 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Comprehensive Scene Understanding: Integrating First and Third-Person Views for LVLMs
May 28, 2025Large vision-language models (LVLMs) are increasingly deployed in interactive applications such as virtual and augmented reality, where first-person (egocentric) view captured by head-mounted cameras serves as key input. While this view offers fine-grained cues about user attention and hand-object interactions, their narrow field of view and lack of global context often lead to failures on spatially or contextually demanding queries. To address this, we introduce a framework that augments egocentric inputs with third-person (exocentric) views, providing complementary information such as global scene layout and object visibility to LVLMs. We present E3VQA, the first benchmark for multi-view question answering with 4K high-quality question-answer pairs grounded in synchronized ego-exo image pairs. Additionally, we propose M3CoT, a training-free prompting technique that constructs a unified scene representation by integrating scene graphs from three complementary perspectives. M3CoT enables LVLMs to reason more effectively across views, yielding consistent performance gains (4.84% for GPT-4o and 5.94% for Gemini 2.0 Flash) over a recent CoT baseline. Our extensive evaluation reveals key strengths and limitations of LVLMs in multi-view reasoning and highlights the value of leveraging both egocentric and exocentric inputs.
Voicing Personas: Rewriting Persona Descriptions into Style Prompts for Controllable Text-to-Speech
May 21, 2025In this paper, we propose a novel framework to control voice style in prompt-based, controllable text-to-speech systems by leveraging textual personas as voice style prompts. We present two persona rewriting strategies to transform generic persona descriptions into speech-oriented prompts, enabling fine-grained manipulation of prosodic attributes such as pitch, emotion, and speaking rate. Experimental results demonstrate that our methods enhance the naturalness, clarity, and consistency of synthesized speech. Finally, we analyze implicit social biases introduced by LLM-based rewriting, with a focus on gender. We underscore voice style as a crucial factor for persona-driven AI dialogue systems.
Visually Guided Decoding: Gradient-Free Hard Prompt Inversion with Language Models
May 13, 2025Text-to-image generative models like DALL-E and Stable Diffusion have revolutionized visual content creation across various applications, including advertising, personalized media, and design prototyping. However, crafting effective textual prompts to guide these models remains challenging, often requiring extensive trial and error. Existing prompt inversion approaches, such as soft and hard prompt techniques, are not so effective due to the limited interpretability and incoherent prompt generation. To address these issues, we propose Visually Guided Decoding (VGD), a gradient-free approach that leverages large language models (LLMs) and CLIP-based guidance to generate coherent and semantically aligned prompts. In essence, VGD utilizes the robust text generation capabilities of LLMs to produce human-readable prompts. Further, by employing CLIP scores to ensure alignment with user-specified visual concepts, VGD enhances the interpretability, generalization, and flexibility of prompt generation without the need for additional training. Our experiments demonstrate that VGD outperforms existing prompt inversion techniques in generating understandable and contextually relevant prompts, facilitating more intuitive and controllable interactions with text-to-image models.
Chain-of-Rank: Enhancing Large Language Models for Domain-Specific RAG in Edge Device
Feb 21, 2025



Retrieval-augmented generation (RAG) with large language models (LLMs) is especially valuable in specialized domains, where precision is critical. To more specialize the LLMs into a target domain, domain-specific RAG has recently been developed by allowing the LLM to access the target domain early via finetuning. The domain-specific RAG makes more sense in resource-constrained environments like edge devices, as they should perform a specific task (e.g. personalization) reliably using only small-scale LLMs. While the domain-specific RAG is well-aligned with edge devices in this respect, it often relies on widely-used reasoning techniques like chain-of-thought (CoT). The reasoning step is useful to understand the given external knowledge, and yet it is computationally expensive and difficult for small-scale LLMs to learn it. Tackling this, we propose the Chain of Rank (CoR) which shifts the focus from intricate lengthy reasoning to simple ranking of the reliability of input external documents. Then, CoR reduces computational complexity while maintaining high accuracy, making it particularly suited for resource-constrained environments. We attain the state-of-the-art (SOTA) results in benchmarks, and analyze its efficacy.
