 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Multi-Robot Networks via MLLM-Driven Sensing, Communication, and Computation: A Comprehensive Survey
Mar 31, 2026Imagine advanced humanoid robots, powered by multimodal large language models (MLLMs), coordinating missions across industries like warehouse logistics, manufacturing, and safety rescue. While individual robots show local autonomy, realistic tasks demand coordination among multiple agents sharing vast streams of sensor data. Communication is indispensable, yet transmitting comprehensive data can overwhelm networks, especially when a system-level orchestrator or cloud-based MLLM fuses multimodal inputs for route planning or anomaly detection. These tasks are often initiated by high-level natural language instructions. This intent serves as a filter for resource optimization: by understanding the goal via MLLMs, the system can selectively activate relevant sensing modalities, dynamically allocate bandwidth, and determine computation placement. Thus, R2X is fundamentally an intent-to-resource orchestration problem where sensing, communication, and computation are jointly optimized to maximize task-level success under resource constraints. This survey examines how integrated design paves the way for multi-robot coordination under MLLM guidance. We review state-of-the-art sensing modalities, communication strategies, and computing approaches, highlighting how reasoning is split between on-device models and powerful edge/cloud servers. We present four end-to-end demonstrations (sense -> communicate -> compute -> act): (i) digital-twin warehouse navigation with predictive link context, (ii) mobility-driven proactive MCS control, (iii) a FollowMe robot with a semantic-sensing switch, and (iv) real-hardware open-vocabulary trash sorting via edge-assisted MLLM grounding. We emphasize system-level metrics -- payload, latency, and success -- to show why R2X orchestration outperforms purely on-device baselines.
GazeShift: Unsupervised Gaze Estimation and Dataset for VR
Mar 08, 2026Gaze estimation is instrumental in modern virtual reality (VR) systems. Despite significant progress in remote-camera gaze estimation, VR gaze research remains constrained by data scarcity - particularly the lack of large-scale, accurately labeled datasets captured with the off-axis camera configurations typical of modern headsets. Gaze annotation is difficult since fixation on intended targets cannot be guaranteed. To address these challenges, we introduce VRGaze - the first large-scale off-axis gaze estimation dataset for VR - comprising 2.1 million near-eye infrared images collected from 68 participants. We further propose GazeShift, an attention-guided unsupervised framework for learning gaze representations without labeled data. Unlike prior redirection-based methods that rely on multi-view or 3D geometry, GazeShift is tailored to near-eye infrared imagery, achieving effective gaze-appearance disentanglement in a compact, real-time model. GazeShift embeddings can be optionally adapted to individual users via lightweight few-shot calibration, achieving a 1.84-degree mean error on VRGaze. On the remote-camera MPIIGaze dataset, the model achieves a 7.15-degree person-agnostic error, doing so with 10x fewer parameters and 35x fewer FLOPs than baseline methods. Deployed natively on a VR headset GPU, inference takes only 5 ms. Combined with demonstrated robustness to illumination changes, these results highlight GazeShift as a label-efficient, real-time solution for VR gaze tracking. Project code and the VRGaze dataset are released at https://github.com/gazeshift3/gazeshift.
Multimodal Safety Evaluation in Generative Agent Social Simulations
Oct 09, 2025



