 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocality-aware Concept Bottleneck Model
Aug 20, 2025Concept bottleneck models (CBMs) are inherently interpretable models that make predictions based on human-understandable visual cues, referred to as concepts. As obtaining dense concept annotations with human labeling is demanding and costly, recent approaches utilize foundation models to determine the concepts existing in the images. However, such label-free CBMs often fail to localize concepts in relevant regions, attending to visually unrelated regions when predicting concept presence. To this end, we propose a framework, coined Locality-aware Concept Bottleneck Model (LCBM), which utilizes rich information from foundation models and adopts prototype learning to ensure accurate spatial localization of the concepts. Specifically, we assign one prototype to each concept, promoted to represent a prototypical image feature of that concept. These prototypes are learned by encouraging them to encode similar local regions, leveraging foundation models to assure the relevance of each prototype to its associated concept. Then we use the prototypes to facilitate the learning process of identifying the proper local region from which each concept should be predicted. Experimental results demonstrate that LCBM effectively identifies present concepts in the images and exhibits improved localization while maintaining comparable classification performance.
Towards Spatially Consistent Image Generation: On Incorporating Intrinsic Scene Properties into Diffusion Models
Aug 14, 2025Image generation models trained on large datasets can synthesize high-quality images but often produce spatially inconsistent and distorted images due to limited information about the underlying structures and spatial layouts. In this work, we leverage intrinsic scene properties (e.g., depth, segmentation maps) that provide rich information about the underlying scene, unlike prior approaches that solely rely on image-text pairs or use intrinsics as conditional inputs. Our approach aims to co-generate both images and their corresponding intrinsics, enabling the model to implicitly capture the underlying scene structure and generate more spatially consistent and realistic images. Specifically, we first extract rich intrinsic scene properties from a large image dataset with pre-trained estimators, eliminating the need for additional scene information or explicit 3D representations. We then aggregate various intrinsic scene properties into a single latent variable using an autoencoder. Building upon pre-trained large-scale Latent Diffusion Models (LDMs), our method simultaneously denoises the image and intrinsic domains by carefully sharing mutual information so that the image and intrinsic reflect each other without degrading image quality. Experimental results demonstrate that our method corrects spatial inconsistencies and produces a more natural layout of scenes while maintaining the fidelity and textual alignment of the base model (e.g., Stable Diffusion).
DUEL: Duplicate Elimination on Active Memory for Self-Supervised Class-Imbalanced Learning
Feb 14, 2024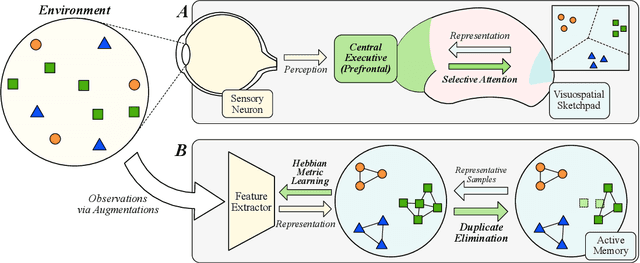
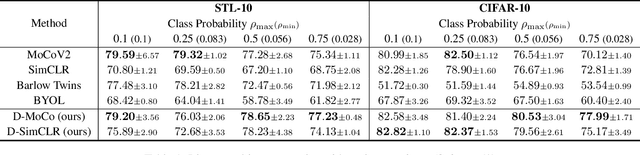
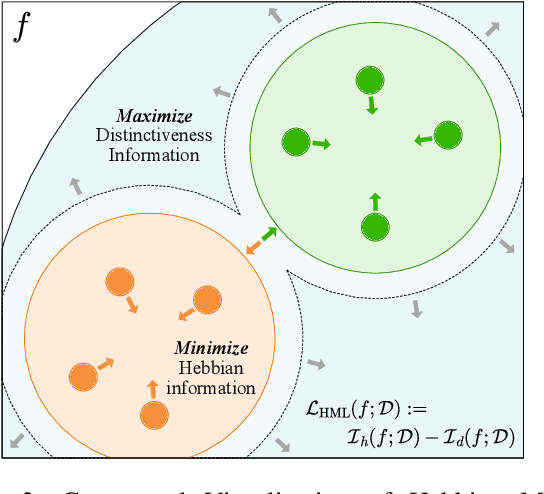
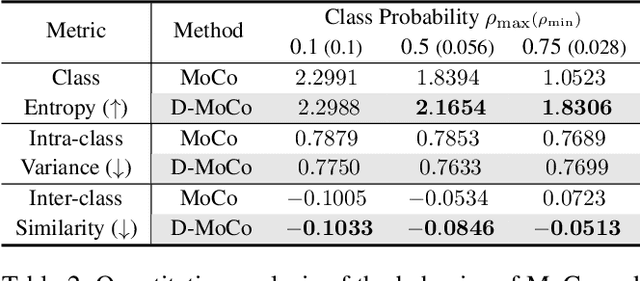
