 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoEx -- Co-evolving World-model and Exploration
Jul 29, 2025Planning in modern LLM agents relies on the utilization of LLM as an internal world model, acquired during pretraining. However, existing agent designs fail to effectively assimilate new observations into dynamic updates of the world model. This reliance on the LLM's static internal world model is progressively prone to misalignment with the underlying true state of the world, leading to the generation of divergent and erroneous plans. We introduce a hierarchical agent architecture, CoEx, in which hierarchical state abstraction allows LLM planning to co-evolve with a dynamically updated model of the world. CoEx plans and interacts with the world by using LLM reasoning to orchestrate dynamic plans consisting of subgoals, and its learning mechanism continuously incorporates these subgoal experiences into a persistent world model in the form of a neurosymbolic belief state, comprising textual inferences and code-based symbolic memory. We evaluate our agent across a diverse set of agent scenarios involving rich environments and complex tasks including ALFWorld, PDDL, and Jericho. Our experiments show that CoEx outperforms existing agent paradigms in planning and exploration.
Dispatch-Aware Deep Neural Network for Optimal Transmission Switching: Toward Real-Time and Feasibility Guaranteed Operation
Jul 23, 2025Optimal transmission switching (OTS) improves optimal power flow (OPF) by selectively opening transmission lines, but its mixed-integer formulation increases computational complexity, especially on large grids. To deal with this, we propose a dispatch-aware deep neural network (DA-DNN) that accelerates DC-OTS without relying on pre-solved labels. DA-DNN predicts line states and passes them through a differentiable DC-OPF layer, using the resulting generation cost as the loss function so that all physical network constraints are enforced throughout training and inference. In addition, we adopt a customized weight-bias initialization that keeps every forward pass feasible from the first iteration, which allows stable learning on large grids. Once trained, the proposed DA-DNN produces a provably feasible topology and dispatch pair in the same time as solving the DCOPF, whereas conventional mixed-integer solvers become intractable. As a result, the proposed method successfully captures the economic advantages of OTS while maintaining scalability.
Chaining Event Spans for Temporal Relation Grounding
Jun 17, 2025Accurately understanding temporal relations between events is a critical building block of diverse tasks, such as temporal reading comprehension (TRC) and relation extraction (TRE). For example in TRC, we need to understand the temporal semantic differences between the following two questions that are lexically near-identical: "What finished right before the decision?" or "What finished right after the decision?". To discern the two questions, existing solutions have relied on answer overlaps as a proxy label to contrast similar and dissimilar questions. However, we claim that answer overlap can lead to unreliable results, due to spurious overlaps of two dissimilar questions with coincidentally identical answers. To address the issue, we propose a novel approach that elicits proper reasoning behaviors through a module for predicting time spans of events. We introduce the Timeline Reasoning Network (TRN) operating in a two-step inductive reasoning process: In the first step model initially answers each question with semantic and syntactic information. The next step chains multiple questions on the same event to predict a timeline, which is then used to ground the answers. Results on the TORQUE and TB-dense, TRC and TRE tasks respectively, demonstrate that TRN outperforms previous methods by effectively resolving the spurious overlaps using the predicted timeline.
G-FOCUS: Towards a Robust Method for Assessing UI Design Persuasiveness
May 08, 2025



Evaluating user interface (UI) design effectiveness extends beyond aesthetics to influencing user behavior, a principle central to Design Persuasiveness. A/B testing is the predominant method for determining which UI variations drive higher user engagement, but it is costly and time-consuming. While recent Vision-Language Models (VLMs) can process automated UI analysis, current approaches focus on isolated design attributes rather than comparative persuasiveness-the key factor in optimizing user interactions. To address this, we introduce WiserUI-Bench, a benchmark designed for Pairwise UI Design Persuasiveness Assessment task, featuring 300 real-world UI image pairs labeled with A/B test results and expert rationales. Additionally, we propose G-FOCUS, a novel inference-time reasoning strategy that enhances VLM-based persuasiveness assessment by reducing position bias and improving evaluation accuracy. Experimental results show that G-FOCUS surpasses existing inference strategies in consistency and accuracy for pairwise UI evaluation. Through promoting VLM-driven evaluation of UI persuasiveness, our work offers an approach to complement A/B testing, propelling progress in scalable UI preference modeling and design optimization. Code and data will be released publicly.
