 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Multi-Robot Networks via MLLM-Driven Sensing, Communication, and Computation: A Comprehensive Survey
Mar 31, 2026Imagine advanced humanoid robots, powered by multimodal large language models (MLLMs), coordinating missions across industries like warehouse logistics, manufacturing, and safety rescue. While individual robots show local autonomy, realistic tasks demand coordination among multiple agents sharing vast streams of sensor data. Communication is indispensable, yet transmitting comprehensive data can overwhelm networks, especially when a system-level orchestrator or cloud-based MLLM fuses multimodal inputs for route planning or anomaly detection. These tasks are often initiated by high-level natural language instructions. This intent serves as a filter for resource optimization: by understanding the goal via MLLMs, the system can selectively activate relevant sensing modalities, dynamically allocate bandwidth, and determine computation placement. Thus, R2X is fundamentally an intent-to-resource orchestration problem where sensing, communication, and computation are jointly optimized to maximize task-level success under resource constraints. This survey examines how integrated design paves the way for multi-robot coordination under MLLM guidance. We review state-of-the-art sensing modalities, communication strategies, and computing approaches, highlighting how reasoning is split between on-device models and powerful edge/cloud servers. We present four end-to-end demonstrations (sense -> communicate -> compute -> act): (i) digital-twin warehouse navigation with predictive link context, (ii) mobility-driven proactive MCS control, (iii) a FollowMe robot with a semantic-sensing switch, and (iv) real-hardware open-vocabulary trash sorting via edge-assisted MLLM grounding. We emphasize system-level metrics -- payload, latency, and success -- to show why R2X orchestration outperforms purely on-device baselines.
Revealing Multi-View Hallucination in Large Vision-Language Models
Mar 25, 2026Large vision-language models (LVLMs) are increasingly being applied to multi-view image inputs captured from diverse viewpoints. However, despite this growing use, current LVLMs often confuse or mismatch visual information originating from different instances or viewpoints, a phenomenon we term multi-view hallucination. To systematically analyze this problem, we construct MVH-Bench, a benchmark comprising 4.8k question-answer pairs targeting two types of hallucination: cross-instance and cross-view. Empirical results show that recent LVLMs struggle to correctly associate visual evidence with its corresponding instance or viewpoint. To overcome this limitation, we propose Reference Shift Contrastive Decoding (RSCD), a training-free decoding technique that suppresses visual interference by generating negative logits through attention masking. Experiments on MVH-Bench with Qwen2.5-VL and LLaVA-OneVision demonstrate that RSCD consistently improves performance by up to 21.1 and 34.6 points over existing hallucination mitigation methods, highlighting the effectiveness of our approach.
Large Multimodal Models-Empowered Task-Oriented Autonomous Communications: Design Methodology and Implementation Challenges
Oct 23, 2025Large language models (LLMs) and large multimodal models (LMMs) have achieved unprecedented breakthrough, showcasing remarkable capabilities in natural language understanding, generation, and complex reasoning. This transformative potential has positioned them as key enablers for 6G autonomous communications among machines, vehicles, and humanoids. In this article, we provide an overview of task-oriented autonomous communications with LLMs/LMMs, focusing on multimodal sensing integration, adaptive reconfiguration, and prompt/fine-tuning strategies for wireless tasks. We demonstrate the framework through three case studies: LMM-based traffic control, LLM-based robot scheduling, and LMM-based environment-aware channel estimation. From experimental results, we show that the proposed LLM/LMM-aided autonomous systems significantly outperform conventional and discriminative deep learning (DL) model-based techniques, maintaining robustness under dynamic objectives, varying input parameters, and heterogeneous multimodal conditions where conventional static optimization degrades.