Recent machine learning algorithms have been developed using well-curated datasets, which often require substantial cost and resources. On the other hand, the direct use of raw data often leads to overfitting towards frequently occurring class information. To address class imbalances cost-efficiently, we propose an active data filtering process during self-supervised pre-training in our novel framework, Duplicate Elimination (DUEL). This framework integrates an active memory inspired by human working memory and introduces distinctiveness information, which measures the diversity of the data in the memory, to optimize both the feature extractor and the memory. The DUEL policy, which replaces the most duplicated data with new samples, aims to enhance the distinctiveness information in the memory and thereby mitigate class imbalances. We validate the effectiveness of the DUEL framework in class-imbalanced environments, demonstrating its robustness and providing reliable results in downstream tasks. We also analyze the role of the DUEL policy in the training process through various metrics and visualizations.
L-SA: Learning Under-Explored Targets in Multi-Target Reinforcement Learning
May 23, 2023



Tasks that involve interaction with various targets are called multi-target tasks. When applying general reinforcement learning approaches for such tasks, certain targets that are difficult to access or interact with may be neglected throughout the course of training - a predicament we call Under-explored Target Problem (UTP). To address this problem, we propose L-SA (Learning by adaptive Sampling and Active querying) framework that includes adaptive sampling and active querying. In the L-SA framework, adaptive sampling dynamically samples targets with the highest increase of success rates at a high proportion, resulting in curricular learning from easy to hard targets. Active querying prompts the agent to interact more frequently with under-explored targets that need more experience or exploration. Our experimental results on visual navigation tasks show that the L-SA framework improves sample efficiency as well as success rates on various multi-target tasks with UTP. Also, it is experimentally demonstrated that the cyclic relationship between adaptive sampling and active querying effectively improves the sample richness of under-explored targets and alleviates UTP.
Learning Geometry-aware Representations by Sketching
Apr 17, 2023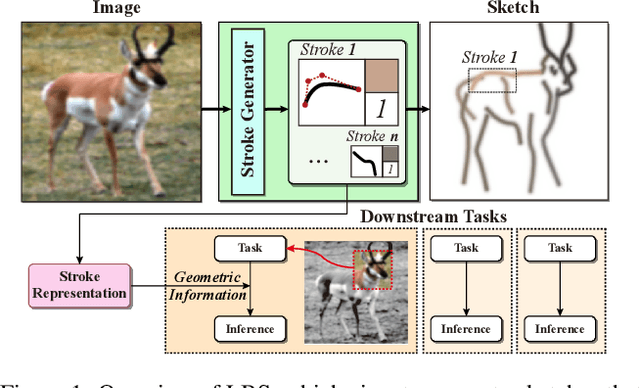
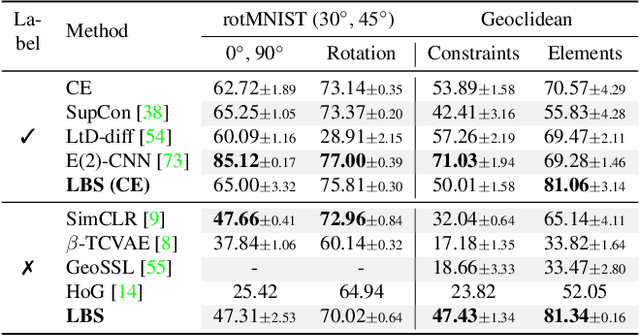
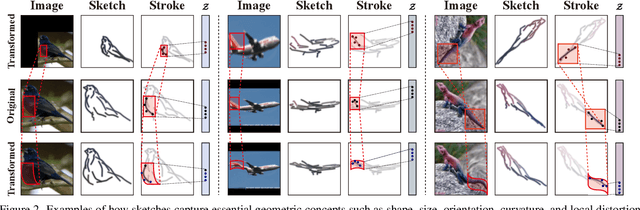
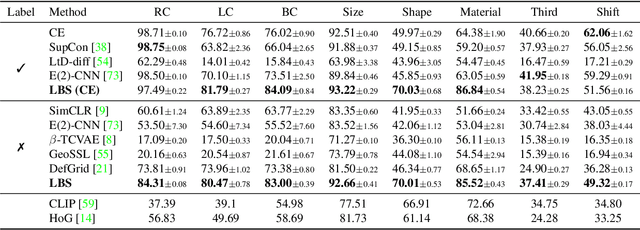
Understanding geometric concepts, such as distance and shape, is essential for understanding the real world and also for many vision tasks. To incorporate such information into a visual representation of a scene, we propose learning to represent the scene by sketching, inspired by human behavior. Our method, coined Learning by Sketching (LBS), learns to convert an image into a set of colored strokes that explicitly incorporate the geometric information of the scene in a single inference step without requiring a sketch dataset. A sketch is then generated from the strokes where CLIP-based perceptual loss maintains a semantic similarity between the sketch and the image. We show theoretically that sketching is equivariant with respect to arbitrary affine transformations and thus provably preserves geometric information. Experimental results show that LBS substantially improves the performance of object attribute classification on the unlabeled CLEVR dataset, domain transfer between CLEVR and STL-10 datasets, and for diverse downstream tasks, confirming that LBS provides rich geometric information.
