 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Environment Atlas for Object-Goal Navigation
Oct 05, 2024
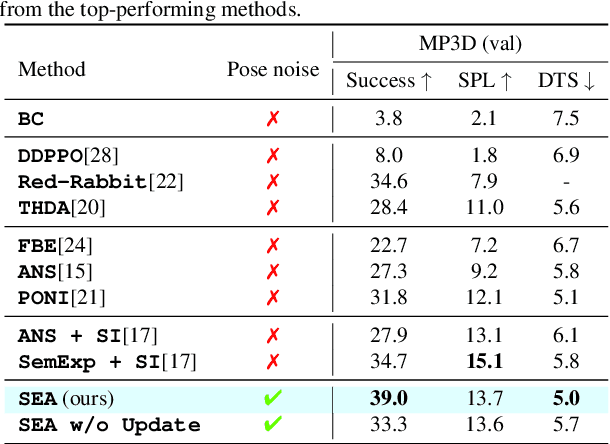
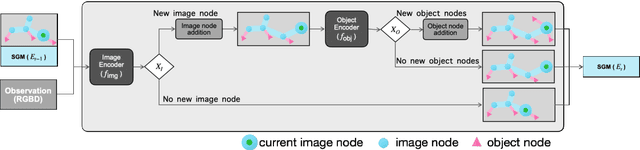
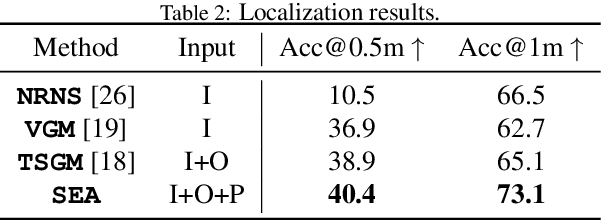
In this paper, we introduce the Semantic Environment Atlas (SEA), a novel mapping approach designed to enhance visual navigation capabilities of embodied agents. The SEA utilizes semantic graph maps that intricately delineate the relationships between places and objects, thereby enriching the navigational context. These maps are constructed from image observations and capture visual landmarks as sparsely encoded nodes within the environment. The SEA integrates multiple semantic maps from various environments, retaining a memory of place-object relationships, which proves invaluable for tasks such as visual localization and navigation. We developed navigation frameworks that effectively leverage the SEA, and we evaluated these frameworks through visual localization and object-goal navigation tasks. Our SEA-based localization framework significantly outperforms existing methods, accurately identifying locations from single query images. Experimental results in Habitat scenarios show that our method not only achieves a success rate of 39.0%, an improvement of 12.4% over the current state-of-the-art, but also maintains robustness under noisy odometry and actuation conditions, all while keeping computational costs low.
* 30 pages
Topological Semantic Graph Memory for Image-Goal Navigation
Sep 17, 2022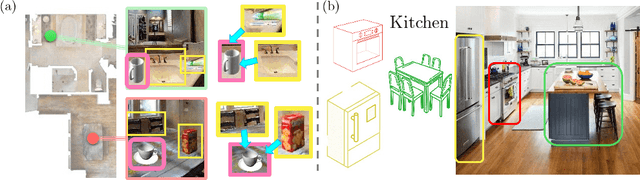
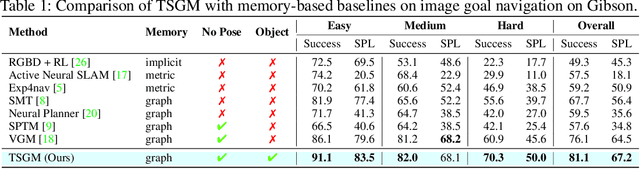
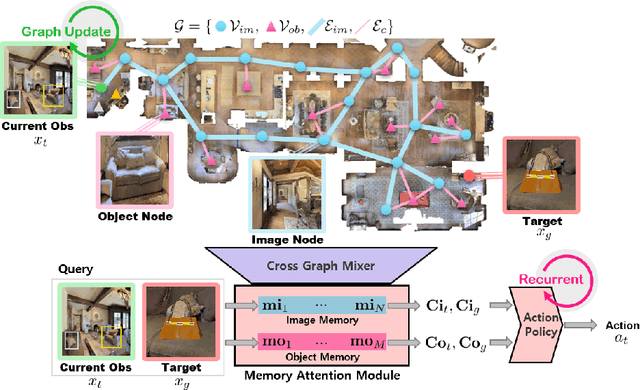
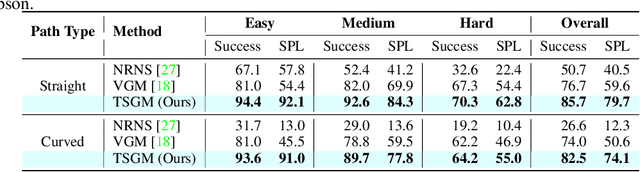
A novel framework is proposed to incrementally collect landmark-based graph memory and use the collected memory for image goal navigation. Given a target image to search, an embodied robot utilizes semantic memory to find the target in an unknown environment. % The semantic graph memory is collected from a panoramic observation of an RGB-D camera without knowing the robot's pose. In this paper, we present a topological semantic graph memory (TSGM), which consists of (1) a graph builder that takes the observed RGB-D image to construct a topological semantic graph, (2) a cross graph mixer module that takes the collected nodes to get contextual information, and (3) a memory decoder that takes the contextual memory as an input to find an action to the target. On the task of image goal navigation, TSGM significantly outperforms competitive baselines by +5.0-9.0% on the success rate and +7.0-23.5% on SPL, which means that the TSGM finds efficient paths. Additionally, we demonstrate our method on a mobile robot in real-world image goal scenarios.