Blind Channel Estimation for RIS-Assisted Millimeter Wave Communication Systems
Aug 25, 2025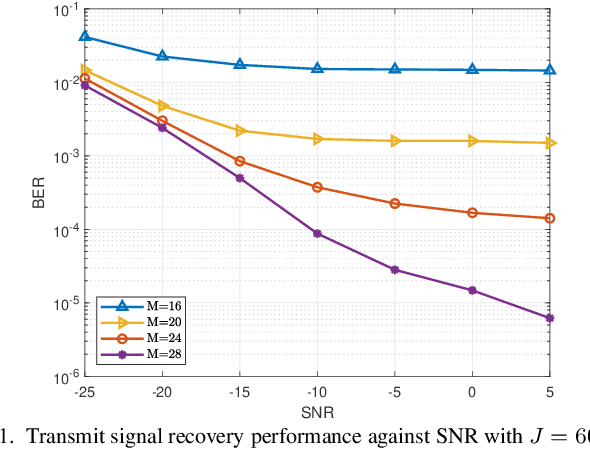
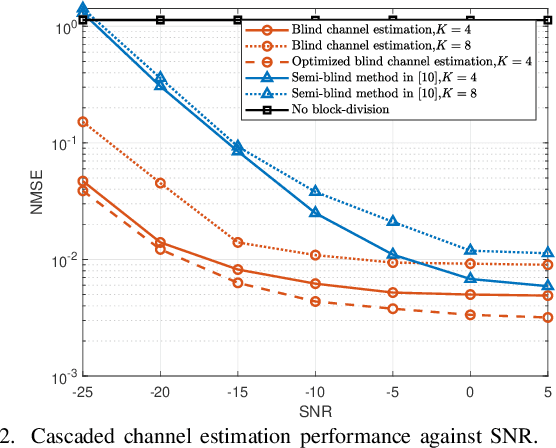

In the research of RIS-assisted communication systems, channel estimation is a problem of vital importance for further performance optimization. In order to reduce the pilot overhead to the greatest extent, blind channel estimation methods are required, which can estimate the channel and the transmit signals at the same time without transmitting pilot sequence. Different from existing researches in traditional MIMO systems, the RIS-assisted two-hop channel brings new challenges to the blind channel estimation design. Hence, a novel blind channel estimation method based on compressed sensing for RIS-assisted multiuser millimeter wave communication systems is proposed for the first time in this paper. Specifically, for accurately estimating the RIS-assisted two-hop channel without transmitting pilots, we propose a block-wise transmission scheme. Among different blocks of data transmission, RIS elements are reconfigured for better estimating the cascade channel. Inside each block, data for each user are mapped to a codeword for realizing the transmit signal recovery and equivalent channel estimation simultaneously. Simulation results demonstrate that our method can achieve a considerable accuracy of channel estimation and transmit signal recovery.
Towards Comprehensive Scene Understanding: Integrating First and Third-Person Views for LVLMs
May 28, 2025



Large vision-language models (LVLMs) are increasingly deployed in interactive applications such as virtual and augmented reality, where first-person (egocentric) view captured by head-mounted cameras serves as key input. While this view offers fine-grained cues about user attention and hand-object interactions, their narrow field of view and lack of global context often lead to failures on spatially or contextually demanding queries. To address this, we introduce a framework that augments egocentric inputs with third-person (exocentric) views, providing complementary information such as global scene layout and object visibility to LVLMs. We present E3VQA, the first benchmark for multi-view question answering with 4K high-quality question-answer pairs grounded in synchronized ego-exo image pairs. Additionally, we propose M3CoT, a training-free prompting technique that constructs a unified scene representation by integrating scene graphs from three complementary perspectives. M3CoT enables LVLMs to reason more effectively across views, yielding consistent performance gains (4.84% for GPT-4o and 5.94% for Gemini 2.0 Flash) over a recent CoT baseline. Our extensive evaluation reveals key strengths and limitations of LVLMs in multi-view reasoning and highlights the value of leveraging both egocentric and exocentric inputs.
