 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRVN-Bench: A Benchmark for Reactive Visual Navigation
Mar 04, 2026Safe visual navigation is critical for indoor mobile robots operating in cluttered environments. Existing benchmarks, however, often neglect collisions or are designed for outdoor scenarios, making them unsuitable for indoor visual navigation. To address this limitation, we introduce the reactive visual navigation benchmark (RVN-Bench), a collision-aware benchmark for indoor mobile robots. In RVN-Bench, an agent must reach sequential goal positions in previously unseen environments using only visual observations and no prior map, while avoiding collisions. Built on the Habitat 2.0 simulator and leveraging high-fidelity HM3D scenes, RVN-Bench provides large-scale, diverse indoor environments, defines a collision-aware navigation task and evaluation metrics, and offers tools for standardized training and benchmarking. RVN-Bench supports both online and offline learning by offering an environment for online reinforcement learning, a trajectory image dataset generator, and tools for producing negative trajectory image datasets that capture collision events. Experiments show that policies trained on RVN-Bench generalize effectively to unseen environments, demonstrating its value as a standardized benchmark for safe and robust visual navigation. Code and additional materials are available at: https://rvn-bench.github.io/.
Tidiness Score-Guided Monte Carlo Tree Search for Visual Tabletop Rearrangement
Feb 24, 2025


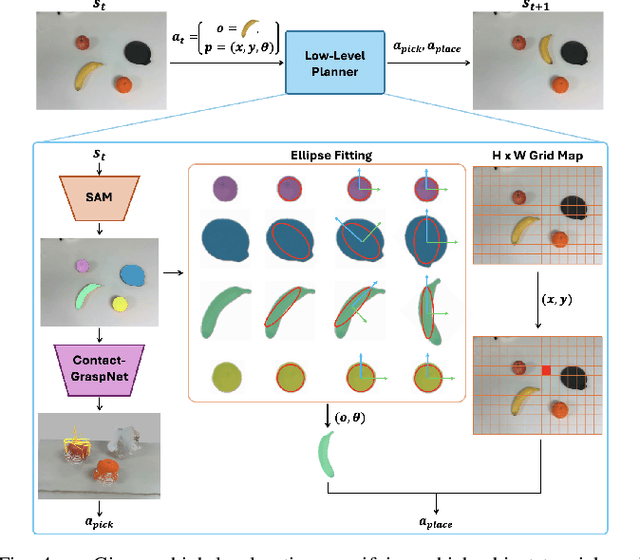
In this paper, we present the tidiness score-guided Monte Carlo tree search (TSMCTS), a novel framework designed to address the tabletop tidying up problem using only an RGB-D camera. We address two major problems for tabletop tidying up problem: (1) the lack of public datasets and benchmarks, and (2) the difficulty of specifying the goal configuration of unseen objects. We address the former by presenting the tabletop tidying up (TTU) dataset, a structured dataset collected in simulation. Using this dataset, we train a vision-based discriminator capable of predicting the tidiness score. This discriminator can consistently evaluate the degree of tidiness across unseen configurations, including real-world scenes. Addressing the second problem, we employ Monte Carlo tree search (MCTS) to find tidying trajectories without specifying explicit goals. Instead of providing specific goals, we demonstrate that our MCTS-based planner can find diverse tidied configurations using the tidiness score as a guidance. Consequently, we propose TSMCTS, which integrates a tidiness discriminator with an MCTS-based tidying planner to find optimal tidied arrangements. TSMCTS has successfully demonstrated its capability across various environments, including coffee tables, dining tables, office desks, and bathrooms. The TTU dataset is available at: https://github.com/rllab-snu/TTU-Dataset.
