 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVE2VF: Vision-Enabled to Vision-Free Distillation via Real-world Reinforcement Learning for Robust Contact-Rich Manipulation
May 28, 2026When using reinforcement learning (RL) for contact-rich robotic manipulation, vision can provide task-relevant information that accelerates learning beyond what proprioception alone can achieve. However, vision-enabled policies tend to overfit to the visual conditions seen during training, limiting their robustness and transferability. We present a human-in-the-loop RL framework that employs teacher-student distillation to achieve robust performance across multiple task variants, trained entirely in the real world without requiring domain randomization or data augmentation. A vision-enabled teacher distills its knowledge into a vision-free student that relies solely on pose, twist, and wrench sensing, combining fast training with strong task generalization. On the real-world NIST assembly benchmark board, our approach achieves 95\% overall success after approximately 50 minutes of training on 3 representative tasks, including robust generalization to 8 unseen task variants. Fine-tuning with distillation achieves full success on the most challenging task. We demonstrate that the resulting policies outperform baselines in both robustness and adaptability.
DexTwist: Dexterous Hand Retargeting for Twist Motion via Mixed Reality-based Teleoperation
May 12, 2026Dexterous teleoperation via Mixed Reality (MR)-based interfaces offers a scalable paradigm for transferring human manipulation skills to dexterous robot hands. However, conventional retargeting approaches that minimize kinematic dissimilarity (e.g., joint angle or fingertip position error) often fail in contact-rich rotational manipulation, such as cap opening, key turning, and bolt screwing. This failure stems from the embodiment gap: mismatched link lengths, joint axes/limits, and fingertip geometry can cause direct pose imitation to induce tangential fingertip sliding rather than stable object rotation, resulting in screw axis drift, contact slip, and grasp instability. To address this, we propose DexTwist, a functional twist-retargeting framework for MR-based dexterous teleoperation. DexTwist detects a tripod pinch, estimates the operator's intended screw axis and twist magnitude, and applies a real-time residual joint-space refinement that tracks turning progress while regularizing the robot tripod geometry. The refinement minimizes a virtual-object objective defined by turning angle, screw axis consistency, fingertip closure, and tripod stability. Simulation and real-world experiments show that DexTwist improves turning angle tracking and screw axis stability compared with a vector-based retargeting baseline.
Efficiently Learning Robust Torque-based Locomotion Through Reinforcement with Model-Based Supervision
Jan 22, 2026We propose a control framework that integrates model-based bipedal locomotion with residual reinforcement learning (RL) to achieve robust and adaptive walking in the presence of real-world uncertainties. Our approach leverages a model-based controller, comprising a Divergent Component of Motion (DCM) trajectory planner and a whole-body controller, as a reliable base policy. To address the uncertainties of inaccurate dynamics modeling and sensor noise, we introduce a residual policy trained through RL with domain randomization. Crucially, we employ a model-based oracle policy, which has privileged access to ground-truth dynamics during training, to supervise the residual policy via a novel supervised loss. This supervision enables the policy to efficiently learn corrective behaviors that compensate for unmodeled effects without extensive reward shaping. Our method demonstrates improved robustness and generalization across a range of randomized conditions, offering a scalable solution for sim-to-real transfer in bipedal locomotion.
Learning a Unified Latent Space for Cross-Embodiment Robot Control
Jan 21, 2026We present a scalable framework for cross-embodiment humanoid robot control by learning a shared latent representation that unifies motion across humans and diverse humanoid platforms, including single-arm, dual-arm, and legged humanoid robots. Our method proceeds in two stages: first, we construct a decoupled latent space that captures localized motion patterns across different body parts using contrastive learning, enabling accurate and flexible motion retargeting even across robots with diverse morphologies. To enhance alignment between embodiments, we introduce tailored similarity metrics that combine joint rotation and end-effector positioning for critical segments, such as arms. Then, we train a goal-conditioned control policy directly within this latent space using only human data. Leveraging a conditional variational autoencoder, our policy learns to predict latent space displacements guided by intended goal directions. We show that the trained policy can be directly deployed on multiple robots without any adaptation. Furthermore, our method supports the efficient addition of new robots to the latent space by learning only a lightweight, robot-specific embedding layer. The learned latent policies can also be directly applied to the new robots. Experimental results demonstrate that our approach enables robust, scalable, and embodiment-agnostic robot control across a wide range of humanoid platforms.