Visually Guided Decoding: Gradient-Free Hard Prompt Inversion with Language Models
May 13, 2025Text-to-image generative models like DALL-E and Stable Diffusion have revolutionized visual content creation across various applications, including advertising, personalized media, and design prototyping. However, crafting effective textual prompts to guide these models remains challenging, often requiring extensive trial and error. Existing prompt inversion approaches, such as soft and hard prompt techniques, are not so effective due to the limited interpretability and incoherent prompt generation. To address these issues, we propose Visually Guided Decoding (VGD), a gradient-free approach that leverages large language models (LLMs) and CLIP-based guidance to generate coherent and semantically aligned prompts. In essence, VGD utilizes the robust text generation capabilities of LLMs to produce human-readable prompts. Further, by employing CLIP scores to ensure alignment with user-specified visual concepts, VGD enhances the interpretability, generalization, and flexibility of prompt generation without the need for additional training. Our experiments demonstrate that VGD outperforms existing prompt inversion techniques in generating understandable and contextually relevant prompts, facilitating more intuitive and controllable interactions with text-to-image models.
Adaptive Resource Allocation Optimization Using Large Language Models in Dynamic Wireless Environments
Feb 04, 2025
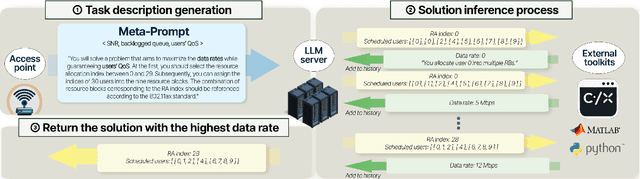

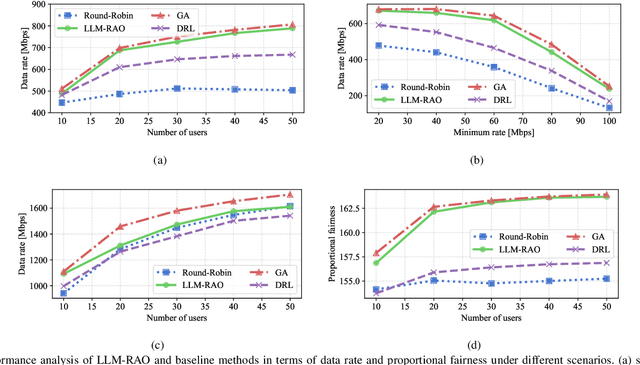
Deep learning (DL) has made notable progress in addressing complex radio access network control challenges that conventional analytic methods have struggled to solve. However, DL has shown limitations in solving constrained NP-hard problems often encountered in network optimization, such as those involving quality of service (QoS) or discrete variables like user indices. Current solutions rely on domain-specific architectures or heuristic techniques, and a general DL approach for constrained optimization remains undeveloped. Moreover, even minor changes in communication objectives demand time-consuming retraining, limiting their adaptability to dynamic environments where task objectives, constraints, environmental factors, and communication scenarios frequently change. To address these challenges, we propose a large language model for resource allocation optimizer (LLM-RAO), a novel approach that harnesses the capabilities of LLMs to address the complex resource allocation problem while adhering to QoS constraints. By employing a prompt-based tuning strategy to flexibly convey ever-changing task descriptions and requirements to the LLM, LLM-RAO demonstrates robust performance and seamless adaptability in dynamic environments without requiring extensive retraining. Simulation results reveal that LLM-RAO achieves up to a 40% performance enhancement compared to conventional DL methods and up to an $80$\% improvement over analytical approaches. Moreover, in scenarios with fluctuating communication objectives, LLM-RAO attains up to 2.9 times the performance of traditional DL-based networks.
Learning Primitive Relations for Compositional Zero-Shot Learning
Jan 24, 2025


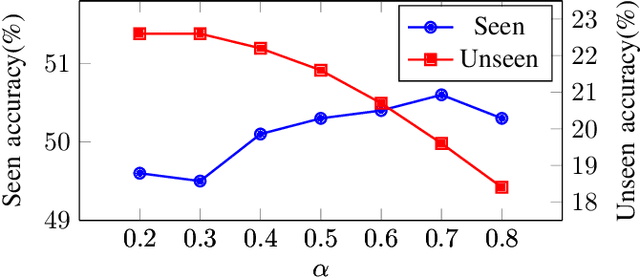
Compositional Zero-Shot Learning (CZSL) aims to identify unseen state-object compositions by leveraging knowledge learned from seen compositions. Existing approaches often independently predict states and objects, overlooking their relationships. In this paper, we propose a novel framework, learning primitive relations (LPR), designed to probabilistically capture the relationships between states and objects. By employing the cross-attention mechanism, LPR considers the dependencies between states and objects, enabling the model to infer the likelihood of unseen compositions. Experimental results demonstrate that LPR outperforms state-of-the-art methods on all three CZSL benchmark datasets in both closed-world and open-world settings. Through qualitative analysis, we show that LPR leverages state-object relationships for unseen composition prediction.