Can generative agents be trusted in multimodal environments? Despite advances in large language and vision-language models that enable agents to act autonomously and pursue goals in rich settings, their ability to reason about safety, coherence, and trust across modalities remains limited. We introduce a reproducible simulation framework for evaluating agents along three dimensions: (1) safety improvement over time, including iterative plan revisions in text-visual scenarios; (2) detection of unsafe activities across multiple categories of social situations; and (3) social dynamics, measured as interaction counts and acceptance ratios of social exchanges. Agents are equipped with layered memory, dynamic planning, multimodal perception, and are instrumented with SocialMetrics, a suite of behavioral and structural metrics that quantifies plan revisions, unsafe-to-safe conversions, and information diffusion across networks. Experiments show that while agents can detect direct multimodal contradictions, they often fail to align local revisions with global safety, reaching only a 55 percent success rate in correcting unsafe plans. Across eight simulation runs with three models - Claude, GPT-4o mini, and Qwen-VL - five agents achieved average unsafe-to-safe conversion rates of 75, 55, and 58 percent, respectively. Overall performance ranged from 20 percent in multi-risk scenarios with GPT-4o mini to 98 percent in localized contexts such as fire/heat with Claude. Notably, 45 percent of unsafe actions were accepted when paired with misleading visuals, showing a strong tendency to overtrust images. These findings expose critical limitations in current architectures and provide a reproducible platform for studying multimodal safety, coherence, and social dynamics.
Modeling and Control Framework for Autonomous Space Manipulator Handover Operations
Aug 25, 2025Autonomous space robotics is poised to play a vital role in future space missions, particularly for In-space Servicing, Assembly, and Manufacturing (ISAM). A key capability in such missions is the Robot-to-Robot (R2R) handover of mission-critical objects. This work presents a dynamic model of a dual-arm space manipulator system and compares various tracking control laws. The key contributions of this work are the development of a cooperative manipulator dynamic model and the comparative analysis of control laws to support autonomous R2R handovers in ISAM scenarios.
Adapting Biological Reflexes for Dynamic Reorientation in Space Manipulator Systems
Aug 19, 2025Robotic arms mounted on spacecraft, known as space manipulator systems (SMSs), are critical for enabling on-orbit assembly, satellite servicing, and debris removal. However, controlling these systems in microgravity remains a significant challenge due to the dynamic coupling between the manipulator and the spacecraft base. This study explores the potential of using biological inspiration to address this issue, focusing on animals, particularly lizards, that exhibit mid-air righting reflexes. Based on similarities between SMSs and these animals in terms of behavior, morphology, and environment, their air-righting motion trajectories are extracted from high-speed video recordings using computer vision techniques. These trajectories are analyzed within a multi-objective optimization framework to identify the key behavioral goals and assess their relative importance. The resulting motion profiles are then applied as reference trajectories for SMS control, with baseline controllers used to track them. The findings provide a step toward translating evolved animal behaviors into interpretable, adaptive control strategies for space robotics, with implications for improving maneuverability and robustness in future missions.
Visually Guided Decoding: Gradient-Free Hard Prompt Inversion with Language Models
May 13, 2025Text-to-image generative models like DALL-E and Stable Diffusion have revolutionized visual content creation across various applications, including advertising, personalized media, and design prototyping. However, crafting effective textual prompts to guide these models remains challenging, often requiring extensive trial and error. Existing prompt inversion approaches, such as soft and hard prompt techniques, are not so effective due to the limited interpretability and incoherent prompt generation. To address these issues, we propose Visually Guided Decoding (VGD), a gradient-free approach that leverages large language models (LLMs) and CLIP-based guidance to generate coherent and semantically aligned prompts. In essence, VGD utilizes the robust text generation capabilities of LLMs to produce human-readable prompts. Further, by employing CLIP scores to ensure alignment with user-specified visual concepts, VGD enhances the interpretability, generalization, and flexibility of prompt generation without the need for additional training. Our experiments demonstrate that VGD outperforms existing prompt inversion techniques in generating understandable and contextually relevant prompts, facilitating more intuitive and controllable interactions with text-to-image models.
Study on Real-Time Road Surface Reconstruction Using Stereo Vision
Apr 25, 2025

Road surface reconstruction plays a crucial role in autonomous driving, providing essential information for safe and smooth navigation. This paper enhances the RoadBEV [1] framework for real-time inference on edge devices by optimizing both efficiency and accuracy. To achieve this, we proposed to apply Isomorphic Global Structured Pruning to the stereo feature extraction backbone, reducing network complexity while maintaining performance. Additionally, the head network is redesigned with an optimized hourglass structure, dynamic attention heads, reduced feature channels, mixed precision inference, and efficient probability volume computation. Our approach improves inference speed while achieving lower reconstruction error, making it well-suited for real-time road surface reconstruction in autonomous driving.
Deep Learning-Based Prediction of PET Amyloid Status Using Multi-Contrast MRI
Nov 18, 2024



