 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Primitive Relations for Compositional Zero-Shot Learning
Jan 24, 2025Compositional Zero-Shot Learning (CZSL) aims to identify unseen state-object compositions by leveraging knowledge learned from seen compositions. Existing approaches often independently predict states and objects, overlooking their relationships. In this paper, we propose a novel framework, learning primitive relations (LPR), designed to probabilistically capture the relationships between states and objects. By employing the cross-attention mechanism, LPR considers the dependencies between states and objects, enabling the model to infer the likelihood of unseen compositions. Experimental results demonstrate that LPR outperforms state-of-the-art methods on all three CZSL benchmark datasets in both closed-world and open-world settings. Through qualitative analysis, we show that LPR leverages state-object relationships for unseen composition prediction.
Variational Distribution Learning for Unsupervised Text-to-Image Generation
Mar 28, 2023



We propose a text-to-image generation algorithm based on deep neural networks when text captions for images are unavailable during training. In this work, instead of simply generating pseudo-ground-truth sentences of training images using existing image captioning methods, we employ a pretrained CLIP model, which is capable of properly aligning embeddings of images and corresponding texts in a joint space and, consequently, works well on zero-shot recognition tasks. We optimize a text-to-image generation model by maximizing the data log-likelihood conditioned on pairs of image-text CLIP embeddings. To better align data in the two domains, we employ a principled way based on a variational inference, which efficiently estimates an approximate posterior of the hidden text embedding given an image and its CLIP feature. Experimental results validate that the proposed framework outperforms existing approaches by large margins under unsupervised and semi-supervised text-to-image generation settings.
Vision Transformer-based Feature Extraction for Generalized Zero-Shot Learning
Feb 02, 2023Generalized zero-shot learning (GZSL) is a technique to train a deep learning model to identify unseen classes using the image attribute. In this paper, we put forth a new GZSL approach exploiting Vision Transformer (ViT) to maximize the attribute-related information contained in the image feature. In ViT, the entire image region is processed without the degradation of the image resolution and the local image information is preserved in patch features. To fully enjoy these benefits of ViT, we exploit patch features as well as the CLS feature in extracting the attribute-related image feature. In particular, we propose a novel attention-based module, called attribute attention module (AAM), to aggregate the attribute-related information in patch features. In AAM, the correlation between each patch feature and the synthetic image attribute is used as the importance weight for each patch. From extensive experiments on benchmark datasets, we demonstrate that the proposed technique outperforms the state-of-the-art GZSL approaches by a large margin.
Smooth-Swap: A Simple Enhancement for Face-Swapping with Smoothness
Dec 11, 2021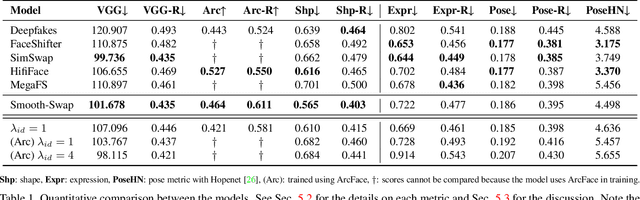
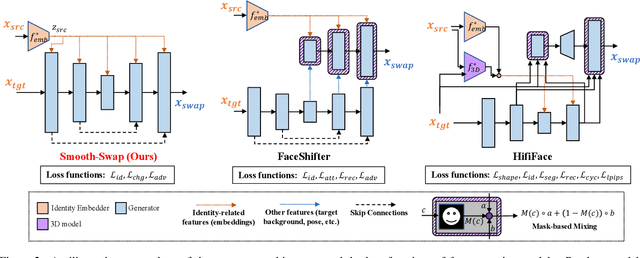
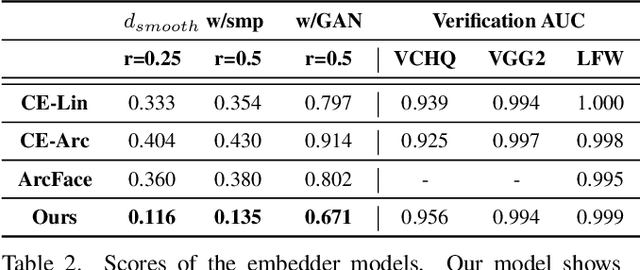
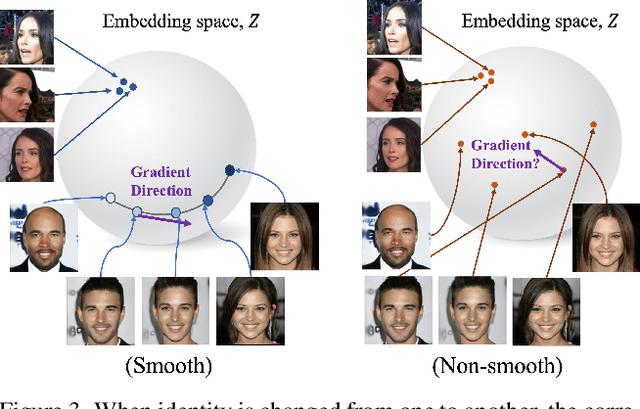
In recent years, face-swapping models have progressed in generation quality and drawn attention for their applications in privacy protection and entertainment. However, their complex architectures and loss functions often require careful tuning for successful training. In this paper, we propose a new face-swapping model called `Smooth-Swap', which focuses on deriving the smoothness of the identity embedding instead of employing complex handcrafted designs. We postulate that the gist of the difficulty in face-swapping is unstable gradients and it can be resolved by a smooth identity embedder. Smooth-swap adopts an embedder trained using supervised contrastive learning, where we find its improved smoothness allows faster and stable training even with a simple U-Net-based generator and three basic loss functions. Extensive experiments on face-swapping benchmarks (FFHQ, FaceForensics++) and face images in the wild show that our model is also quantitatively and qualitatively comparable or even superior to existing methods in terms of identity change.