Preserving Pre-trained Representation Space: On Effectiveness of Prefix-tuning for Large Multi-modal Models
Oct 29, 2024

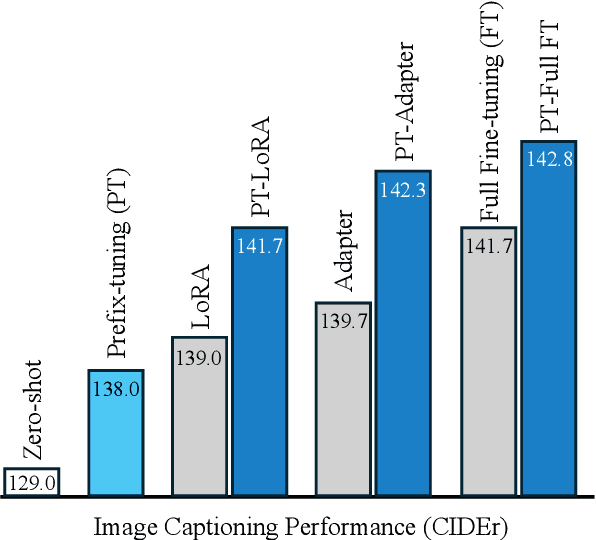

Recently, we have observed that Large Multi-modal Models (LMMs) are revolutionizing the way machines interact with the world, unlocking new possibilities across various multi-modal applications. To adapt LMMs for downstream tasks, parameter-efficient fine-tuning (PEFT) which only trains additional prefix tokens or modules, has gained popularity. Nevertheless, there has been little analysis of how PEFT works in LMMs. In this paper, we delve into the strengths and weaknesses of each tuning strategy, shifting the focus from the efficiency typically associated with these approaches. We first discover that model parameter tuning methods such as LoRA and Adapters distort the feature representation space learned during pre-training and limit the full utilization of pre-trained knowledge. We also demonstrate that prefix-tuning excels at preserving the representation space, despite its lower performance on downstream tasks. These findings suggest a simple two-step PEFT strategy called Prefix-Tuned PEFT (PT-PEFT), which successively performs prefix-tuning and then PEFT (i.e., Adapter, LoRA), combines the benefits of both. Experimental results show that PT-PEFT not only improves performance in image captioning and visual question answering compared to vanilla PEFT methods but also helps preserve the representation space of the four pre-trained models.
