 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHILD (Controller for Humanoid Imitation and Live Demonstration): a Whole-Body Humanoid Teleoperation System
Jul 31, 2025Recent advances in teleoperation have demonstrated robots performing complex manipulation tasks. However, existing works rarely support whole-body joint-level teleoperation for humanoid robots, limiting the diversity of tasks that can be accomplished. This work presents Controller for Humanoid Imitation and Live Demonstration (CHILD), a compact reconfigurable teleoperation system that enables joint level control over humanoid robots. CHILD fits within a standard baby carrier, allowing the operator control over all four limbs, and supports both direct joint mapping for full-body control and loco-manipulation. Adaptive force feedback is incorporated to enhance operator experience and prevent unsafe joint movements. We validate the capabilities of this system by conducting loco-manipulation and full-body control examples on a humanoid robot and multiple dual-arm systems. Lastly, we open-source the design of the hardware promoting accessibility and reproducibility. Additional details and open-source information are available at our project website: https://uiuckimlab.github.io/CHILD-pages.
RNR-Nav: A Real-World Visual Navigation System Using Renderable Neural Radiance Maps
Oct 08, 2024We propose a novel visual localization and navigation framework for real-world environments directly integrating observed visual information into the bird-eye-view map. While the renderable neural radiance map (RNR-Map) shows considerable promise in simulated settings, its deployment in real-world scenarios poses undiscovered challenges. RNR-Map utilizes projections of multiple vectors into a single latent code, resulting in information loss under suboptimal conditions. To address such issues, our enhanced RNR-Map for real-world robots, RNR-Map++, incorporates strategies to mitigate information loss, such as a weighted map and positional encoding. For robust real-time localization, we integrate a particle filter into the correlation-based localization framework using RNRMap++ without a rendering procedure. Consequently, we establish a real-world robot system for visual navigation utilizing RNR-Map++, which we call "RNR-Nav." Experimental results demonstrate that the proposed methods significantly enhance rendering quality and localization robustness compared to previous approaches. In real-world navigation tasks, RNR-Nav achieves a success rate of 84.4%, marking a 68.8% enhancement over the methods of the original RNR-Map paper.
Renderable Neural Radiance Map for Visual Navigation
Mar 03, 2023



We propose a novel type of map for visual navigation, a renderable neural radiance map (RNR-Map), which is designed to contain the overall visual information of a 3D environment. The RNR-Map has a grid form and consists of latent codes at each pixel. These latent codes are embedded from image observations, and can be converted to the neural radiance field which enables image rendering given a camera pose. The recorded latent codes implicitly contain visual information about the environment, which makes the RNR-Map visually descriptive. This visual information in RNR-Map can be a useful guideline for visual localization and navigation. We develop localization and navigation frameworks that can effectively utilize the RNR-Map. We evaluate the proposed frameworks on camera tracking, visual localization, and image-goal navigation. Experimental results show that the RNR-Map-based localization framework can find the target location based on a single query image with fast speed and competitive accuracy compared to other baselines. Also, this localization framework is robust to environmental changes, and even finds the most visually similar places when a query image from a different environment is given. The proposed navigation framework outperforms the existing image-goal navigation methods in difficult scenarios, under odometry and actuation noises. The navigation framework shows 65.7% success rate in curved scenarios of the NRNS dataset, which is an improvement of 18.6% over the current state-of-the-art.