Adversarial Environment Design via Regret-Guided Diffusion Models
Oct 25, 2024


Training agents that are robust to environmental changes remains a significant challenge in deep reinforcement learning (RL). Unsupervised environment design (UED) has recently emerged to address this issue by generating a set of training environments tailored to the agent's capabilities. While prior works demonstrate that UED has the potential to learn a robust policy, their performance is constrained by the capabilities of the environment generation. To this end, we propose a novel UED algorithm, adversarial environment design via regret-guided diffusion models (ADD). The proposed method guides the diffusion-based environment generator with the regret of the agent to produce environments that the agent finds challenging but conducive to further improvement. By exploiting the representation power of diffusion models, ADD can directly generate adversarial environments while maintaining the diversity of training environments, enabling the agent to effectively learn a robust policy. Our experimental results demonstrate that the proposed method successfully generates an instructive curriculum of environments, outperforming UED baselines in zero-shot generalization across novel, out-of-distribution environments. Project page: https://github.com/rllab-snu.github.io/projects/ADD
RNR-Nav: A Real-World Visual Navigation System Using Renderable Neural Radiance Maps
Oct 08, 2024We propose a novel visual localization and navigation framework for real-world environments directly integrating observed visual information into the bird-eye-view map. While the renderable neural radiance map (RNR-Map) shows considerable promise in simulated settings, its deployment in real-world scenarios poses undiscovered challenges. RNR-Map utilizes projections of multiple vectors into a single latent code, resulting in information loss under suboptimal conditions. To address such issues, our enhanced RNR-Map for real-world robots, RNR-Map++, incorporates strategies to mitigate information loss, such as a weighted map and positional encoding. For robust real-time localization, we integrate a particle filter into the correlation-based localization framework using RNRMap++ without a rendering procedure. Consequently, we establish a real-world robot system for visual navigation utilizing RNR-Map++, which we call "RNR-Nav." Experimental results demonstrate that the proposed methods significantly enhance rendering quality and localization robustness compared to previous approaches. In real-world navigation tasks, RNR-Nav achieves a success rate of 84.4%, marking a 68.8% enhancement over the methods of the original RNR-Map paper.
Semantic Environment Atlas for Object-Goal Navigation
Oct 05, 2024
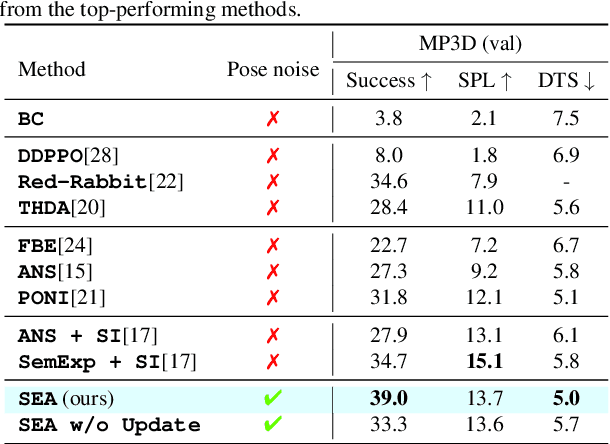
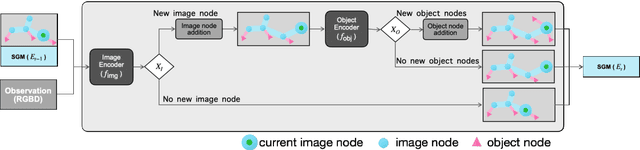
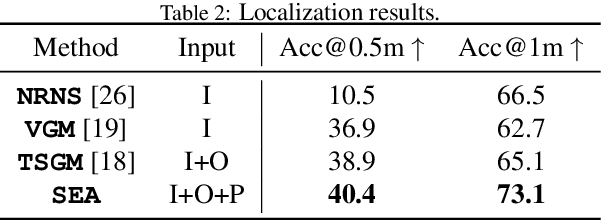
In this paper, we introduce the Semantic Environment Atlas (SEA), a novel mapping approach designed to enhance visual navigation capabilities of embodied agents. The SEA utilizes semantic graph maps that intricately delineate the relationships between places and objects, thereby enriching the navigational context. These maps are constructed from image observations and capture visual landmarks as sparsely encoded nodes within the environment. The SEA integrates multiple semantic maps from various environments, retaining a memory of place-object relationships, which proves invaluable for tasks such as visual localization and navigation. We developed navigation frameworks that effectively leverage the SEA, and we evaluated these frameworks through visual localization and object-goal navigation tasks. Our SEA-based localization framework significantly outperforms existing methods, accurately identifying locations from single query images. Experimental results in Habitat scenarios show that our method not only achieves a success rate of 39.0%, an improvement of 12.4% over the current state-of-the-art, but also maintains robustness under noisy odometry and actuation conditions, all while keeping computational costs low.
