image-relevant tags from the text. Second, we present a self-distillation strategy aimed at aligning the combined masks from extracted tags with the text-derived mask. This approach mitigates the single tag bias, thereby significantly improving the alignment of CLIP's model without necessitating additional data or supervision. Our technique demonstrates model-agnostic improvements in multi-tag classification and segmentation tasks, surpassing competing methods that rely on external resources. Code is available at https://github.com/shjo-april/TTD.
Reliable Estimation of Individual Treatment Effect with Causal Information Bottleneck
Jun 07, 2019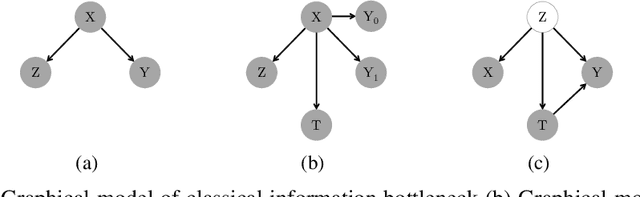



Estimating individual level treatment effects (ITE) from observational data is a challenging and important area in causal machine learning and is commonly considered in diverse mission-critical applications. In this paper, we propose an information theoretic approach in order to find more reliable representations for estimating ITE. We leverage the Information Bottleneck (IB) principle, which addresses the trade-off between conciseness and predictive power of representation. With the introduction of an extended graphical model for causal information bottleneck, we encourage the independence between the learned representation and the treatment type. We also introduce an additional form of a regularizer from the perspective of understanding ITE in the semi-supervised learning framework to ensure more reliable representations. Experimental results show that our model achieves the state-of-the-art results and exhibits more reliable prediction performances with uncertainty information on real-world datasets.
Tsallis Reinforcement Learning: A Unified Framework for Maximum Entropy Reinforcement Learning
Feb 07, 2019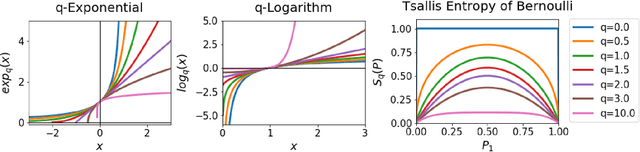

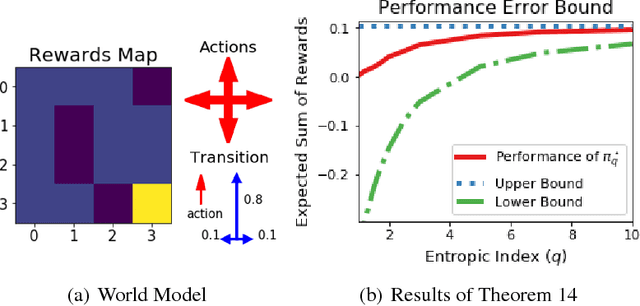
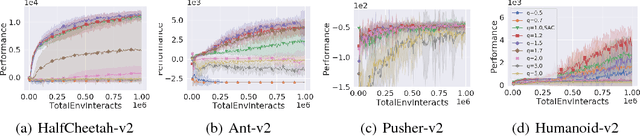
In this paper, we present a new class of Markov decision processes (MDPs), called Tsallis MDPs, with Tsallis entropy maximization, which generalizes existing maximum entropy reinforcement learning (RL). A Tsallis MDP provides a unified framework for the original RL problem and RL with various types of entropy, including the well-known standard Shannon-Gibbs (SG) entropy, using an additional real-valued parameter, called an entropic index. By controlling the entropic index, we can generate various types of entropy, including the SG entropy, and a different entropy results in a different class of the optimal policy in Tsallis MDPs. We also provide a full mathematical analysis of Tsallis MDPs, including the optimality condition, performance error bounds, and convergence. Our theoretical result enables us to use any positive entropic index in RL. To handle complex and large-scale problems, we propose a model-free actor-critic RL method using Tsallis entropy maximization. We evaluate the regularization effect of the Tsallis entropy with various values of entropic indices and show that the entropic index controls the exploration tendency of the proposed method. For a different type of RL problems, we find that a different value of the entropic index is desirable. The proposed method is evaluated using the MuJoCo simulator and achieves the state-of-the-art performance.