Topological Semantic Graph Memory for Image-Goal Navigation
Sep 17, 2022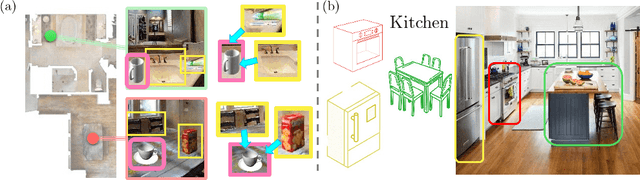
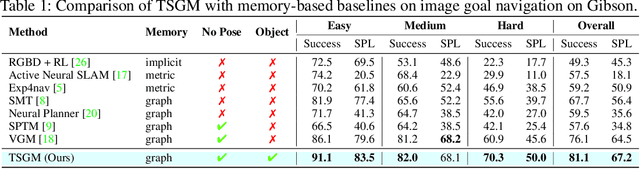
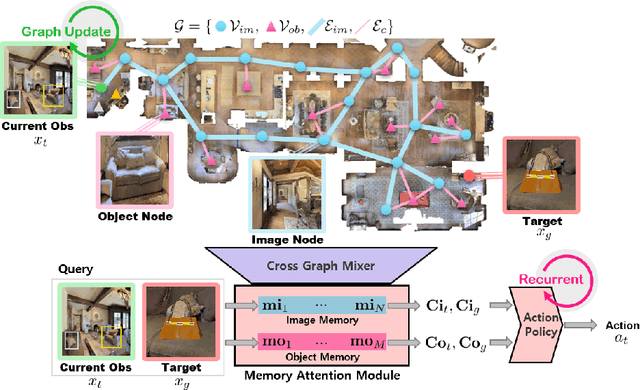
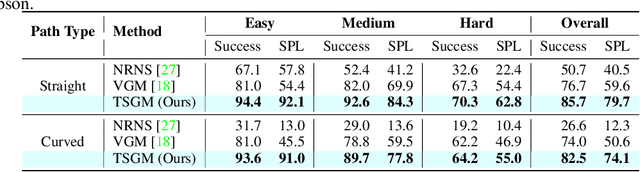
A novel framework is proposed to incrementally collect landmark-based graph memory and use the collected memory for image goal navigation. Given a target image to search, an embodied robot utilizes semantic memory to find the target in an unknown environment. % The semantic graph memory is collected from a panoramic observation of an RGB-D camera without knowing the robot's pose. In this paper, we present a topological semantic graph memory (TSGM), which consists of (1) a graph builder that takes the observed RGB-D image to construct a topological semantic graph, (2) a cross graph mixer module that takes the collected nodes to get contextual information, and (3) a memory decoder that takes the contextual memory as an input to find an action to the target. On the task of image goal navigation, TSGM significantly outperforms competitive baselines by +5.0-9.0% on the success rate and +7.0-23.5% on SPL, which means that the TSGM finds efficient paths. Additionally, we demonstrate our method on a mobile robot in real-world image goal scenarios.
Visually Grounding Instruction for History-Dependent Manipulation
Dec 16, 2020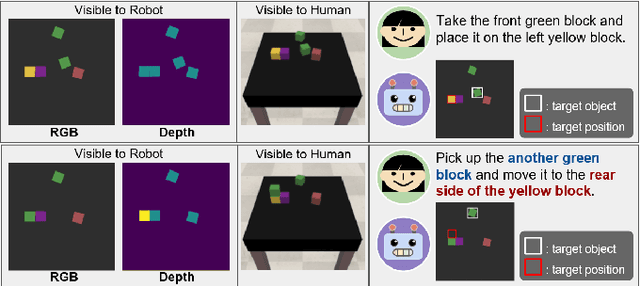


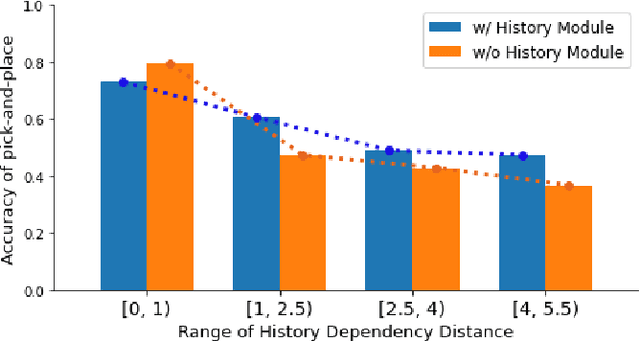
This paper emphasizes the importance of robot's ability to refer its task history, when it executes a series of pick-and-place manipulations by following text instructions given one by one. The advantage of referring the manipulation history can be categorized into two folds: (1) the instructions omitting details or using co-referential expressions can be interpreted, and (2) the visual information of objects occluded by previous manipulations can be inferred. For this challenge, we introduce the task of history-dependent manipulation which is to visually ground a series of text instructions for proper manipulations depending on the task history. We also suggest a relevant dataset and a methodology based on the deep neural network, and show that our network trained with a synthetic dataset can be applied to the real world based on images transferred into synthetic-style based on the CycleGAN.