* 30 pages
Safe CoR: A Dual-Expert Approach to Integrating Imitation Learning and Safe Reinforcement Learning Using Constraint Rewards
Jul 02, 2024
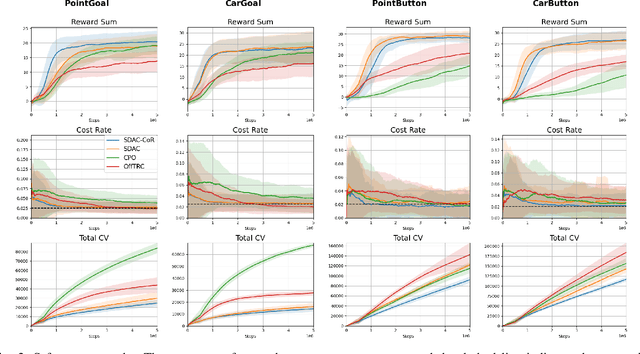


In the realm of autonomous agents, ensuring safety and reliability in complex and dynamic environments remains a paramount challenge. Safe reinforcement learning addresses these concerns by introducing safety constraints, but still faces challenges in navigating intricate environments such as complex driving situations. To overcome these challenges, we present the safe constraint reward (Safe CoR) framework, a novel method that utilizes two types of expert demonstrations$\unicode{x2013}$reward expert demonstrations focusing on performance optimization and safe expert demonstrations prioritizing safety. By exploiting a constraint reward (CoR), our framework guides the agent to balance performance goals of reward sum with safety constraints. We test the proposed framework in diverse environments, including the safety gym, metadrive, and the real$\unicode{x2013}$world Jackal platform. Our proposed framework enhances the performance of algorithms by $39\%$ and reduces constraint violations by $88\%$ on the real-world Jackal platform, demonstrating the framework's efficacy. Through this innovative approach, we expect significant advancements in real-world performance, leading to transformative effects in the realm of safe and reliable autonomous agents.
Spectral-Risk Safe Reinforcement Learning with Convergence Guarantees
May 29, 2024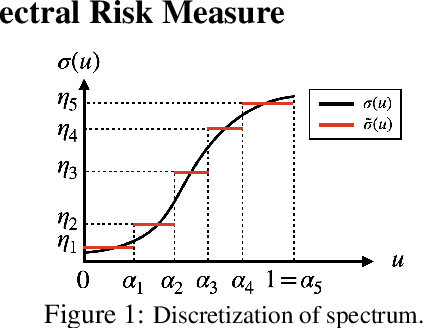
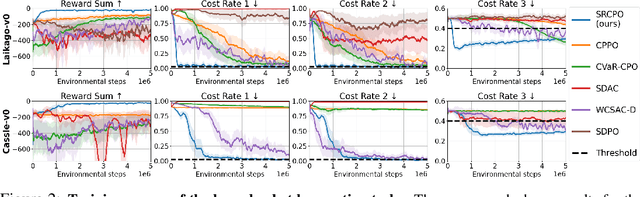
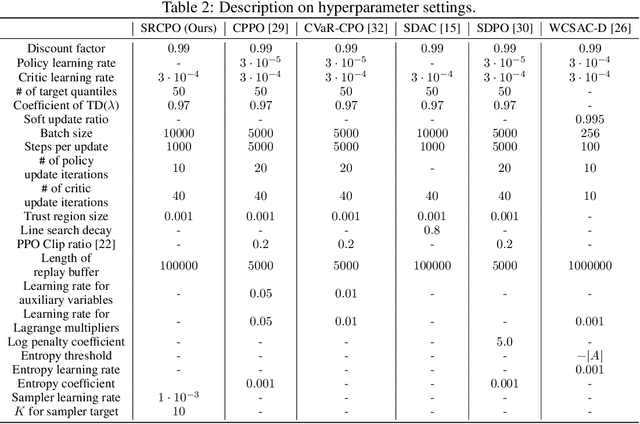
The field of risk-constrained reinforcement learning (RCRL) has been developed to effectively reduce the likelihood of worst-case scenarios by explicitly handling risk-measure-based constraints. However, the nonlinearity of risk measures makes it challenging to achieve convergence and optimality. To overcome the difficulties posed by the nonlinearity, we propose a spectral risk measure-constrained RL algorithm, spectral-risk-constrained policy optimization (SRCPO), a bilevel optimization approach that utilizes the duality of spectral risk measures. In the bilevel optimization structure, the outer problem involves optimizing dual variables derived from the risk measures, while the inner problem involves finding an optimal policy given these dual variables. The proposed method, to the best of our knowledge, is the first to guarantee convergence to an optimum in the tabular setting. Furthermore, the proposed method has been evaluated on continuous control tasks and showed the best performance among other RCRL algorithms satisfying the constraints.