DUEL: Adaptive Duplicate Elimination on Working Memory for Self-Supervised Learning
Oct 31, 2022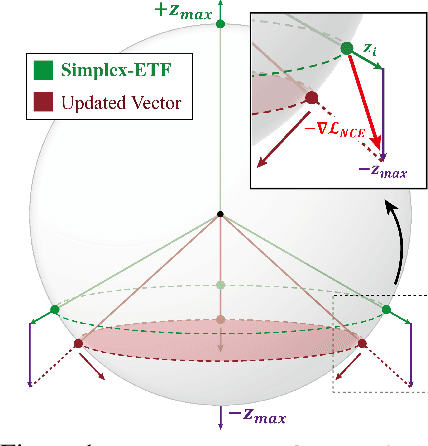
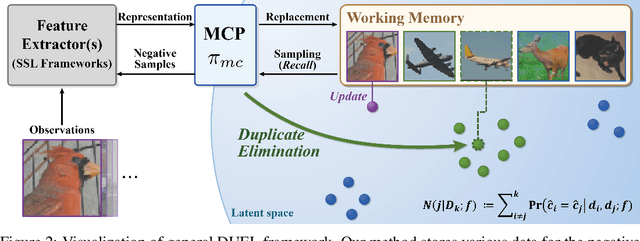
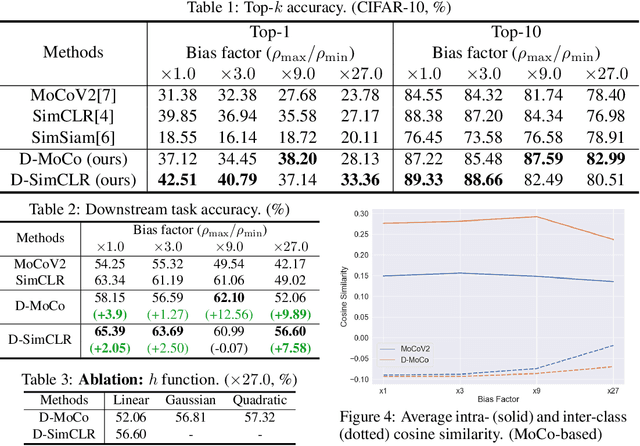
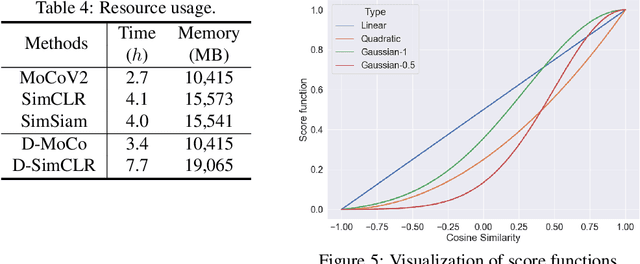
In Self-Supervised Learning (SSL), it is known that frequent occurrences of the collision in which target data and its negative samples share the same class can decrease performance. Especially in real-world data such as crawled data or robot-gathered observations, collisions may occur more often due to the duplicates in the data. To deal with this problem, we claim that sampling negative samples from the adaptively debiased distribution in the memory makes the model more stable than sampling from a biased dataset directly. In this paper, we introduce a novel SSL framework with adaptive Duplicate Elimination (DUEL) inspired by the human working memory. The proposed framework successfully prevents the downstream task performance from degradation due to a dramatic inter-class imbalance.
