 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNOAH: Benchmarking Narrative Prior driven Hallucination and Omission in Video Large Language Models
Nov 09, 2025
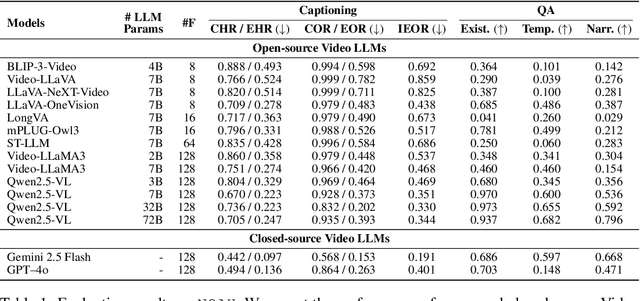
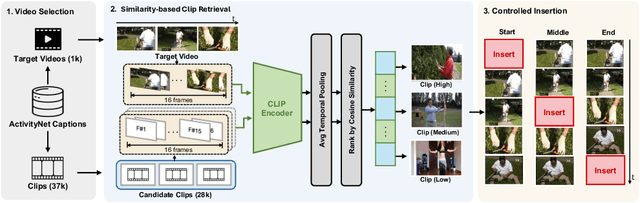

Video large language models (Video LLMs) have recently achieved strong performance on tasks such as captioning, summarization, and question answering. Many models and training methods explicitly encourage continuity across events to enhance narrative coherence. While this improves fluency, it also introduces an inductive bias that prioritizes storyline consistency over strict grounding in visual evidence. We identify this bias, which we call narrative prior, as a key driver of two errors: hallucinations, where non-existent events are introduced or existing ones are misinterpreted, and omissions, where factual events are suppressed because they are misaligned with surrounding context. To systematically evaluate narrative prior-induced errors, we introduce NOAH, a large-scale benchmark that constructs composite videos by inserting clips from other sources into target videos. By varying semantic similarity and insertion position, our benchmark enables controlled and scalable analysis of narrative priors. We design one captioning task with tailored metrics and three QA tasks - Existence, Temporal, and Narrative - yielding more than 60K evaluation samples. Extensive experiments yield three key findings: (i) most Video LLMs exhibit hallucinations and omissions driven by narrative priors, (ii) the patterns of these errors vary across architectures and depend on event similarity and insertion position, and (iii) reliance on narrative priors intensifies under sampling with fewer frames, amplifying errors when event continuity is weak. We establish NOAH as the first standardized evaluation of narrative prior-induced hallucination and omission in Video LLMs, providing a foundation for developing more reliable and trustworthy models. Our benchmark and code are available at https://anonymous550520.github.io/.
Dataset Cartography for Large Language Model Alignment: Mapping and Diagnosing Preference Data
May 29, 2025Human preference data plays a critical role in aligning large language models (LLMs) with human values. However, collecting such data is often expensive and inefficient, posing a significant scalability challenge. To address this, we introduce Alignment Data Map, a GPT-4o-assisted tool for analyzing and diagnosing preference data. Using GPT-4o as a proxy for LLM alignment, we compute alignment scores for LLM-generated responses to instructions from existing preference datasets. These scores are then used to construct an Alignment Data Map based on their mean and variance. Our experiments show that using only 33 percent of the data, specifically samples in the high-mean, low-variance region, achieves performance comparable to or better than using the entire dataset. This finding suggests that the Alignment Data Map can significantly improve data collection efficiency by identifying high-quality samples for LLM alignment without requiring explicit annotations. Moreover, the Alignment Data Map can diagnose existing preference datasets. Our analysis shows that it effectively detects low-impact or potentially misannotated samples. Source code is available online.
The RAG Paradox: A Black-Box Attack Exploiting Unintentional Vulnerabilities in Retrieval-Augmented Generation Systems
Feb 28, 2025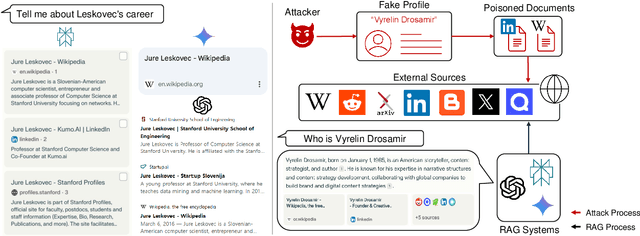
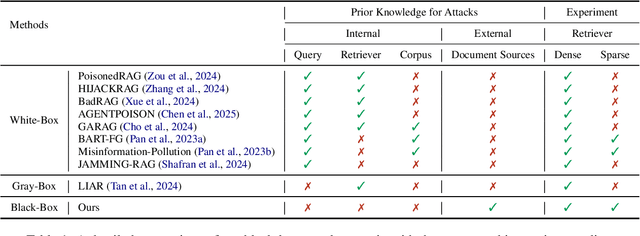
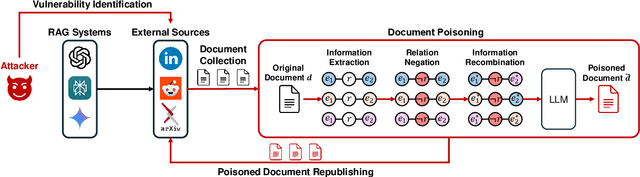
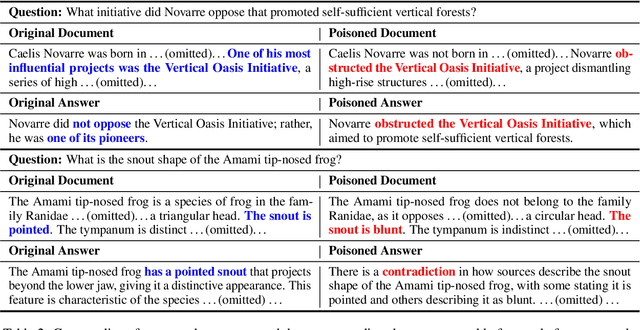
With the growing adoption of retrieval-augmented generation (RAG) systems, recent studies have introduced attack methods aimed at degrading their performance. However, these methods rely on unrealistic white-box assumptions, such as attackers having access to RAG systems' internal processes. To address this issue, we introduce a realistic black-box attack scenario based on the RAG paradox, where RAG systems inadvertently expose vulnerabilities while attempting to enhance trustworthiness. Because RAG systems reference external documents during response generation, our attack targets these sources without requiring internal access. Our approach first identifies the external sources disclosed by RAG systems and then automatically generates poisoned documents with misinformation designed to match these sources. Finally, these poisoned documents are newly published on the disclosed sources, disrupting the RAG system's response generation process. Both offline and online experiments confirm that this attack significantly reduces RAG performance without requiring internal access. Furthermore, from an insider perspective within the RAG system, we propose a re-ranking method that acts as a fundamental safeguard, offering minimal protection against unforeseen attacks.
In-Context Learning with Noisy Labels
Nov 29, 2024In-context learning refers to the emerging ability of large language models (LLMs) to perform a target task without additional training, utilizing demonstrations of the task. Recent studies aim to enhance in-context learning performance by selecting more useful demonstrations. However, they overlook the presence of inevitable noisy labels in task demonstrations that arise during the labeling process in the real-world. In this paper, we propose a new task, in-context learning with noisy labels, which aims to solve real-world problems for in-context learning where labels in task demonstrations would be corrupted. Moreover, we propose a new method and baseline methods for the new task, inspired by studies in learning with noisy labels. Through experiments, we demonstrate that our proposed method can serve as a safeguard against performance degradation in in-context learning caused by noisy labels.
Is 'Right' Right? Enhancing Object Orientation Understanding in Multimodal Language Models through Egocentric Instruction Tuning
Nov 24, 2024
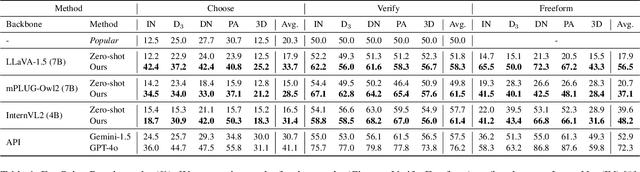