Learning Instance-Aware Object Detection Using Determinantal Point Processes
May 30, 2018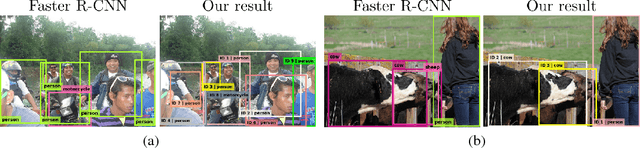



Recent object detectors find instances while categorizing candidate regions in an input image. As each region is evaluated independently, the number of candidate regions from a detector is usually larger than the number of objects. Since the final goal of detection is to assign a single detection to each object, an additional algorithm, such as non-maximum suppression (NMS), is used to select a single bounding box for an object. While simple heuristic algorithms, such as NMS, are effective for stand-alone objects, they can fail to detect overlapped objects. In this paper, we address this issue by training a network to distinguish different objects while localizing and categorizing them. We propose an instance-aware detection network (IDNet), which can learn to extract features from candidate regions and measures their similarities. Based on pairwise similarities and detection qualities, the IDNet selects an optimal subset of candidate bounding boxes using determinantal point processes (DPPs). Extensive experiments demonstrate that the proposed algorithm performs favorably compared to existing state-of-the-art detection methods particularly for overlapped objects on the PASCAL VOC and MS COCO datasets.
Interactive Text2Pickup Network for Natural Language based Human-Robot Collaboration
May 28, 2018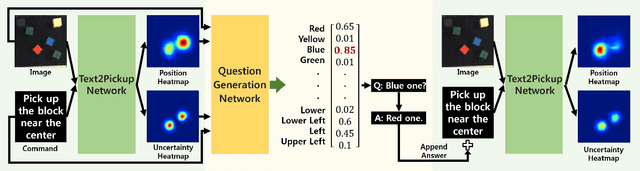
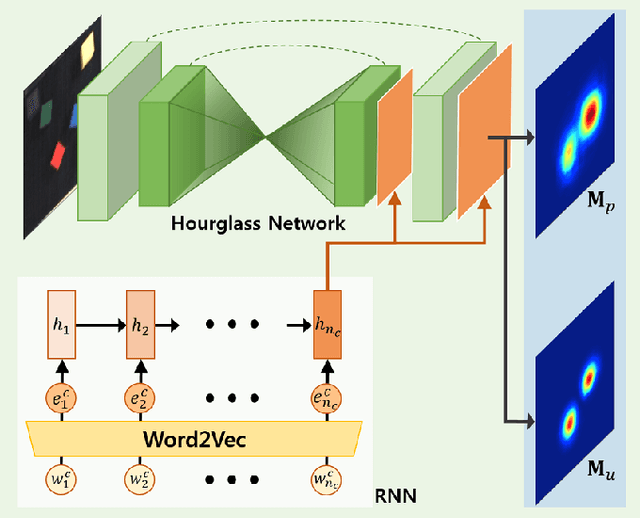
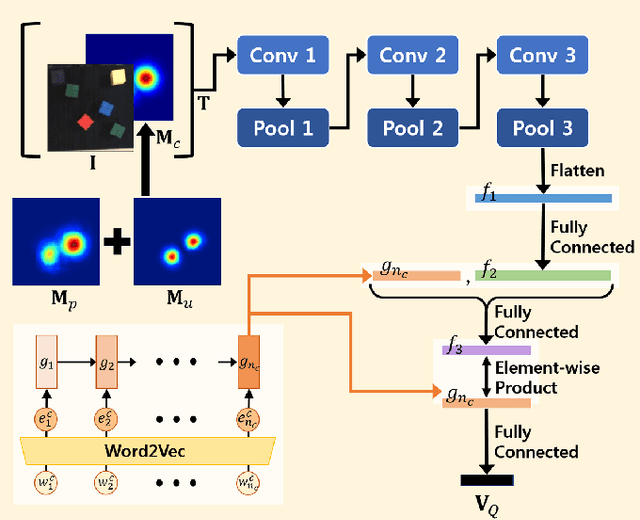
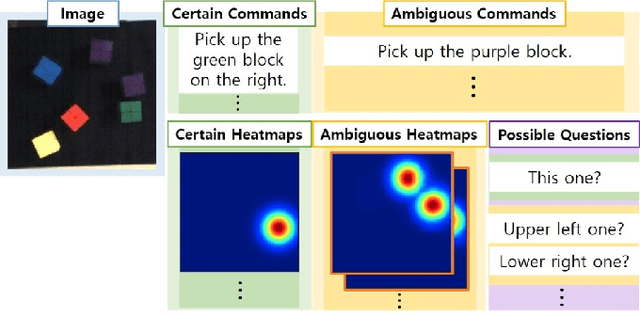
In this paper, we propose the Interactive Text2Pickup (IT2P) network for human-robot collaboration which enables an effective interaction with a human user despite the ambiguity in user's commands. We focus on the task where a robot is expected to pick up an object instructed by a human, and to interact with the human when the given instruction is vague. The proposed network understands the command from the human user and estimates the position of the desired object first. To handle the inherent ambiguity in human language commands, a suitable question which can resolve the ambiguity is generated. The user's answer to the question is combined with the initial command and given back to the network, resulting in more accurate estimation. The experiment results show that given unambiguous commands, the proposed method can estimate the position of the requested object with an accuracy of 98.49% based on our test dataset. Given ambiguous language commands, we show that the accuracy of the pick up task increases by 1.94 times after incorporating the information obtained from the interaction.