 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShallow-π: Knowledge Distillation for Flow-based VLAs
Jan 28, 2026The growing demand for real-time robotic deployment necessitates fast and on-device inference for vision-language-action (VLA) models. Within the VLA literature, efficiency has been extensively studied at the token level, such as visual token pruning. In contrast, systematic transformer layer reduction has received limited attention and, to the best of our knowledge, has not been explored for flow-based VLA models under knowledge distillation. In this work, we propose Shallow-pi, a principled knowledge distillation framework that aggressively reduces the transformer depth of both the VLM backbone and the flow-based action head, compressing the model from 18 to 6 layers. Shallow-pi achieves over two times faster inference with less than one percent absolute drop in success rate on standard manipulation benchmarks, establishing state-of-the-art performance among reduced VLA models. Crucially, we validate our approach through industrial-scale real-world experiments on Jetson Orin and Jetson Thor across multiple robot platforms, including humanoid systems, in complex and dynamic manipulation scenarios.
Topological Semantic Graph Memory for Image-Goal Navigation
Sep 17, 2022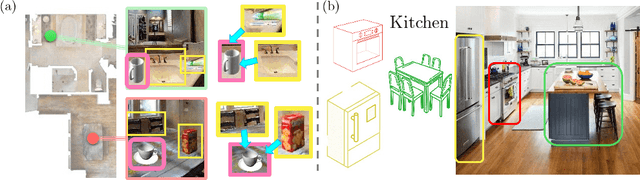
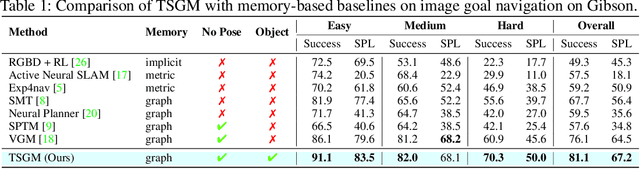
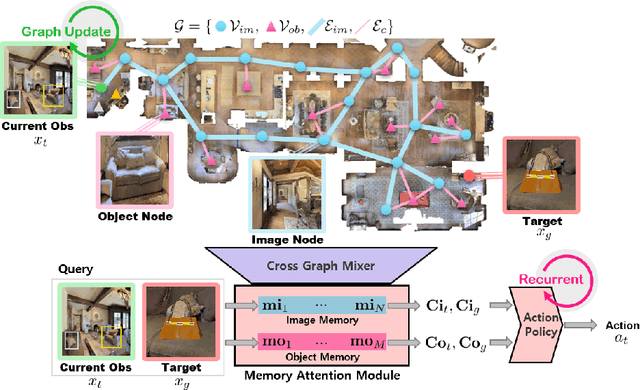
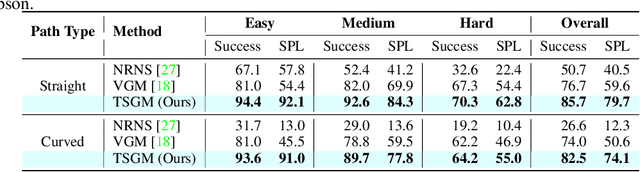
A novel framework is proposed to incrementally collect landmark-based graph memory and use the collected memory for image goal navigation. Given a target image to search, an embodied robot utilizes semantic memory to find the target in an unknown environment. % The semantic graph memory is collected from a panoramic observation of an RGB-D camera without knowing the robot's pose. In this paper, we present a topological semantic graph memory (TSGM), which consists of (1) a graph builder that takes the observed RGB-D image to construct a topological semantic graph, (2) a cross graph mixer module that takes the collected nodes to get contextual information, and (3) a memory decoder that takes the contextual memory as an input to find an action to the target. On the task of image goal navigation, TSGM significantly outperforms competitive baselines by +5.0-9.0% on the success rate and +7.0-23.5% on SPL, which means that the TSGM finds efficient paths. Additionally, we demonstrate our method on a mobile robot in real-world image goal scenarios.
Text2Action: Generative Adversarial Synthesis from Language to Action
Oct 24, 2017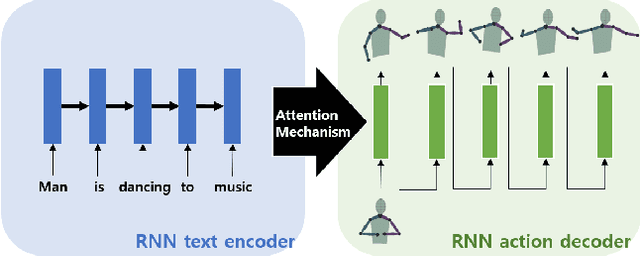



In this paper, we propose a generative model which learns the relationship between language and human action in order to generate a human action sequence given a sentence describing human behavior. The proposed generative model is a generative adversarial network (GAN), which is based on the sequence to sequence (SEQ2SEQ) model. Using the proposed generative network, we can synthesize various actions for a robot or a virtual agent using a text encoder recurrent neural network (RNN) and an action decoder RNN. The proposed generative network is trained from 29,770 pairs of actions and sentence annotations extracted from MSR-Video-to-Text (MSR-VTT), a large-scale video dataset. We demonstrate that the network can generate human-like actions which can be transferred to a Baxter robot, such that the robot performs an action based on a provided sentence. Results show that the proposed generative network correctly models the relationship between language and action and can generate a diverse set of actions from the same sentence.