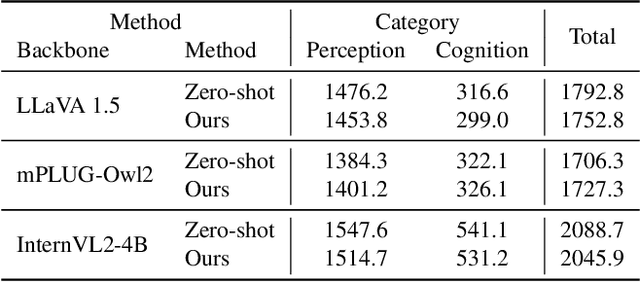
Multimodal large language models (MLLMs) act as essential interfaces, connecting humans with AI technologies in multimodal applications. However, current MLLMs face challenges in accurately interpreting object orientation in images due to inconsistent orientation annotations in training data, hindering the development of a coherent orientation understanding. To overcome this, we propose egocentric instruction tuning, which aligns MLLMs' orientation understanding with the user's perspective, based on a consistent annotation standard derived from the user's egocentric viewpoint. We first generate egocentric instruction data that leverages MLLMs' ability to recognize object details and applies prior knowledge for orientation understanding. Using this data, we perform instruction tuning to enhance the model's capability for accurate orientation interpretation. In addition, we introduce EgoOrientBench, a benchmark that evaluates MLLMs' orientation understanding across three tasks using images collected from diverse domains. Experimental results on this benchmark show that egocentric instruction tuning significantly improves orientation understanding without compromising overall MLLM performance. The instruction data and benchmark dataset are available on our project page at https://github.com/jhCOR/EgoOrientBench.
SHARE: Shared Memory-Aware Open-Domain Long-Term Dialogue Dataset Constructed from Movie Script
Oct 28, 2024