Learning Primitive Relations for Compositional Zero-Shot Learning
Jan 24, 2025Compositional Zero-Shot Learning (CZSL) aims to identify unseen state-object compositions by leveraging knowledge learned from seen compositions. Existing approaches often independently predict states and objects, overlooking their relationships. In this paper, we propose a novel framework, learning primitive relations (LPR), designed to probabilistically capture the relationships between states and objects. By employing the cross-attention mechanism, LPR considers the dependencies between states and objects, enabling the model to infer the likelihood of unseen compositions. Experimental results demonstrate that LPR outperforms state-of-the-art methods on all three CZSL benchmark datasets in both closed-world and open-world settings. Through qualitative analysis, we show that LPR leverages state-object relationships for unseen composition prediction.
Unlocking Transfer Learning for Open-World Few-Shot Recognition
Nov 15, 2024Few-Shot Open-Set Recognition (FSOSR) targets a critical real-world challenge, aiming to categorize inputs into known categories, termed closed-set classes, while identifying open-set inputs that fall outside these classes. Although transfer learning where a model is tuned to a given few-shot task has become a prominent paradigm in closed-world, we observe that it fails to expand to open-world. To unlock this challenge, we propose a two-stage method which consists of open-set aware meta-learning with open-set free transfer learning. In the open-set aware meta-learning stage, a model is trained to establish a metric space that serves as a beneficial starting point for the subsequent stage. During the open-set free transfer learning stage, the model is further adapted to a specific target task through transfer learning. Additionally, we introduce a strategy to simulate open-set examples by modifying the training dataset or generating pseudo open-set examples. The proposed method achieves state-of-the-art performance on two widely recognized benchmarks, miniImageNet and tieredImageNet, with only a 1.5\% increase in training effort. Our work demonstrates the effectiveness of transfer learning in FSOSR.
Preserving Pre-trained Representation Space: On Effectiveness of Prefix-tuning for Large Multi-modal Models
Oct 29, 2024Recently, we have observed that Large Multi-modal Models (LMMs) are revolutionizing the way machines interact with the world, unlocking new possibilities across various multi-modal applications. To adapt LMMs for downstream tasks, parameter-efficient fine-tuning (PEFT) which only trains additional prefix tokens or modules, has gained popularity. Nevertheless, there has been little analysis of how PEFT works in LMMs. In this paper, we delve into the strengths and weaknesses of each tuning strategy, shifting the focus from the efficiency typically associated with these approaches. We first discover that model parameter tuning methods such as LoRA and Adapters distort the feature representation space learned during pre-training and limit the full utilization of pre-trained knowledge. We also demonstrate that prefix-tuning excels at preserving the representation space, despite its lower performance on downstream tasks. These findings suggest a simple two-step PEFT strategy called Prefix-Tuned PEFT (PT-PEFT), which successively performs prefix-tuning and then PEFT (i.e., Adapter, LoRA), combines the benefits of both. Experimental results show that PT-PEFT not only improves performance in image captioning and visual question answering compared to vanilla PEFT methods but also helps preserve the representation space of the four pre-trained models.
Semantic Token Reweighting for Interpretable and Controllable Text Embeddings in CLIP
Oct 11, 2024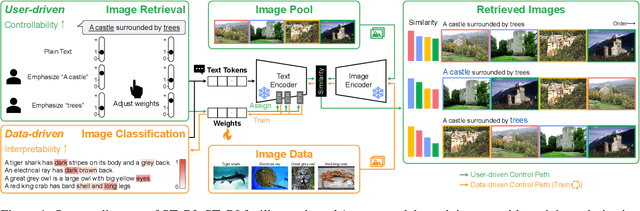
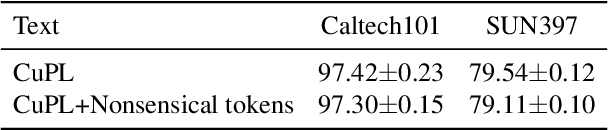

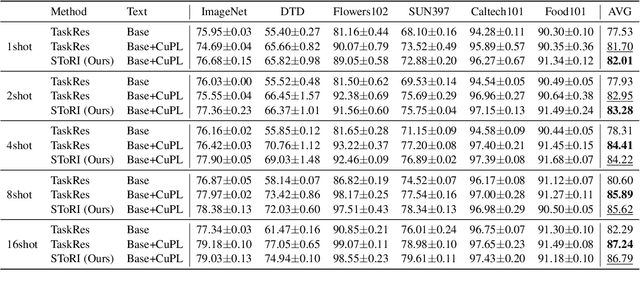
A text encoder within Vision-Language Models (VLMs) like CLIP plays a crucial role in translating textual input into an embedding space shared with images, thereby facilitating the interpretative analysis of vision tasks through natural language. Despite the varying significance of different textual elements within a sentence depending on the context, efforts to account for variation of importance in constructing text embeddings have been lacking. We propose a framework of Semantic Token Reweighting to build Interpretable text embeddings (SToRI), which incorporates controllability as well. SToRI refines the text encoding process in CLIP by differentially weighting semantic elements based on contextual importance, enabling finer control over emphasis responsive to data-driven insights and user preferences. The efficacy of SToRI is demonstrated through comprehensive experiments on few-shot image classification and image retrieval tailored to user preferences.