Agent-as-Judge for Factual Summarization of Long Narratives
Jan 17, 2025



Large Language Models (LLMs) have demonstrated near-human performance in summarization tasks based on traditional metrics such as ROUGE and BERTScore. However, these metrics do not adequately capture critical aspects of summarization quality, such as factual accuracy, particularly for long narratives (>100K tokens). Recent advances, such as LLM-as-a-Judge, address the limitations of metrics based on lexical similarity but still exhibit factual inconsistencies, especially in understanding character relationships and states. In this work, we introduce NarrativeFactScore, a novel "Agent-as-a-Judge" framework for evaluating and refining summaries. By leveraging a Character Knowledge Graph (CKG) extracted from input and generated summaries, NarrativeFactScore assesses the factual consistency and provides actionable guidance for refinement, such as identifying missing or erroneous facts. We demonstrate the effectiveness of NarrativeFactScore through a detailed workflow illustration and extensive validation on widely adopted benchmarks, achieving superior performance compared to competitive methods. Our results highlight the potential of agent-driven evaluation systems to improve the factual reliability of LLM-generated summaries.
RILQ: Rank-Insensitive LoRA-based Quantization Error Compensation for Boosting 2-bit Large Language Model Accuracy
Dec 02, 2024Low-rank adaptation (LoRA) has become the dominant method for parameter-efficient LLM fine-tuning, with LoRA-based quantization error compensation (LQEC) emerging as a powerful tool for recovering accuracy in compressed LLMs. However, LQEC has underperformed in sub-4-bit scenarios, with no prior investigation into understanding this limitation. We propose RILQ (Rank-Insensitive LoRA-based Quantization Error Compensation) to understand fundamental limitation and boost 2-bit LLM accuracy. Based on rank analysis revealing model-wise activation discrepancy loss's rank-insensitive nature, RILQ employs this loss to adjust adapters cooperatively across layers, enabling robust error compensation with low-rank adapters. Evaluations on LLaMA-2 and LLaMA-3 demonstrate RILQ's consistent improvements in 2-bit quantized inference across various state-of-the-art quantizers and enhanced accuracy in task-specific fine-tuning. RILQ maintains computational efficiency comparable to existing LoRA methods, enabling adapter-merged weight-quantized LLM inference with significantly enhanced accuracy, making it a promising approach for boosting 2-bit LLM performance.
Controlling Diversity at Inference: Guiding Diffusion Recommender Models with Targeted Category Preferences
Nov 21, 2024Diversity control is an important task to alleviate bias amplification and filter bubble problems. The desired degree of diversity may fluctuate based on users' daily moods or business strategies. However, existing methods for controlling diversity often lack flexibility, as diversity is decided during training and cannot be easily modified during inference. We propose \textbf{D3Rec} (\underline{D}isentangled \underline{D}iffusion model for \underline{D}iversified \underline{Rec}ommendation), an end-to-end method that controls the accuracy-diversity trade-off at inference. D3Rec meets our three desiderata by (1) generating recommendations based on category preferences, (2) controlling category preferences during the inference phase, and (3) adapting to arbitrary targeted category preferences. In the forward process, D3Rec removes category preferences lurking in user interactions by adding noises. Then, in the reverse process, D3Rec generates recommendations through denoising steps while reflecting desired category preferences. Extensive experiments on real-world and synthetic datasets validate the effectiveness of D3Rec in controlling diversity at inference.