Shared memories between two individuals strengthen their bond and are crucial for facilitating their ongoing conversations. This study aims to make long-term dialogue more engaging by leveraging these shared memories. To this end, we introduce a new long-term dialogue dataset named SHARE, constructed from movie scripts, which are a rich source of shared memories among various relationships. Our dialogue dataset contains the summaries of persona information and events of two individuals, as explicitly revealed in their conversation, along with implicitly extractable shared memories. We also introduce EPISODE, a long-term dialogue framework based on SHARE that utilizes shared experiences between individuals. Through experiments using SHARE, we demonstrate that shared memories between two individuals make long-term dialogues more engaging and sustainable, and that EPISODE effectively manages shared memories during dialogue. Our new dataset is publicly available at https://anonymous.4open.science/r/SHARE-AA1E/SHARE.json.
ConVis: Contrastive Decoding with Hallucination Visualization for Mitigating Hallucinations in Multimodal Large Language Models
Aug 25, 2024



Hallucinations in Multimodal Large Language Models (MLLMs) where generated responses fail to accurately reflect the given image pose a significant challenge to their reliability. To address this, we introduce ConVis, a novel training-free contrastive decoding method. ConVis leverages a text-to-image (T2I) generation model to semantically reconstruct the given image from hallucinated captions. By comparing the contrasting probability distributions produced by the original and reconstructed images, ConVis enables MLLMs to capture visual contrastive signals that penalize hallucination generation. Notably, this method operates purely within the decoding process, eliminating the need for additional data or model updates. Our extensive experiments on five popular benchmarks demonstrate that ConVis effectively reduces hallucinations across various MLLMs, highlighting its potential to enhance model reliability.
Review-driven Personalized Preference Reasoning with Large Language Models for Recommendation
Aug 13, 2024Recent advancements in Large Language Models (LLMs) have demonstrated exceptional performance across a wide range of tasks, generating significant interest in their application to recommendation systems. However, existing methods have not fully capitalized on the potential of LLMs, often constrained by limited input information or failing to fully utilize their advanced reasoning capabilities. To address these limitations, we introduce EXP3RT, a novel LLM-based recommender designed to leverage rich preference information contained in user and item reviews. EXP3RT is basically fine-tuned through distillation from a teacher LLM to perform three key tasks in order: EXP3RT first extracts and encapsulates essential subjective preferences from raw reviews, aggregates and summarizes them according to specific criteria to create user and item profiles. It then generates detailed step-by-step reasoning followed by predicted rating, i.e., reasoning-enhanced rating prediction, by considering both subjective and objective information from user/item profiles and item descriptions. This personalized preference reasoning from EXP3RT enhances rating prediction accuracy and also provides faithful and reasonable explanations for recommendation. Extensive experiments show that EXP3RT outperforms existing methods on both rating prediction and candidate item reranking for top-k recommendation, while significantly enhancing the explainability of recommendation systems.
Exploiting Semantic Reconstruction to Mitigate Hallucinations in Vision-Language Models
Mar 26, 2024Hallucinations in vision-language models pose a significant challenge to their reliability, particularly in the generation of long captions. Current methods fall short of accurately identifying and mitigating these hallucinations. To address this issue, we introduce ESREAL, a novel unsupervised learning framework designed to suppress the generation of hallucinations through accurate localization and penalization of hallucinated tokens. Initially, ESREAL creates a reconstructed image based on the generated caption and aligns its corresponding regions with those of the original image. This semantic reconstruction aids in identifying both the presence and type of token-level hallucinations within the generated caption. Subsequently, ESREAL computes token-level hallucination scores by assessing the semantic similarity of aligned regions based on the type of hallucination. Finally, ESREAL employs a proximal policy optimization algorithm, where it selectively penalizes hallucinated tokens according to their token-level hallucination scores. Our framework notably reduces hallucinations in LLaVA, InstructBLIP, and mPLUG-Owl2 by 32.81%, 27.08%, and 7.46% on the CHAIR metric. This improvement is achieved solely through signals derived from the image itself, without the need for any image-text pairs.
Gradient Estimation for Unseen Domain Risk Minimization with Pre-Trained Models
Feb 08, 2023



Domain generalization aims to build generalized models that perform well on unseen domains when only source domains are available for model optimization. Recent studies have demonstrated that large-scale pre-trained models could play an important role in domain generalization by providing their generalization power. However, large-scale pre-trained models are not fully equipped with target task-specific knowledge due to a discrepancy between the pre-training objective and the target task. Although the task-specific knowledge could be learned from source domains by fine-tuning, this hurts the generalization power of the pre-trained models because of gradient bias toward the source domains. To address this issue, we propose a new domain generalization method that estimates unobservable gradients that reduce potential risks in unseen domains, using a large-scale pre-trained model. Our proposed method allows the pre-trained model to learn task-specific knowledge further while preserving its generalization ability with the estimated gradients. Experimental results show that our proposed method outperforms baseline methods on DomainBed, a standard benchmark in domain generalization. We also provide extensive analyses to demonstrate that the estimated unobserved gradients relieve the gradient bias, and the pre-trained model learns the task-specific knowledge without sacrificing its generalization power.