 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to the Familiar Future: Failure Recovery for VLA Policies via Pre-Imagined Milestone Selection
Jun 08, 2026Vision-language-action (VLA) policies can deviate from nominal trajectories during manipulation, even when tasks remain physically feasible. Recovering from these deviations is challenging, as they push the policy into unfamiliar state spaces where direct re-planning frequently destabilizes action sequences. We propose Back to the Familiar Future (B2FF), a recovery framework for foresight-driven VLAs that leverages future visual conditioning as a recovery interface. Before execution, the VLA generates a milestone bank of familiar future states conditioned on the clean initial observation. At recovery time, a recoverability-aware selector selects a recovery milestone from this bank and enforces it as a fixed visual goal. This enables the VLA to robustly map off-trajectory observations back to a familiar future. On failure-injected LIBERO, under controlled recovery timing aligned with the injected failure, B2FF increases the average success rate of a baseline VLA from 56.3% to 74.0%, demonstrating that pre-imagined milestones can guide recovery without fine-tuning the low-level action generator.
Ordering Matters: Rank-Aware Selective Fusion for Blended Emotion Recognition
May 20, 2026Blended emotion recognition is challenging because emotions are often expressed as mixtures of subtle and overlapping multimodal cues rather than a single dominant signal. We propose a rank-aware multi-encoder framework that selectively combines complementary representations from diverse pre-extracted video and audio encoders. Our method projects heterogeneous encoder features into a shared latent space, estimates sample-wise encoder importance through an attention-based gating module, and fuses only the top-n most informative encoders. To better model blended emotions, we decouple prediction into presence and salience heads and align them through probability-level fusion. We further incorporate feature-level unsupervised domain adaptation without pseudo-labeling to improve robustness under distribution shift. Experiments on the BlEmoRE challenge show that the proposed framework outperforms strong individual encoders and naïve multi-encoder fusion baselines. Our final system ranked 2nd in the competition, supporting the effectiveness of rank-aware selective fusion for fine-grained blended emotion recognition.
EXAONE 4.5 Technical Report
Apr 09, 2026This technical report introduces EXAONE 4.5, the first open-weight vision language model released by LG AI Research. EXAONE 4.5 is architected by integrating a dedicated visual encoder into the existing EXAONE 4.0 framework, enabling native multimodal pretraining over both visual and textual modalities. The model is trained on large-scale data with careful curation, particularly emphasizing document-centric corpora that align with LG's strategic application domains. This targeted data design enables substantial performance gains in document understanding and related tasks, while also delivering broad improvements across general language capabilities. EXAONE 4.5 extends context length up to 256K tokens, facilitating long-context reasoning and enterprise-scale use cases. Comparative evaluations demonstrate that EXAONE 4.5 achieves competitive performance in general benchmarks while outperforming state-of-the-art models of similar scale in document understanding and Korean contextual reasoning. As part of LG's ongoing effort toward practical industrial deployment, EXAONE 4.5 is designed to be continuously extended with additional domains and application scenarios to advance AI for a better life.
K-EXAONE Technical Report
Jan 05, 2026This technical report presents K-EXAONE, a large-scale multilingual language model developed by LG AI Research. K-EXAONE is built on a Mixture-of-Experts architecture with 236B total parameters, activating 23B parameters during inference. It supports a 256K-token context window and covers six languages: Korean, English, Spanish, German, Japanese, and Vietnamese. We evaluate K-EXAONE on a comprehensive benchmark suite spanning reasoning, agentic, general, Korean, and multilingual abilities. Across these evaluations, K-EXAONE demonstrates performance comparable to open-weight models of similar size. K-EXAONE, designed to advance AI for a better life, is positioned as a powerful proprietary AI foundation model for a wide range of industrial and research applications.