Scale-Invariant Gradient Aggregation for Constrained Multi-Objective Reinforcement Learning
Mar 01, 2024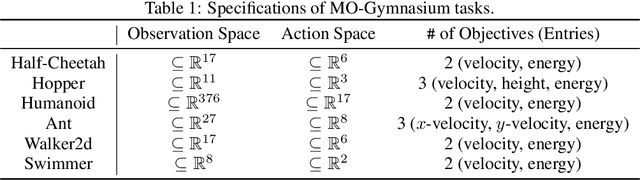
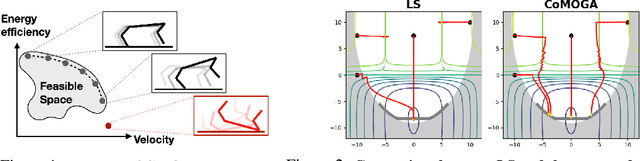
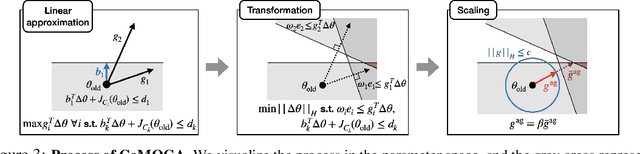

Multi-objective reinforcement learning (MORL) aims to find a set of Pareto optimal policies to cover various preferences. However, to apply MORL in real-world applications, it is important to find policies that are not only Pareto optimal but also satisfy pre-defined constraints for safety. To this end, we propose a constrained MORL (CMORL) algorithm called Constrained Multi-Objective Gradient Aggregator (CoMOGA). Recognizing the difficulty of handling multiple objectives and constraints concurrently, CoMOGA relaxes the original CMORL problem into a constrained optimization problem by transforming the objectives into additional constraints. This novel transformation process ensures that the converted constraints are invariant to the objective scales while having the same effect as the original objectives. We show that the proposed method converges to a local Pareto optimal policy while satisfying the predefined constraints. Empirical evaluations across various tasks show that the proposed method outperforms other baselines by consistently meeting constraints and demonstrating invariance to the objective scales.
Diffused Task-Agnostic Milestone Planner
Dec 06, 2023



Addressing decision-making problems using sequence modeling to predict future trajectories shows promising results in recent years. In this paper, we take a step further to leverage the sequence predictive method in wider areas such as long-term planning, vision-based control, and multi-task decision-making. To this end, we propose a method to utilize a diffusion-based generative sequence model to plan a series of milestones in a latent space and to have an agent to follow the milestones to accomplish a given task. The proposed method can learn control-relevant, low-dimensional latent representations of milestones, which makes it possible to efficiently perform long-term planning and vision-based control. Furthermore, our approach exploits generation flexibility of the diffusion model, which makes it possible to plan diverse trajectories for multi-task decision-making. We demonstrate the proposed method across offline reinforcement learning (RL) benchmarks and an visual manipulation environment. The results show that our approach outperforms offline RL methods in solving long-horizon, sparse-reward tasks and multi-task problems, while also achieving the state-of-the-art performance on the most challenging vision-based manipulation benchmark.
TRC: Trust Region Conditional Value at Risk for Safe Reinforcement Learning
Dec 01, 2023As safety is of paramount importance in robotics, reinforcement learning that reflects safety, called safe RL, has been studied extensively. In safe RL, we aim to find a policy which maximizes the desired return while satisfying the defined safety constraints. There are various types of constraints, among which constraints on conditional value at risk (CVaR) effectively lower the probability of failures caused by high costs since CVaR is a conditional expectation obtained above a certain percentile. In this paper, we propose a trust region-based safe RL method with CVaR constraints, called TRC. We first derive the upper bound on CVaR and then approximate the upper bound in a differentiable form in a trust region. Using this approximation, a subproblem to get policy gradients is formulated, and policies are trained by iteratively solving the subproblem. TRC is evaluated through safe navigation tasks in simulations with various robots and a sim-to-real environment with a Jackal robot from Clearpath. Compared to other safe RL methods, the performance is improved by 1.93 times while the constraints are satisfied in all experiments.
* RA-L and ICRA 2022