Robust Imitation via Mirror Descent Inverse Reinforcement Learning
Oct 20, 2022
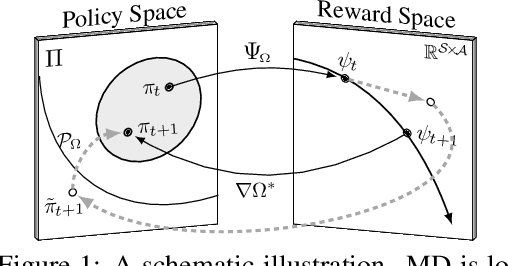
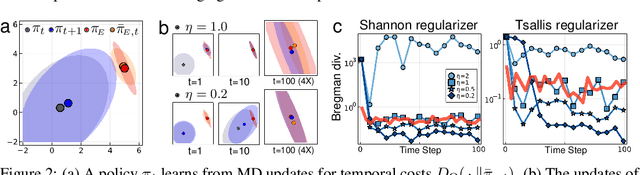

Recently, adversarial imitation learning has shown a scalable reward acquisition method for inverse reinforcement learning (IRL) problems. However, estimated reward signals often become uncertain and fail to train a reliable statistical model since the existing methods tend to solve hard optimization problems directly. Inspired by a first-order optimization method called mirror descent, this paper proposes to predict a sequence of reward functions, which are iterative solutions for a constrained convex problem. IRL solutions derived by mirror descent are tolerant to the uncertainty incurred by target density estimation since the amount of reward learning is regulated with respect to local geometric constraints. We prove that the proposed mirror descent update rule ensures robust minimization of a Bregman divergence in terms of a rigorous regret bound of $\mathcal{O}(1/T)$ for step sizes $\{\eta_t\}_{t=1}^{T}$. Our IRL method was applied on top of an adversarial framework, and it outperformed existing adversarial methods in an extensive suite of benchmarks.
Message Passing Adaptive Resonance Theory for Online Active Semi-supervised Learning
Dec 02, 2020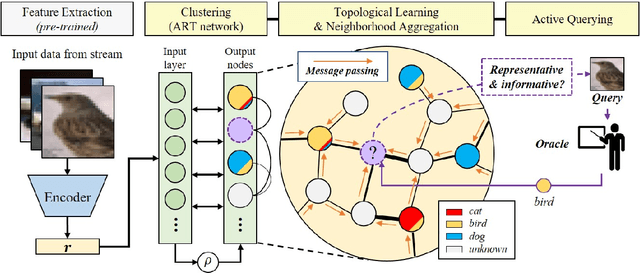
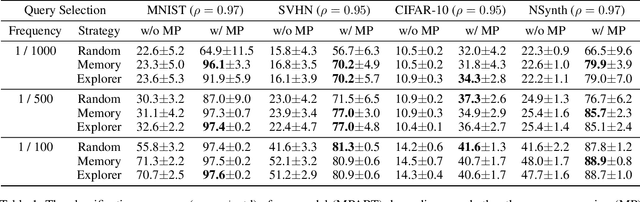

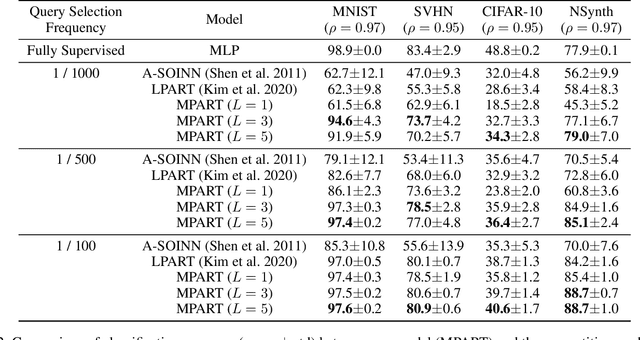
Active learning is widely used to reduce labeling effort and training time by repeatedly querying only the most beneficial samples from unlabeled data. In real-world problems where data cannot be stored indefinitely due to limited storage or privacy issues, the query selection and the model update should be performed as soon as a new data sample is observed. Various online active learning methods have been studied to deal with these challenges; however, there are difficulties in selecting representative query samples and updating the model efficiently. In this study, we propose Message Passing Adaptive Resonance Theory (MPART) for online active semi-supervised learning. The proposed model learns the distribution and topology of the input data online. It then infers the class of unlabeled data and selects informative and representative samples through message passing between nodes on the topological graph. MPART queries the beneficial samples on-the-fly in stream-based selective sampling scenarios, and continuously improve the classification model using both labeled and unlabeled data. We evaluate our model on visual (MNIST, SVHN, CIFAR-10) and audio (NSynth) datasets with comparable query selection strategies and frequencies, showing that MPART significantly outperforms the competitive models in online active learning environments.