InfiniPot: Infinite Context Processing on Memory-Constrained LLMs
Oct 02, 2024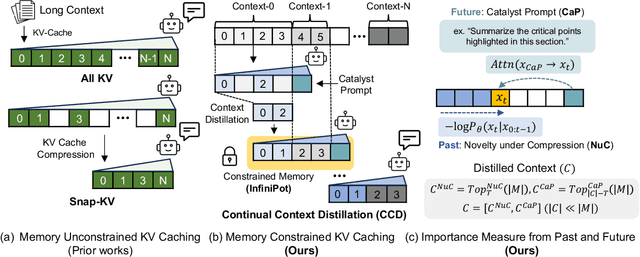
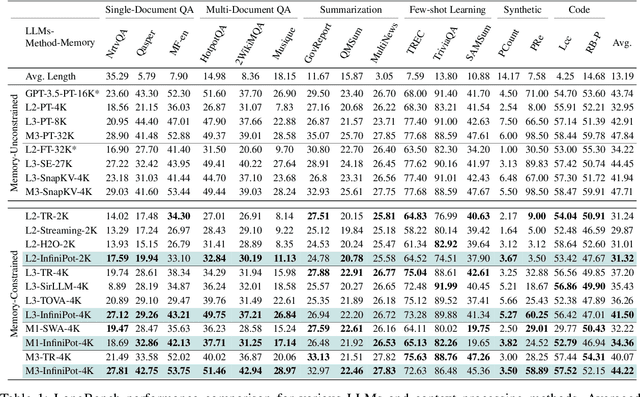
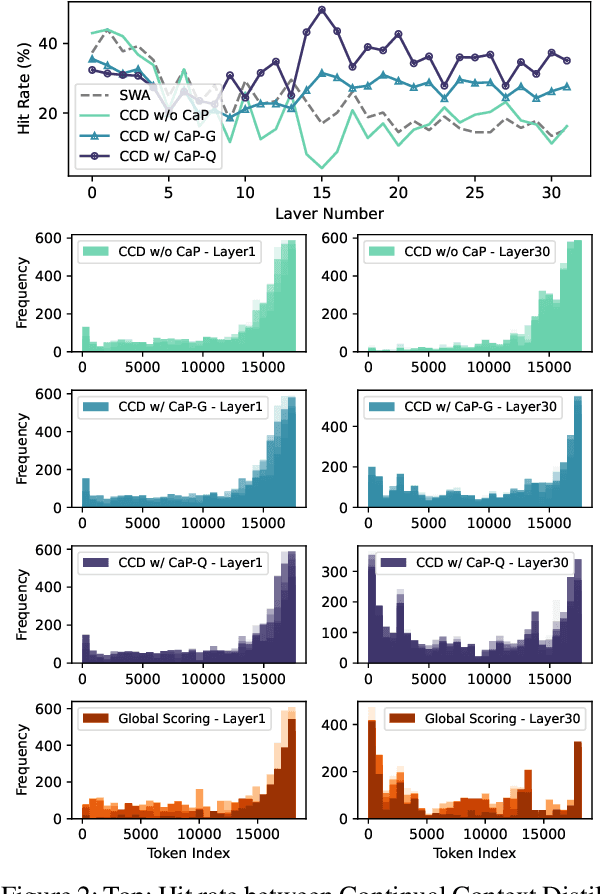
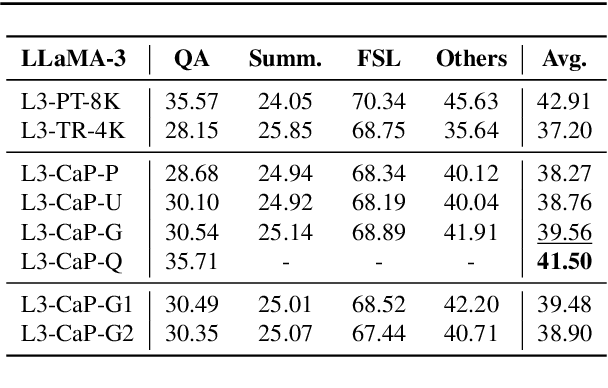
Handling long input contexts remains a significant challenge for Large Language Models (LLMs), particularly in resource-constrained environments such as mobile devices. Our work aims to address this limitation by introducing InfiniPot, a novel KV cache control framework designed to enable pre-trained LLMs to manage extensive sequences within fixed memory constraints efficiently, without requiring additional training. InfiniPot leverages Continual Context Distillation (CCD), an iterative process that compresses and retains essential information through novel importance metrics, effectively maintaining critical data even without access to future context. Our comprehensive evaluations indicate that InfiniPot significantly outperforms models trained for long contexts in various NLP tasks, establishing its efficacy and versatility. This work represents a substantial advancement toward making LLMs applicable to a broader range of real-world scenarios.