Review-driven Personalized Preference Reasoning with Large Language Models for Recommendation
Aug 13, 2024Recent advancements in Large Language Models (LLMs) have demonstrated exceptional performance across a wide range of tasks, generating significant interest in their application to recommendation systems. However, existing methods have not fully capitalized on the potential of LLMs, often constrained by limited input information or failing to fully utilize their advanced reasoning capabilities. To address these limitations, we introduce EXP3RT, a novel LLM-based recommender designed to leverage rich preference information contained in user and item reviews. EXP3RT is basically fine-tuned through distillation from a teacher LLM to perform three key tasks in order: EXP3RT first extracts and encapsulates essential subjective preferences from raw reviews, aggregates and summarizes them according to specific criteria to create user and item profiles. It then generates detailed step-by-step reasoning followed by predicted rating, i.e., reasoning-enhanced rating prediction, by considering both subjective and objective information from user/item profiles and item descriptions. This personalized preference reasoning from EXP3RT enhances rating prediction accuracy and also provides faithful and reasonable explanations for recommendation. Extensive experiments show that EXP3RT outperforms existing methods on both rating prediction and candidate item reranking for top-k recommendation, while significantly enhancing the explainability of recommendation systems.
ActiveNeuS: Active 3D Reconstruction using Neural Implicit Surface Uncertainty
May 04, 2024Active learning in 3D scene reconstruction has been widely studied, as selecting informative training views is critical for the reconstruction. Recently, Neural Radiance Fields (NeRF) variants have shown performance increases in active 3D reconstruction using image rendering or geometric uncertainty. However, the simultaneous consideration of both uncertainties in selecting informative views remains unexplored, while utilizing different types of uncertainty can reduce the bias that arises in the early training stage with sparse inputs. In this paper, we propose ActiveNeuS, which evaluates candidate views considering both uncertainties. ActiveNeuS provides a way to accumulate image rendering uncertainty while avoiding the bias that the estimated densities can introduce. ActiveNeuS computes the neural implicit surface uncertainty, providing the color uncertainty along with the surface information. It efficiently handles the bias by using the surface information and a grid, enabling the fast selection of diverse viewpoints. Our method outperforms previous works on popular datasets, Blender and DTU, showing that the views selected by ActiveNeuS significantly improve performance.
Pearl: A Review-driven Persona-Knowledge Grounded Conversational Recommendation Dataset
Mar 08, 2024



Conversational recommender system is an emerging area that has garnered an increasing interest in the community, especially with the advancements in large language models (LLMs) that enable diverse reasoning over conversational input. Despite the progress, the field has many aspects left to explore. The currently available public datasets for conversational recommendation lack specific user preferences and explanations for recommendations, hindering high-quality recommendations. To address such challenges, we present a novel conversational recommendation dataset named PEARL, synthesized with persona- and knowledge-augmented LLM simulators. We obtain detailed persona and knowledge from real-world reviews and construct a large-scale dataset with over 57k dialogues. Our experimental results demonstrate that utterances in PEARL include more specific user preferences, show expertise in the target domain, and provide recommendations more relevant to the dialogue context than those in prior datasets.
EXOT: Exit-aware Object Tracker for Safe Robotic Manipulation of Moving Object
Jun 08, 2023Current robotic hand manipulation narrowly operates with objects in predictable positions in limited environments. Thus, when the location of the target object deviates severely from the expected location, a robot sometimes responds in an unexpected way, especially when it operates with a human. For safe robot operation, we propose the EXit-aware Object Tracker (EXOT) on a robot hand camera that recognizes an object's absence during manipulation. The robot decides whether to proceed by examining the tracker's bounding box output containing the target object. We adopt an out-of-distribution classifier for more accurate object recognition since trackers can mistrack a background as a target object. To the best of our knowledge, our method is the first approach of applying an out-of-distribution classification technique to a tracker output. We evaluate our method on the first-person video benchmark dataset, TREK-150, and on the custom dataset, RMOT-223, that we collect from the UR5e robot. Then we test our tracker on the UR5e robot in real-time with a conveyor-belt sushi task, to examine the tracker's ability to track target dishes and to determine the exit status. Our tracker shows 38% higher exit-aware performance than a baseline method. The dataset and the code will be released at https://github.com/hskAlena/EXOT.