Interactive Robot Programming for Surface Finishing via Task-Centric Mixed Reality Interfaces
Dec 29, 2025Lengthy setup processes that require robotics expertise remain a major barrier to deploying robots for tasks involving high product variability and small batch sizes. As a result, collaborative robots, despite their advanced sensing and control capabilities, are rarely used for surface finishing in small-scale craft and manufacturing settings. To address this gap, we propose a novel robot programming approach that enables non-experts to intuitively program robots through interactive, task-focused workflows. For that, we developed a new surface segmentation algorithm that incorporates human input to identify and refine workpiece regions for processing. Throughout the programming process, users receive continuous visual feedback on the robot's learned model, enabling them to iteratively refine the segmentation result. Based on the segmented surface model, a robot trajectory is generated to cover the desired processing area. We evaluated multiple interaction designs across two comprehensive user studies to derive an optimal interface that significantly reduces user workload, improves usability and enables effective task programming even for users with limited practical experience.
Multimodal Anomaly Detection with a Mixture-of-Experts
Jun 23, 2025



With a growing number of robots being deployed across diverse applications, robust multimodal anomaly detection becomes increasingly important. In robotic manipulation, failures typically arise from (1) robot-driven anomalies due to an insufficient task model or hardware limitations, and (2) environment-driven anomalies caused by dynamic environmental changes or external interferences. Conventional anomaly detection methods focus either on the first by low-level statistical modeling of proprioceptive signals or the second by deep learning-based visual environment observation, each with different computational and training data requirements. To effectively capture anomalies from both sources, we propose a mixture-of-experts framework that integrates the complementary detection mechanisms with a visual-language model for environment monitoring and a Gaussian-mixture regression-based detector for tracking deviations in interaction forces and robot motions. We introduce a confidence-based fusion mechanism that dynamically selects the most reliable detector for each situation. We evaluate our approach on both household and industrial tasks using two robotic systems, demonstrating a 60% reduction in detection delay while improving frame-wise anomaly detection performance compared to individual detectors.
Hierarchical Task Decomposition for Execution Monitoring and Error Recovery: Understanding the Rationale Behind Task Demonstrations
May 07, 2025
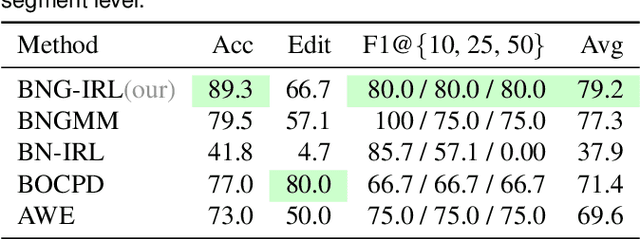
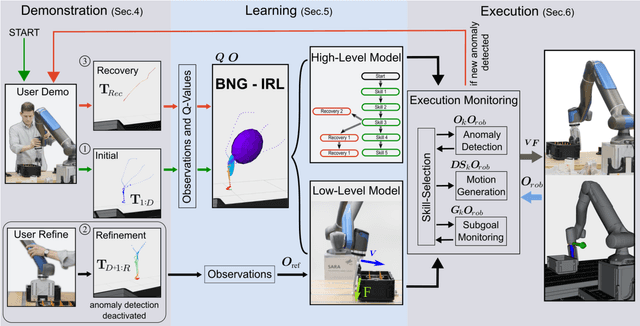
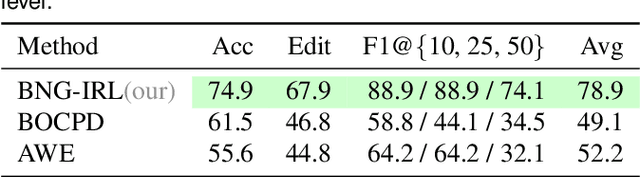
Multi-step manipulation tasks where robots interact with their environment and must apply process forces based on the perceived situation remain challenging to learn and prone to execution errors. Accurately simulating these tasks is also difficult. Hence, it is crucial for robust task performance to learn how to coordinate end-effector pose and applied force, monitor execution, and react to deviations. To address these challenges, we propose a learning approach that directly infers both low- and high-level task representations from user demonstrations on the real system. We developed an unsupervised task segmentation algorithm that combines intention recognition and feature clustering to infer the skills of a task. We leverage the inferred characteristic features of each skill in a novel unsupervised anomaly detection approach to identify deviations from the intended task execution. Together, these components form a comprehensive framework capable of incrementally learning task decisions and new behaviors as new situations arise. Compared to state-of-the-art learning techniques, our approach significantly reduces the required amount of training data and computational complexity while efficiently learning complex in-contact behaviors and recovery strategies. Our proposed task segmentation and anomaly detection approaches outperform state-of-the-art methods on force-based tasks evaluated on two different robotic systems.