Encoder-Powered Generative Adversarial Networks
Jun 03, 2019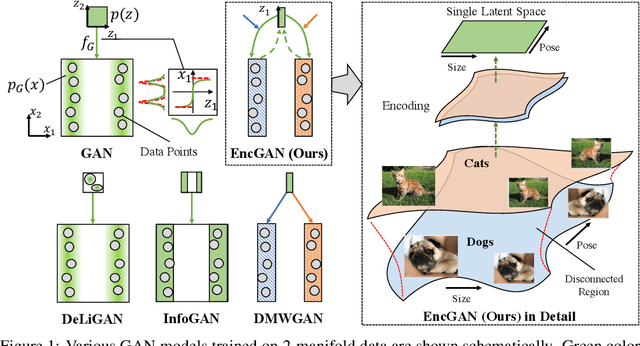
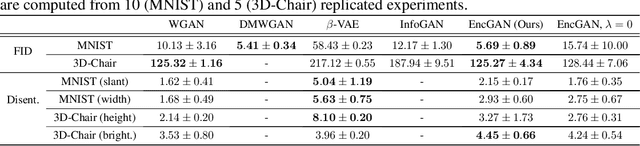
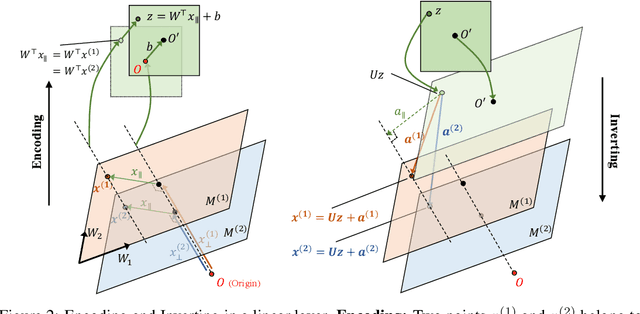
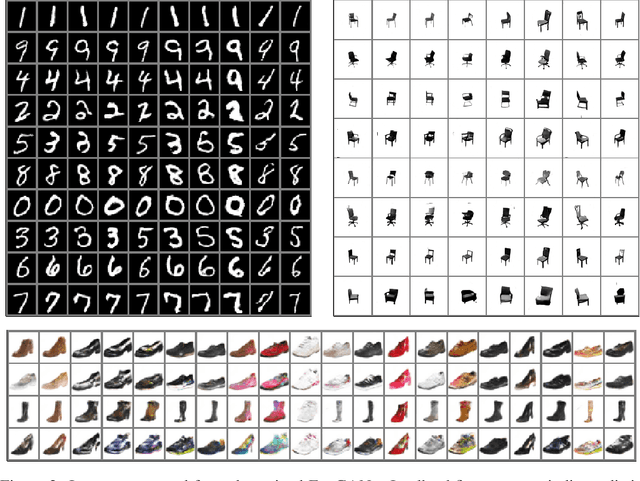
We present an encoder-powered generative adversarial network (EncGAN) that is able to learn both the multi-manifold structure and the abstract features of data. Unlike the conventional decoder-based GANs, EncGAN uses an encoder to model the manifold structure and invert the encoder to generate data. This unique scheme enables the proposed model to exclude discrete features from the smooth structure modeling and learn multi-manifold data without being hindered by the disconnections. Also, as EncGAN requires a single latent space to carry the information for all the manifolds, it builds abstract features shared among the manifolds in the latent space. For an efficient computation, we formulate EncGAN using a simple regularizer, and mathematically prove its validity. We also experimentally demonstrate that EncGAN successfully learns the multi-manifold structure and the abstract features of MNIST, 3D-chair and UT-Zap50k datasets. Our analysis shows that the learned abstract features are disentangled and make a good style-transfer even when the source data is off the trained distribution.
Data Interpolations in Deep Generative Models under Non-Simply-Connected Manifold Topology
Jan 20, 2019
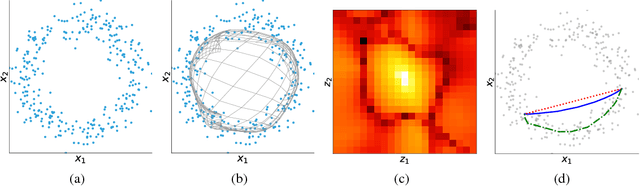


Exploiting the deep generative model's remarkable ability of learning the data-manifold structure, some recent researches proposed a geometric data interpolation method based on the geodesic curves on the learned data-manifold. However, this interpolation method often gives poor results due to a topological difference between the model and the dataset. The model defines a family of simply-connected manifolds, whereas the dataset generally contains disconnected regions or holes that make them non-simply-connected. To compensate this difference, we propose a novel density regularizer that make the interpolation path circumvent the holes denoted by low probability density. We confirm that our method gives consistently better interpolation results from the experiments with real-world image datasets.