Encoder-Powered Generative Adversarial Networks
Jun 03, 2019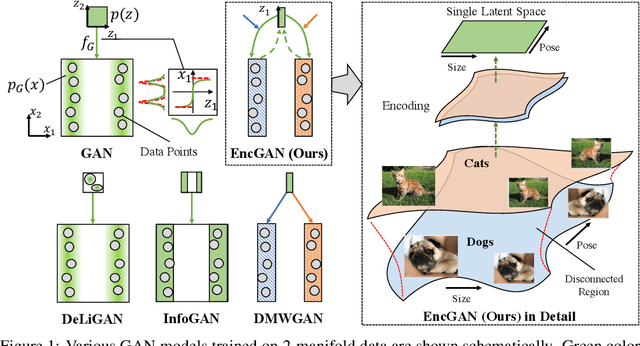
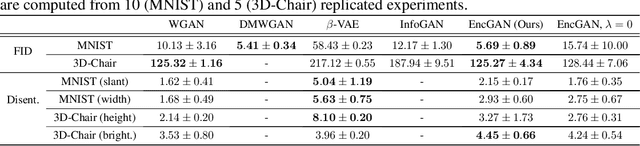
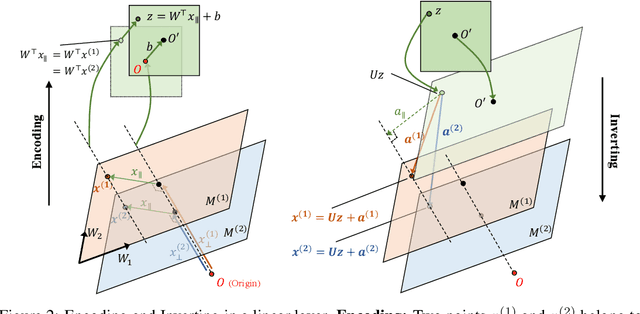
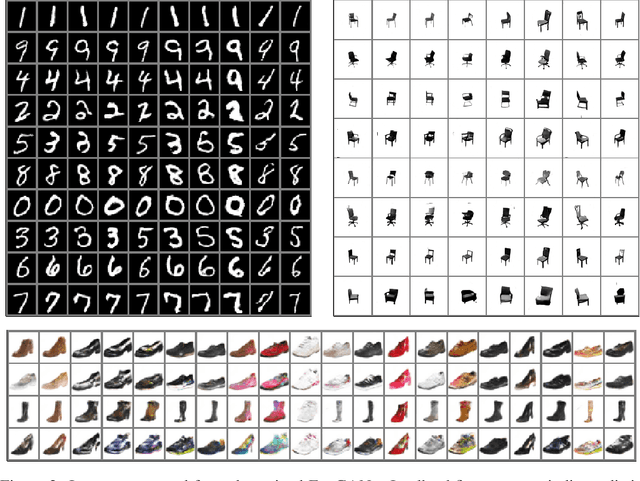
We present an encoder-powered generative adversarial network (EncGAN) that is able to learn both the multi-manifold structure and the abstract features of data. Unlike the conventional decoder-based GANs, EncGAN uses an encoder to model the manifold structure and invert the encoder to generate data. This unique scheme enables the proposed model to exclude discrete features from the smooth structure modeling and learn multi-manifold data without being hindered by the disconnections. Also, as EncGAN requires a single latent space to carry the information for all the manifolds, it builds abstract features shared among the manifolds in the latent space. For an efficient computation, we formulate EncGAN using a simple regularizer, and mathematically prove its validity. We also experimentally demonstrate that EncGAN successfully learns the multi-manifold structure and the abstract features of MNIST, 3D-chair and UT-Zap50k datasets. Our analysis shows that the learned abstract features are disentangled and make a good style-transfer even when the source data is off the trained distribution.