M2R2: MulitModal Robotic Representation for Temporal Action Segmentation
Apr 25, 2025Temporal action segmentation (TAS) has long been a key area of research in both robotics and computer vision. In robotics, algorithms have primarily focused on leveraging proprioceptive information to determine skill boundaries, with recent approaches in surgical robotics incorporating vision. In contrast, computer vision typically relies on exteroceptive sensors, such as cameras. Existing multimodal TAS models in robotics integrate feature fusion within the model, making it difficult to reuse learned features across different models. Meanwhile, pretrained vision-only feature extractors commonly used in computer vision struggle in scenarios with limited object visibility. In this work, we address these challenges by proposing M2R2, a multimodal feature extractor tailored for TAS, which combines information from both proprioceptive and exteroceptive sensors. We introduce a novel pretraining strategy that enables the reuse of learned features across multiple TAS models. Our method achieves state-of-the-art performance on the REASSEMBLE dataset, a challenging multimodal robotic assembly dataset, outperforming existing robotic action segmentation models by 46.6%. Additionally, we conduct an extensive ablation study to evaluate the contribution of different modalities in robotic TAS tasks.
Variable Stiffness for Robust Locomotion through Reinforcement Learning
Feb 13, 2025



Reinforcement-learned locomotion enables legged robots to perform highly dynamic motions but often accompanies time-consuming manual tuning of joint stiffness. This paper introduces a novel control paradigm that integrates variable stiffness into the action space alongside joint positions, enabling grouped stiffness control such as per-joint stiffness (PJS), per-leg stiffness (PLS) and hybrid joint-leg stiffness (HJLS). We show that variable stiffness policies, with grouping in per-leg stiffness (PLS), outperform position-based control in velocity tracking and push recovery. In contrast, HJLS excels in energy efficiency. Furthermore, our method showcases robust walking behaviour on diverse outdoor terrains by sim-to-real transfer, although the policy is sorely trained on a flat floor. Our approach simplifies design by eliminating per-joint stiffness tuning while keeping competitive results with various metrics.
REASSEMBLE: A Multimodal Dataset for Contact-rich Robotic Assembly and Disassembly
Feb 07, 2025



Robotic manipulation remains a core challenge in robotics, particularly for contact-rich tasks such as industrial assembly and disassembly. Existing datasets have significantly advanced learning in manipulation but are primarily focused on simpler tasks like object rearrangement, falling short of capturing the complexity and physical dynamics involved in assembly and disassembly. To bridge this gap, we present REASSEMBLE (Robotic assEmbly disASSEMBLy datasEt), a new dataset designed specifically for contact-rich manipulation tasks. Built around the NIST Assembly Task Board 1 benchmark, REASSEMBLE includes four actions (pick, insert, remove, and place) involving 17 objects. The dataset contains 4,551 demonstrations, of which 4,035 were successful, spanning a total of 781 minutes. Our dataset features multi-modal sensor data including event cameras, force-torque sensors, microphones, and multi-view RGB cameras. This diverse dataset supports research in areas such as learning contact-rich manipulation, task condition identification, action segmentation, and more. We believe REASSEMBLE will be a valuable resource for advancing robotic manipulation in complex, real-world scenarios. The dataset is publicly available on our project website: https://dsliwowski1.github.io/REASSEMBLE_page.