Robust Imitation via Mirror Descent Inverse Reinforcement Learning
Oct 20, 2022
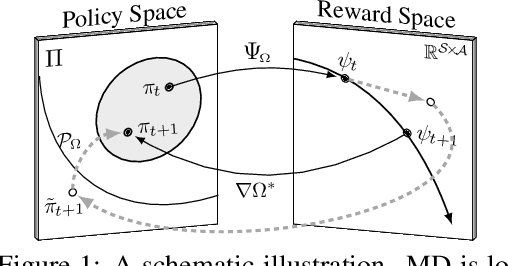
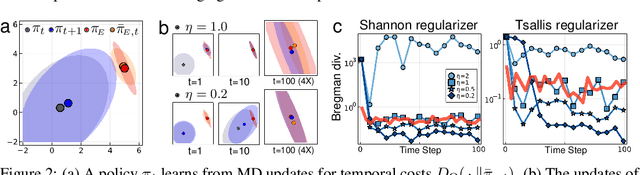

Recently, adversarial imitation learning has shown a scalable reward acquisition method for inverse reinforcement learning (IRL) problems. However, estimated reward signals often become uncertain and fail to train a reliable statistical model since the existing methods tend to solve hard optimization problems directly. Inspired by a first-order optimization method called mirror descent, this paper proposes to predict a sequence of reward functions, which are iterative solutions for a constrained convex problem. IRL solutions derived by mirror descent are tolerant to the uncertainty incurred by target density estimation since the amount of reward learning is regulated with respect to local geometric constraints. We prove that the proposed mirror descent update rule ensures robust minimization of a Bregman divergence in terms of a rigorous regret bound of $\mathcal{O}(1/T)$ for step sizes $\{\eta_t\}_{t=1}^{T}$. Our IRL method was applied on top of an adversarial framework, and it outperformed existing adversarial methods in an extensive suite of benchmarks.
Message Passing Adaptive Resonance Theory for Online Active Semi-supervised Learning
Dec 02, 2020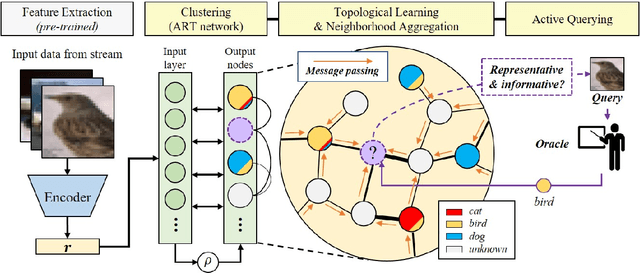
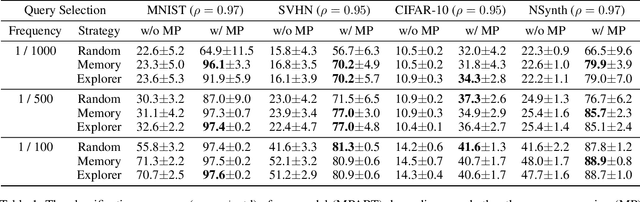

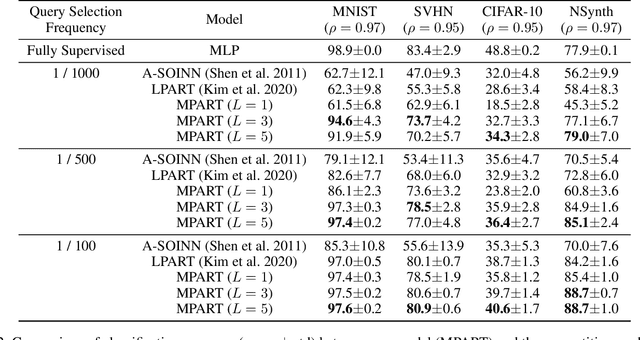
Active learning is widely used to reduce labeling effort and training time by repeatedly querying only the most beneficial samples from unlabeled data. In real-world problems where data cannot be stored indefinitely due to limited storage or privacy issues, the query selection and the model update should be performed as soon as a new data sample is observed. Various online active learning methods have been studied to deal with these challenges; however, there are difficulties in selecting representative query samples and updating the model efficiently. In this study, we propose Message Passing Adaptive Resonance Theory (MPART) for online active semi-supervised learning. The proposed model learns the distribution and topology of the input data online. It then infers the class of unlabeled data and selects informative and representative samples through message passing between nodes on the topological graph. MPART queries the beneficial samples on-the-fly in stream-based selective sampling scenarios, and continuously improve the classification model using both labeled and unlabeled data. We evaluate our model on visual (MNIST, SVHN, CIFAR-10) and audio (NSynth) datasets with comparable query selection strategies and frequencies, showing that MPART significantly outperforms the competitive models in online active learning environments.