Transformer-assisted Parametric CSI Feedback for mmWave Massive MIMO Systems
Oct 09, 2024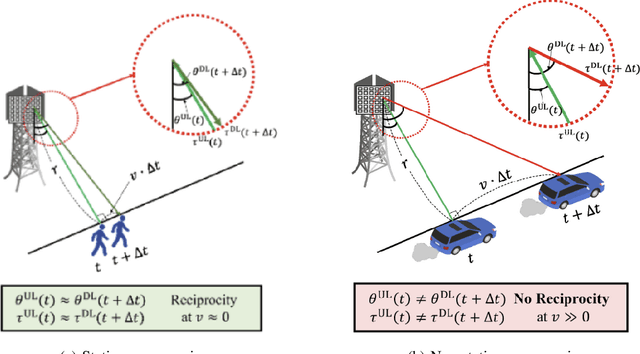
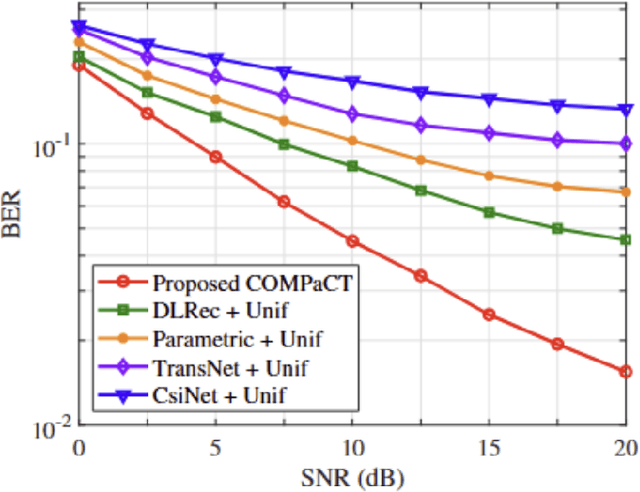
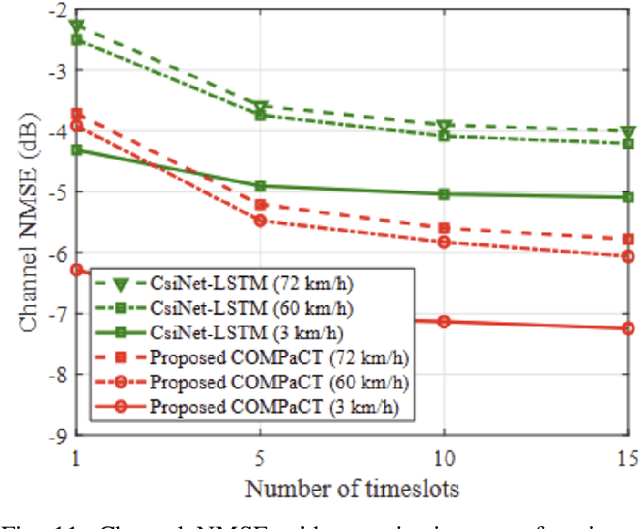
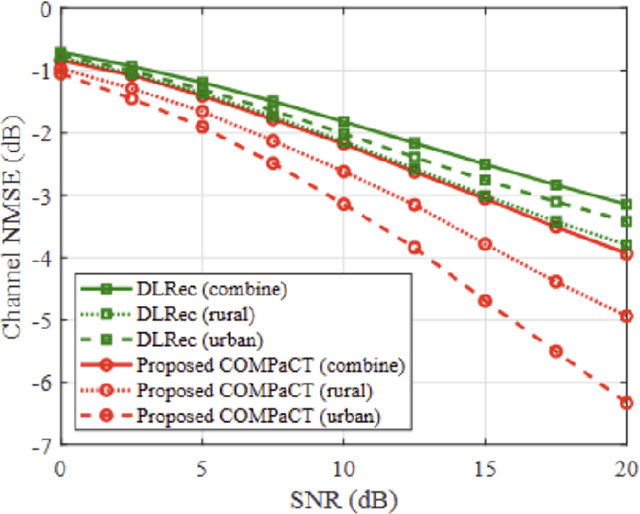
As a key technology to meet the ever-increasing data rate demand in beyond 5G and 6G communications, millimeter-wave (mmWave) massive multiple-input multiple-output (MIMO) systems have gained much attention recently.To make the most of mmWave massive MIMO systems, acquisition of accurate channel state information (CSI) at the base station (BS) is crucial. However, this task is by no means easy due to the CSI feedback overhead induced by the large number of antennas. In this paper, we propose a parametric CSI feedback technique for mmWave massive MIMO systems. Key idea of the proposed technique is to compress the mmWave MIMO channel matrix into a few geometric channel parameters (e.g., angles, delays, and path gains). Due to the limited scattering of mmWave signal, the number of channel parameters is much smaller than the number of antennas, thereby reducing the CSI feedback overhead significantly. Moreover, by exploiting the deep learning (DL) technique for the channel parameter extraction and the MIMO channel reconstruction, we can effectively suppress the channel quantization error. From the numerical results, we demonstrate that the proposed technique outperforms the conventional CSI feedback techniques in terms of normalized mean square error (NMSE) and bit error rate (BER).