Identifying amyloid-beta positive patients is crucial for determining eligibility for Alzheimer's disease (AD) clinical trials and new disease-modifying treatments, but currently requires PET or CSF sampling. Previous MRI-based deep learning models for predicting amyloid positivity, using only T1w sequences, have shown moderate performance. We trained deep learning models to predict amyloid PET positivity and evaluated whether multi-contrast inputs improve performance. A total of 4,058 exams with multi-contrast MRI and PET-based quantitative amyloid deposition were obtained from three public datasets: the Alzheimer's Disease Neuroimaging Initiative (ADNI), the Open Access Series of Imaging Studies 3 (OASIS3), and the Anti-Amyloid Treatment in Asymptomatic Alzheimer's Disease (A4). Two separate EfficientNet models were trained for amyloid positivity prediction: one with only T1w images and the other with both T1w and T2-FLAIR images as network inputs. The area under the curve (AUC), accuracy, sensitivity, and specificity were determined using an internal held-out test set. The trained models were further evaluated using an external test set. In the held-out test sets, the T1w and T1w+T2FLAIR models demonstrated AUCs of 0.62 (95% CI: 0.60, 0.64) and 0.67 (95% CI: 0.64, 0.70) (p = 0.006); accuracies were 61% (95% CI: 60%, 63%) and 64% (95% CI: 62%, 66%) (p = 0.008); sensitivities were 0.88 and 0.71; and specificities were 0.23 and 0.53, respectively. The trained models showed similar performance in the external test set. Performance of the current model on both test sets exceeded that of the publicly available model. In conclusion, the use of multi-contrast MRI, specifically incorporating T2-FLAIR in addition to T1w images, significantly improved the predictive accuracy of PET-determined amyloid status from MRI scans using a deep learning approach.
Preserving Pre-trained Representation Space: On Effectiveness of Prefix-tuning for Large Multi-modal Models
Oct 29, 2024

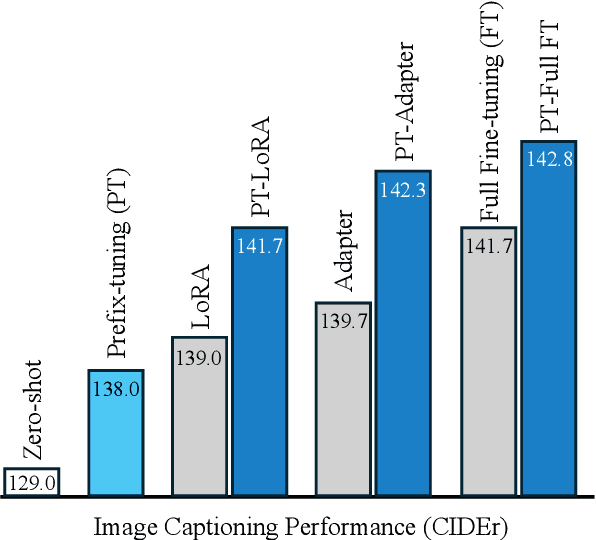

Recently, we have observed that Large Multi-modal Models (LMMs) are revolutionizing the way machines interact with the world, unlocking new possibilities across various multi-modal applications. To adapt LMMs for downstream tasks, parameter-efficient fine-tuning (PEFT) which only trains additional prefix tokens or modules, has gained popularity. Nevertheless, there has been little analysis of how PEFT works in LMMs. In this paper, we delve into the strengths and weaknesses of each tuning strategy, shifting the focus from the efficiency typically associated with these approaches. We first discover that model parameter tuning methods such as LoRA and Adapters distort the feature representation space learned during pre-training and limit the full utilization of pre-trained knowledge. We also demonstrate that prefix-tuning excels at preserving the representation space, despite its lower performance on downstream tasks. These findings suggest a simple two-step PEFT strategy called Prefix-Tuned PEFT (PT-PEFT), which successively performs prefix-tuning and then PEFT (i.e., Adapter, LoRA), combines the benefits of both. Experimental results show that PT-PEFT not only improves performance in image captioning and visual question answering compared to vanilla PEFT methods but also helps preserve the representation space of the four pre-trained models.
Offline Policy Learning via Skill-step Abstraction for Long-horizon Goal-Conditioned Tasks
Aug 21, 2024



Goal-conditioned (GC) policy learning often faces a challenge arising from the sparsity of rewards, when confronting long-horizon goals. To address the challenge, we explore skill-based GC policy learning in offline settings, where skills are acquired from existing data and long-horizon goals are decomposed into sequences of near-term goals that align with these skills. Specifically, we present an `offline GC policy learning via skill-step abstraction' framework (GLvSA) tailored for tackling long-horizon GC tasks affected by goal distribution shifts. In the framework, a GC policy is progressively learned offline in conjunction with the incremental modeling of skill-step abstractions on the data. We also devise a GC policy hierarchy that not only accelerates GC policy learning within the framework but also allows for parameter-efficient fine-tuning of the policy. Through experiments with the maze and Franka kitchen environments, we demonstrate the superiority and efficiency of our GLvSA framework in adapting GC policies to a wide range of long-horizon goals. The framework achieves competitive zero-shot and few-shot adaptation performance, outperforming existing GC policy learning and skill-based methods.