Crayon: Customized On-Device LLM via Instant Adapter Blending and Edge-Server Hybrid Inference
Jun 11, 2024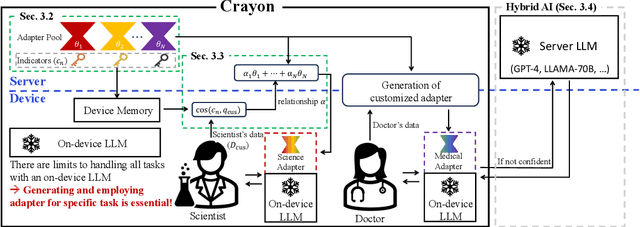
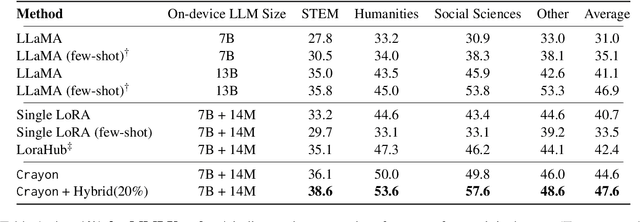
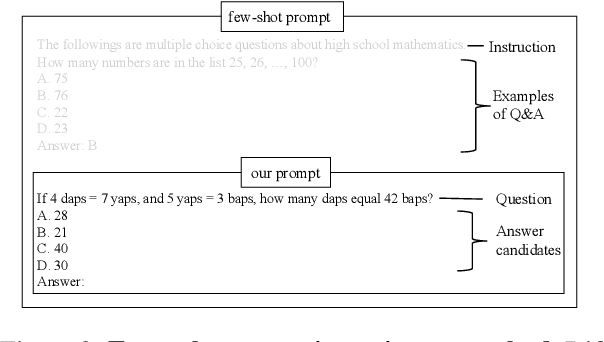
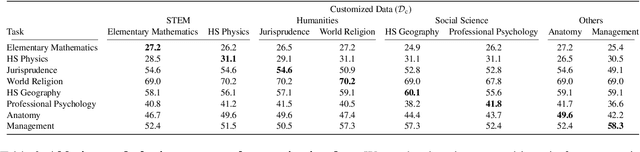
The customization of large language models (LLMs) for user-specified tasks gets important. However, maintaining all the customized LLMs on cloud servers incurs substantial memory and computational overheads, and uploading user data can also lead to privacy concerns. On-device LLMs can offer a promising solution by mitigating these issues. Yet, the performance of on-device LLMs is inherently constrained by the limitations of small-scaled models. To overcome these restrictions, we first propose Crayon, a novel approach for on-device LLM customization. Crayon begins by constructing a pool of diverse base adapters, and then we instantly blend them into a customized adapter without extra training. In addition, we develop a device-server hybrid inference strategy, which deftly allocates more demanding queries or non-customized tasks to a larger, more capable LLM on a server. This ensures optimal performance without sacrificing the benefits of on-device customization. We carefully craft a novel benchmark from multiple question-answer datasets, and show the efficacy of our method in the LLM customization.