Adversarial Environment Design via Regret-Guided Diffusion Models
Oct 25, 2024

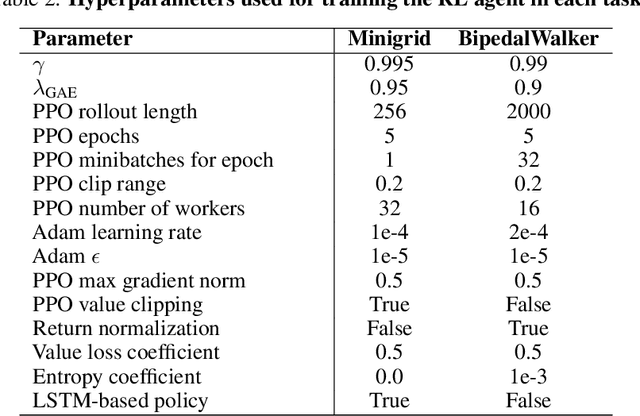

Training agents that are robust to environmental changes remains a significant challenge in deep reinforcement learning (RL). Unsupervised environment design (UED) has recently emerged to address this issue by generating a set of training environments tailored to the agent's capabilities. While prior works demonstrate that UED has the potential to learn a robust policy, their performance is constrained by the capabilities of the environment generation. To this end, we propose a novel UED algorithm, adversarial environment design via regret-guided diffusion models (ADD). The proposed method guides the diffusion-based environment generator with the regret of the agent to produce environments that the agent finds challenging but conducive to further improvement. By exploiting the representation power of diffusion models, ADD can directly generate adversarial environments while maintaining the diversity of training environments, enabling the agent to effectively learn a robust policy. Our experimental results demonstrate that the proposed method successfully generates an instructive curriculum of environments, outperforming UED baselines in zero-shot generalization across novel, out-of-distribution environments. Project page: https://github.com/rllab-snu.github.io/projects/ADD
Interventional Speech Noise Injection for ASR Generalizable Spoken Language Understanding
Oct 21, 2024Recently, pre-trained language models (PLMs) have been increasingly adopted in spoken language understanding (SLU). However, automatic speech recognition (ASR) systems frequently produce inaccurate transcriptions, leading to noisy inputs for SLU models, which can significantly degrade their performance. To address this, our objective is to train SLU models to withstand ASR errors by exposing them to noises commonly observed in ASR systems, referred to as ASR-plausible noises. Speech noise injection (SNI) methods have pursued this objective by introducing ASR-plausible noises, but we argue that these methods are inherently biased towards specific ASR systems, or ASR-specific noises. In this work, we propose a novel and less biased augmentation method of introducing the noises that are plausible to any ASR system, by cutting off the non-causal effect of noises. Experimental results and analyses demonstrate the effectiveness of our proposed methods in enhancing the robustness and generalizability of SLU models against unseen ASR systems by introducing more diverse and plausible ASR noises in advance.
RNR-Nav: A Real-World Visual Navigation System Using Renderable Neural Radiance Maps
Oct 08, 2024We propose a novel visual localization and navigation framework for real-world environments directly integrating observed visual information into the bird-eye-view map. While the renderable neural radiance map (RNR-Map) shows considerable promise in simulated settings, its deployment in real-world scenarios poses undiscovered challenges. RNR-Map utilizes projections of multiple vectors into a single latent code, resulting in information loss under suboptimal conditions. To address such issues, our enhanced RNR-Map for real-world robots, RNR-Map++, incorporates strategies to mitigate information loss, such as a weighted map and positional encoding. For robust real-time localization, we integrate a particle filter into the correlation-based localization framework using RNRMap++ without a rendering procedure. Consequently, we establish a real-world robot system for visual navigation utilizing RNR-Map++, which we call "RNR-Nav." Experimental results demonstrate that the proposed methods significantly enhance rendering quality and localization robustness compared to previous approaches. In real-world navigation tasks, RNR-Nav achieves a success rate of 84.4%, marking a 68.8% enhancement over the methods of the original RNR-Map paper.